🚀 🦙 KoLlama2-7b 项目
KoLlama2(韩国大语言模型 Meta AI 2)是一个开源项目,旨在提升基于英文的大语言模型 Llama2 的韩语性能,为韩语用户带来更优质的语言交互体验。
🚀 快速开始
文档未提及快速开始的相关内容,可参考后续 Llama 2 模型的使用步骤进行初步尝试。
✨ 主要特性
- 针对性优化:首个 KoLlama2 版本采用高丽大学 NLP & AI 实验室和 HIAI 研究所公开的韩语指令数据集 kullm-v2 进行 LoRA 微调,专注提升韩语性能。
- 解决韩语困境:针对当前大语言模型训练数据中韩语占比极低的问题,致力于探索优化方案,增强韩语用户对大语言模型丰富能力的体验。
📦 安装指南
Llama 2 模型安装
- 下载模型权重和分词器:
- 访问 Meta AI 网站 并接受许可协议。
- 申请获批后,会通过电子邮件收到签名 URL。运行
download.sh 脚本,在提示时输入提供的 URL 开始下载。确保复制的是 URL 文本本身,而不是使用右键的“复制链接地址”选项。
- 前提条件:确保已安装
wget 和 md5sum,然后运行脚本:./download.sh。
- 注意:链接在 24 小时和一定下载量后会过期,若出现
403: Forbidden 等错误,可重新申请链接。
- 在 Hugging Face 上获取访问权限:
- 需使用与 Hugging Face 账户相同的电子邮件地址从 Meta AI 网站申请下载。
- 之后可在 Hugging Face 上申请访问任何模型,1 - 2 天内账户将获得所有版本的访问权限。
- 环境设置:
在具有 PyTorch / CUDA 的 conda 环境中,克隆仓库并在顶级目录运行:
pip install -e .
💻 使用示例
Llama 2 模型推理
预训练模型
这些模型未针对聊天或问答进行微调,应设置提示,使预期答案是提示的自然延续。
示例命令(以 llama-2-7b 模型为例,nproc_per_node 需设置为 MP 值):
