🚀 🦙🇰🇷 KoLlama2-7b リポジトリ 🦙🇰🇷
✅ KoLlama2の最初のバージョンは、慶熙大学NLP & AI研究室とHIAI研究所が公開した韓国語命令データセットkullm-v2を使用したLoRAファインチューニングです。
英語版を読む
🚀 クイックスタート
KoLlama2(Korean Large Language Model Meta AI 2)は、英語ベースのLLMであるLlama2の韓国語性能を向上させるためのオープンソースプロジェクトです。
✨ 主な機能
必要性
GPT3からBert、Llama2に至るまで、大規模言語モデルの驚異的な進歩は、皆の注目を集めています。しかし、大規模コーパスで事前学習するLLMの特性上、学習データの大部分は英語で構成されており、韓国語は非常に少ない割合を占めています。
- GPT3の事前学習データ中の韓国語の割合: 0.01697%
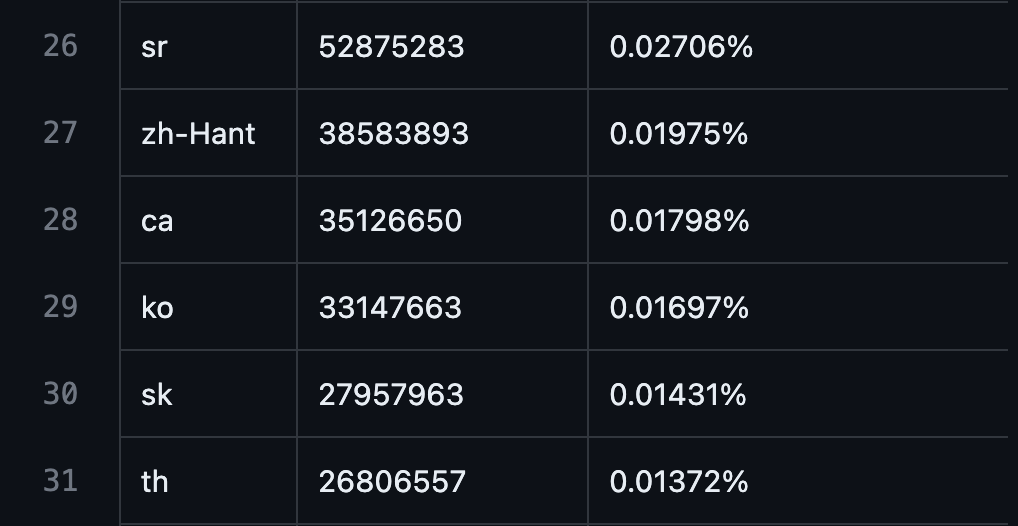
出典: https://github.com/openai/gpt-3/blob/master/dataset_statistics/languages_by_word_count.csv
- Llama2モデルの事前学習データ中の韓国語の割合: 0.06%
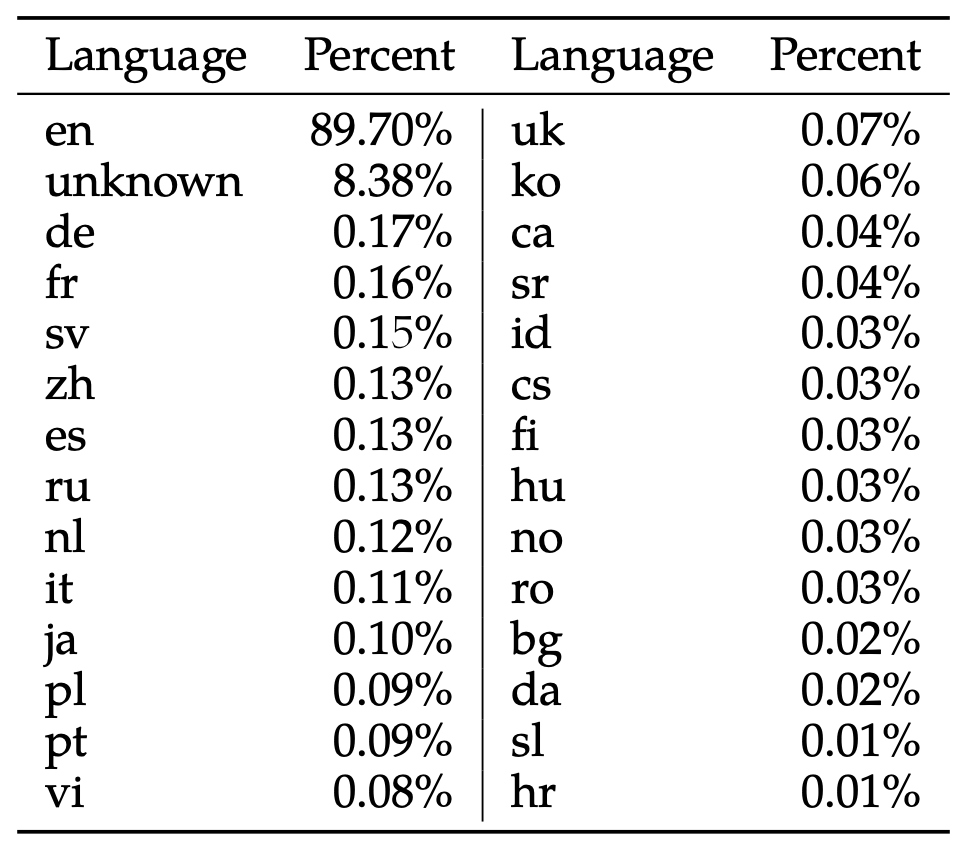
出典: 22p Table 10, Llama 2: Open Foundation and Fine-Tuned Chat Models, Hugo Touvron et al, July 18 - 2023.
