🚀 🦙 KoLlama2-7b 項目
KoLlama2(韓國大語言模型 Meta AI 2)是一個開源項目,旨在提升基於英文的大語言模型 Llama2 的韓語性能,為韓語用戶帶來更優質的語言交互體驗。
🚀 快速開始
文檔未提及快速開始的相關內容,可參考後續 Llama 2 模型的使用步驟進行初步嘗試。
✨ 主要特性
- 針對性優化:首個 KoLlama2 版本採用高麗大學 NLP & AI 實驗室和 HIAI 研究所公開的韓語指令數據集 kullm-v2 進行 LoRA 微調,專注提升韓語性能。
- 解決韓語困境:針對當前大語言模型訓練數據中韓語佔比極低的問題,致力於探索優化方案,增強韓語用戶對大語言模型豐富能力的體驗。
📦 安裝指南
Llama 2 模型安裝
- 下載模型權重和分詞器:
- 訪問 Meta AI 網站 並接受許可協議。
- 申請獲批後,會通過電子郵件收到簽名 URL。運行
download.sh 腳本,在提示時輸入提供的 URL 開始下載。確保複製的是 URL 文本本身,而不是使用右鍵的“複製鏈接地址”選項。
- 前提條件:確保已安裝
wget 和 md5sum,然後運行腳本:./download.sh。
- 注意:鏈接在 24 小時和一定下載量後會過期,若出現
403: Forbidden 等錯誤,可重新申請鏈接。
- 在 Hugging Face 上獲取訪問權限:
- 需使用與 Hugging Face 賬戶相同的電子郵件地址從 Meta AI 網站申請下載。
- 之後可在 Hugging Face 上申請訪問任何模型,1 - 2 天內賬戶將獲得所有版本的訪問權限。
- 環境設置:
在具有 PyTorch / CUDA 的 conda 環境中,克隆倉庫並在頂級目錄運行:
pip install -e .
💻 使用示例
Llama 2 模型推理
預訓練模型
這些模型未針對聊天或問答進行微調,應設置提示,使預期答案是提示的自然延續。
示例命令(以 llama-2-7b 模型為例,nproc_per_node 需設置為 MP 值):