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir llama-2-7b/ \
--tokenizer_path tokenizer.model \
--max_seq_len 128 --max_batch_size 4
微调聊天模型
微调后的模型针对对话应用进行了训练,为获得预期的特性和性能,需要遵循在 chat_completion 中定义的特定格式,包括 INST 和 <<SYS>> 标签、BOS 和 EOS 标记以及它们之间的空格和换行符(建议对输入调用 strip() 以避免双空格)。
示例命令(以 llama-2-7b-chat 模型为例):
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir llama-2-7b-chat/ \
--tokenizer_path tokenizer.model \
--max_seq_len 512 --max_batch_size 4
📚 详细文档
韩语大语言模型现状
从 GPT3 到 Bert 再到 Llama2,大规模语言模型取得了惊人进展,但由于大规模语料库预训练的特性,训练数据中绝大多数是英语,韩语占比极低。
- GPT3 预训练数据中韩语比例:0.01697%
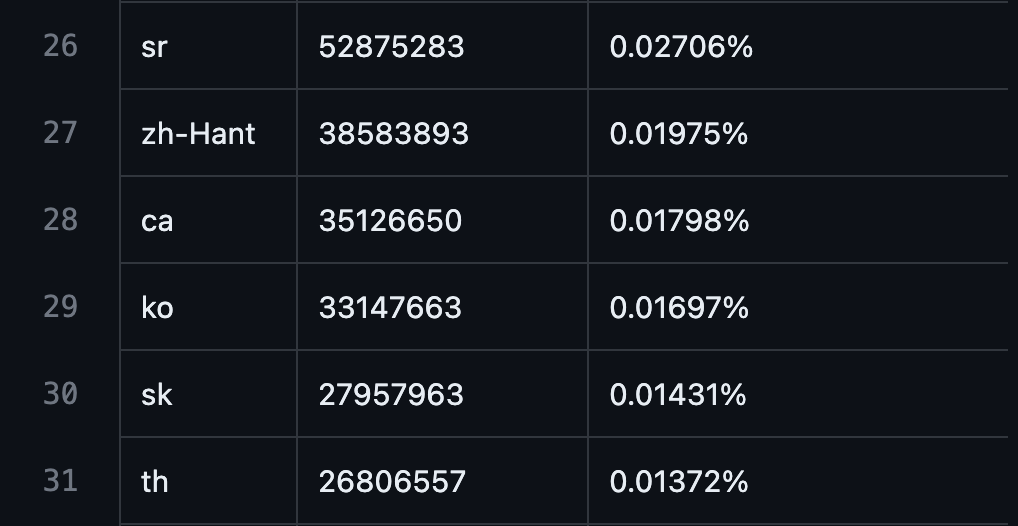 数据来源
数据来源
- Llama2 模型预训练数据中韩语比例:0.06%
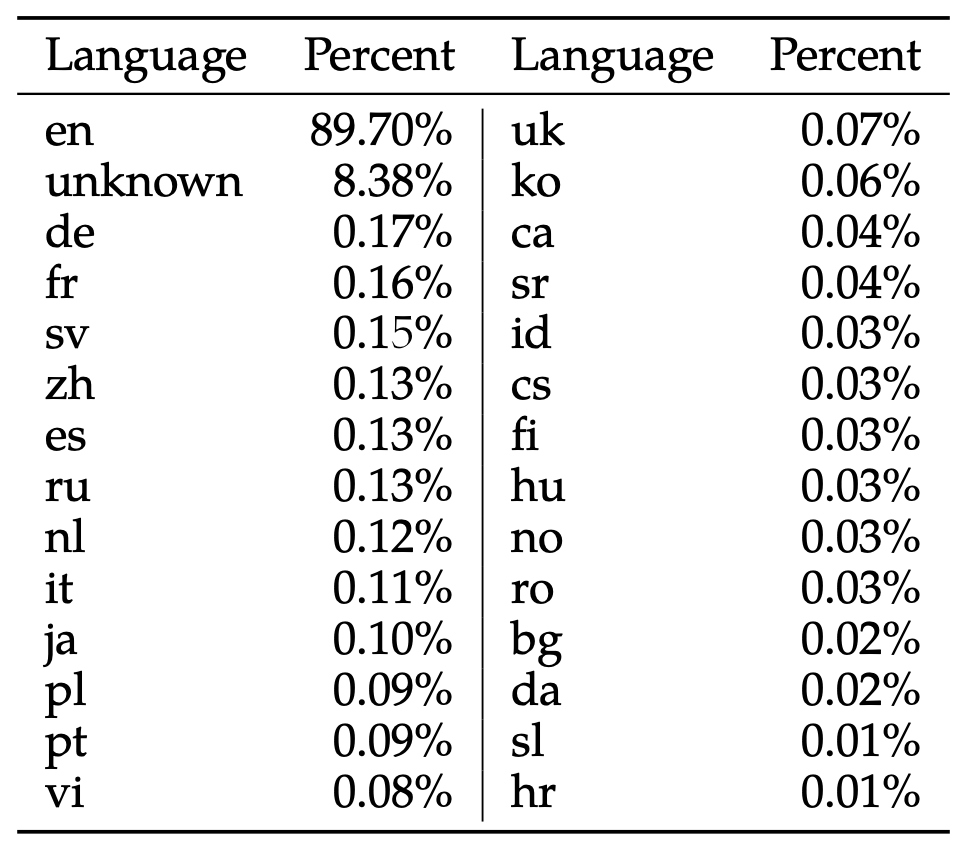 [数据来源](22p Table 10, Llama 2: Open Foundation and Fine-Tuned Chat Models, Hugo Touvron et al, July 18 - 2023.)
[数据来源](22p Table 10, Llama 2: Open Foundation and Fine-Tuned Chat Models, Hugo Touvron et al, July 18 - 2023.)
这一比例远低于世界人口中韩语使用者的比例(1.035%),多种因素导致韩语用户在体验大语言模型丰富能力时受到极大限制。
现有尝试
基于韩语的 LLM 预训练
创建使用韩语数据预训练的自有语言模型是较好的解决方案之一,目前由资金雄厚的大公司主导。
然而,大语言模型的发展变化极快,难以准确预测未来发展方向或每次都针对新变化训练大规模语言模型,因此需要更轻量、快速的方法。
基于英语的 LLM 微调
将基于外语的 LLM 微调为韩语是解决该问题的不错方案,基于 LLaMa 模型有以下尝试:
这些尝试虽然提高了对开源 LLM 的关注度并有助于理解微调方法,但也存在明显局限性:
- LLaMA 模型的预训练数据中排除了韩语,无论采用全微调、LoRA 还是 QLoRA 等方法,都无法产生令人满意的韩语性能。
- 缺乏统一的韩语学习评估方法,难以确定哪种学习方法最有效。
- 每个项目由不同实体分散开发,导致重复尝试。
KoLlama2 项目建议
KoLlama2 项目基于 LLaMA 模型的经验,旨在寻找将基于英语的 LLM 微调为韩语的最佳方法,为此需要进行以下尝试:
- 尝试 QLoRA、LoRA 和全微调等不同方法,观察 Llama2 中包含的 0.01697% 韩语能力提升情况。
- 应用 Alpaca 和 Vicuna 等各种数据集,确定哪种类型的数据集对提高韩语能力最有效。
- 尝试新的技术,如从简单的英韩翻译逐渐增加难度的课程学习、使用大型韩语语料库进行额外的预学习步骤以及 Chinese-LLaMA 中使用的词汇扩展。
- 设计合理的评估方法来评估每种方法。
Llama 2 相关说明
我们正在释放大语言模型的力量,最新版本的 Llama 现在可供个人、创作者、研究人员和各种规模的企业使用,以便他们能够负责任地进行实验、创新和扩展想法。
本次发布包括预训练和微调的 Llama 语言模型的模型权重和起始代码,参数范围从 7B 到 70B。
本仓库是加载 Llama 2 模型并运行推理的最小示例。如需使用 Hugging Face 的更详细示例,请参阅 llama-recipes。
推理注意事项
不同模型需要不同的模型并行(MP)值:
所有模型支持最长 4096 个标记的序列长度,但会根据 max_seq_len 和 max_batch_size 值预先分配缓存,因此请根据硬件设置这些值。
预训练模型使用说明
这些模型未针对聊天或问答进行微调,应设置提示,使预期答案是提示的自然延续。可参考 example_text_completion.py 中的示例。
微调聊天模型使用说明
微调后的模型针对对话应用进行了训练,为获得预期的特性和性能,需要遵循特定格式,包括 INST 和 <<SYS>> 标签、BOS 和 EOS 标记以及它们之间的空格和换行符(建议对输入调用 strip() 以避免双空格)。也可以部署额外的分类器来过滤被认为不安全的输入和输出。
风险提示
Llama 2 是一项新技术,使用时可能存在潜在风险。到目前为止进行的测试尚未且不可能涵盖所有场景。为帮助开发者应对这些风险,我们创建了 《负责任使用指南》,更多详细信息也可在我们的研究论文中找到。
问题反馈
请通过以下方式报告软件“漏洞”或模型的其他问题:
模型卡片
请参阅 MODEL_CARD.md。
许可证
我们的模型和权重对研究人员和商业实体均授予许可,秉持开放原则。我们的使命是通过这个机会赋能个人和行业,同时营造探索和道德人工智能进步的环境。
请参阅 LICENSE 文件以及随附的 《可接受使用政策》。
参考资料
- 研究论文
- Llama 2 技术概述
- 开放创新人工智能研究社区
- 原始 LLaMA 版本的仓库位于
llama_v1 分支。
🔧 技术细节
文档未提及具体的技术实现细节内容。
📄 许可证
我们的模型和权重对研究人员和商业实体均授予许可,秉持开放原则。具体请参阅 LICENSE 文件以及随附的 《可接受使用政策》。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言