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir llama-2-7b/ \
--tokenizer_path tokenizer.model \
--max_seq_len 128 --max_batch_size 4
微調聊天模型
微調後的模型針對對話應用進行了訓練,為獲得預期的特性和性能,需要遵循在 chat_completion 中定義的特定格式,包括 INST 和 <<SYS>> 標籤、BOS 和 EOS 標記以及它們之間的空格和換行符(建議對輸入調用 strip() 以避免雙空格)。
示例命令(以 llama-2-7b-chat 模型為例):
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir llama-2-7b-chat/ \
--tokenizer_path tokenizer.model \
--max_seq_len 512 --max_batch_size 4
📚 詳細文檔
韓語大語言模型現狀
從 GPT3 到 Bert 再到 Llama2,大規模語言模型取得了驚人進展,但由於大規模語料庫預訓練的特性,訓練數據中絕大多數是英語,韓語佔比極低。
- GPT3 預訓練數據中韓語比例:0.01697%
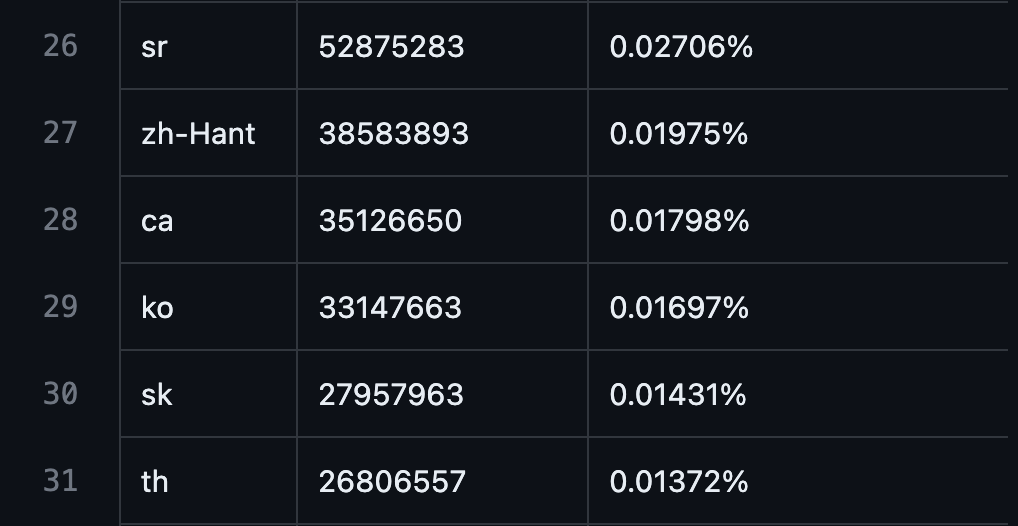 數據來源
數據來源
- Llama2 模型預訓練數據中韓語比例:0.06%
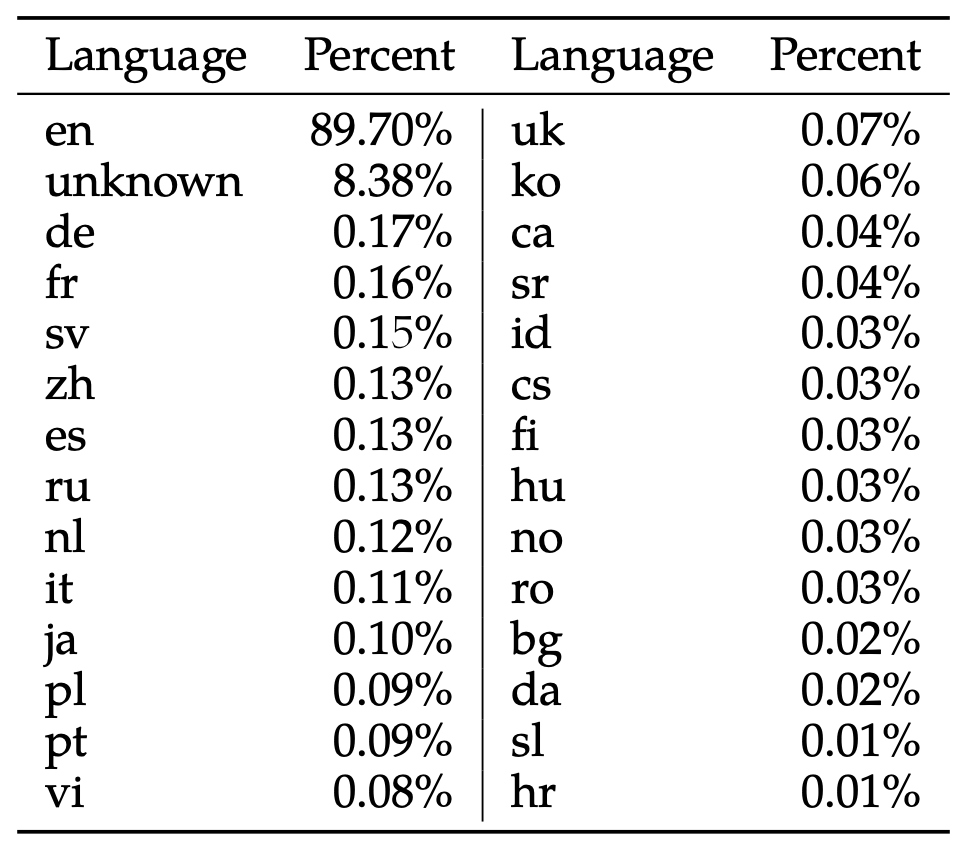 [數據來源](22p Table 10, Llama 2: Open Foundation and Fine-Tuned Chat Models, Hugo Touvron et al, July 18 - 2023.)
[數據來源](22p Table 10, Llama 2: Open Foundation and Fine-Tuned Chat Models, Hugo Touvron et al, July 18 - 2023.)
這一比例遠低於世界人口中韓語使用者的比例(1.035%),多種因素導致韓語用戶在體驗大語言模型豐富能力時受到極大限制。
現有嘗試
基於韓語的 LLM 預訓練
創建使用韓語數據預訓練的自有語言模型是較好的解決方案之一,目前由資金雄厚的大公司主導。
然而,大語言模型的發展變化極快,難以準確預測未來發展方向或每次都針對新變化訓練大規模語言模型,因此需要更輕量、快速的方法。
基於英語的 LLM 微調
將基於外語的 LLM 微調為韓語是解決該問題的不錯方案,基於 LLaMa 模型有以下嘗試:
這些嘗試雖然提高了對開源 LLM 的關注度並有助於理解微調方法,但也存在明顯侷限性:
- LLaMA 模型的預訓練數據中排除了韓語,無論採用全微調、LoRA 還是 QLoRA 等方法,都無法產生令人滿意的韓語性能。
- 缺乏統一的韓語學習評估方法,難以確定哪種學習方法最有效。
- 每個項目由不同實體分散開發,導致重複嘗試。
KoLlama2 項目建議
KoLlama2 項目基於 LLaMA 模型的經驗,旨在尋找將基於英語的 LLM 微調為韓語的最佳方法,為此需要進行以下嘗試:
- 嘗試 QLoRA、LoRA 和全微調等不同方法,觀察 Llama2 中包含的 0.01697% 韓語能力提升情況。
- 應用 Alpaca 和 Vicuna 等各種數據集,確定哪種類型的數據集對提高韓語能力最有效。
- 嘗試新的技術,如從簡單的英韓翻譯逐漸增加難度的課程學習、使用大型韓語語料庫進行額外的預學習步驟以及 Chinese-LLaMA 中使用的詞彙擴展。
- 設計合理的評估方法來評估每種方法。
Llama 2 相關說明
我們正在釋放大語言模型的力量,最新版本的 Llama 現在可供個人、創作者、研究人員和各種規模的企業使用,以便他們能夠負責任地進行實驗、創新和擴展想法。
本次發佈包括預訓練和微調的 Llama 語言模型的模型權重和起始代碼,參數範圍從 7B 到 70B。
本倉庫是加載 Llama 2 模型並運行推理的最小示例。如需使用 Hugging Face 的更詳細示例,請參閱 llama-recipes。
推理注意事項
不同模型需要不同的模型並行(MP)值:
所有模型支持最長 4096 個標記的序列長度,但會根據 max_seq_len 和 max_batch_size 值預先分配緩存,因此請根據硬件設置這些值。
預訓練模型使用說明
這些模型未針對聊天或問答進行微調,應設置提示,使預期答案是提示的自然延續。可參考 example_text_completion.py 中的示例。
微調聊天模型使用說明
微調後的模型針對對話應用進行了訓練,為獲得預期的特性和性能,需要遵循特定格式,包括 INST 和 <<SYS>> 標籤、BOS 和 EOS 標記以及它們之間的空格和換行符(建議對輸入調用 strip() 以避免雙空格)。也可以部署額外的分類器來過濾被認為不安全的輸入和輸出。
風險提示
Llama 2 是一項新技術,使用時可能存在潛在風險。到目前為止進行的測試尚未且不可能涵蓋所有場景。為幫助開發者應對這些風險,我們創建了 《負責任使用指南》,更多詳細信息也可在我們的研究論文中找到。
問題反饋
請通過以下方式報告軟件“漏洞”或模型的其他問題:
模型卡片
請參閱 MODEL_CARD.md。
許可證
我們的模型和權重對研究人員和商業實體均授予許可,秉持開放原則。我們的使命是通過這個機會賦能個人和行業,同時營造探索和道德人工智能進步的環境。
請參閱 LICENSE 文件以及隨附的 《可接受使用政策》。
參考資料
- 研究論文
- Llama 2 技術概述
- 開放創新人工智能研究社區
- 原始 LLaMA 版本的倉庫位於
llama_v1 分支。
🔧 技術細節
文檔未提及具體的技術實現細節內容。
📄 許可證
我們的模型和權重對研究人員和商業實體均授予許可,秉持開放原則。具體請參閱 LICENSE 文件以及隨附的 《可接受使用政策》。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言