この割合は、世界人口(78.88億人)の中の韓国語話者(8170万人)の割合(1.035%)と比較しても大幅に低い数値です。これは、韓国語の孤立語という特性や、準備が不十分な韓国語コーパスなど、さまざまな要因に基づいていますが、結果として、韓国語ユーザーがLLMの豊かな機能を体験することが大きく制限されています。
既存の試み
韓国語ベースのLLM事前学習
最良の解決策の1つは、韓国語データで事前学習した独自の言語モデルを作成することです。このような試みは、資本力のある大企業が主導して進められています。
- NaverのHyperCLOVA X : https://clova.ai/hyperclova
- KakaoのKoGPT : https://github.com/kakaobrain/kogpt
- EleutherAIのpolyglot-ko : https://github.com/EleutherAI/polyglot
このアプローチは、LLMの韓国語能力不足を最も確実に解決することができます。ただし、問題は、LLMの変化速度が非常に速いことです。LLaMAモデルが公開されてからLlama2モデルが公開されるまで、わずか5か月しかかかりませんでした。毎週新しい技術が発表される現状では、将来の発展方向を正確に予測したり、毎回の新しい変化に合わせて大規模言語モデルを学習することは不可能です。
したがって、独自の言語モデルを学習することと並行して、より軽量で迅速な方法が必要です。
外国語ベースのLLM微調整
外国語ベースのLLMを韓国語に微調整することは、この問題に対する良い解決策です。LLaMaモデルをベースに、以下のような試みが行われています。
- KoAlpaca : https://github.com/Beomi/KoAlpaca
- KULLM : https://github.com/nlpai-lab/KULLM
- KoVicuna : https://github.com/melodysdreamj/KoVicuna
- KORani : https://github.com/krafton-ai/KORani
これらの試みは、オープンソースLLMに対する関心を高め、さまざまな微調整方法を理解するのに役立ちましたが、限界も明らかでした。
- LLaMAモデルの場合、事前学習データから韓国語が除外されていたため、Full-Finetuning、LoRA、QLoRAなどどの方法でも、満足できる韓国語性能を出すことができませんでした。
- 韓国語学習の統一された評価方法がなかったため、どの学習方法が最も効果的かを判断することが困難でした。
- 各プロジェクトが個別の主体によって散発的に進められたため、重複した試みが繰り返されました。
KoLlama2プロジェクトの提案
KoLlama2は、LLaMAモデルから得た経験を基に、外国語ベースのLLMを韓国語に微調整する最良の方法を見つけるプロジェクトです。このために、以下のような試みが必要です。
- QLoRA、LoRA、Full-Finetuningなどのさまざまな方法論を試して、Llama2に含まれる0.01697%の韓国語能力がどれだけ向上するかを確認する。
- Alpaca、Vicunaなどのさまざまなデータセットを適用して、どのタイプのデータセットが韓国語能力向上に最も効果的かを確認する。
- 単純な英韓翻訳から徐々に難易度を上げるカリキュラム学習、大規模韓国語コーパスでの事前学習ステップの追加学習、Chinese-LLaMAで使用された語彙拡張などの新しい手法を試す。
- 各方法論を評価する合理的な評価方法を考案する。
📚 ドキュメント
Benchmarks
参考資料
Llama 2
私たちは、大規模言語モデルの力を開放しています。最新バージョンのLlamaは、個人、クリエイター、研究者、あらゆる規模の企業が、責任を持って実験、革新、アイデアを拡大するために利用できるようになりました。
このリリースには、7Bから70Bのパラメータを持つ事前学習および微調整されたLlama言語モデルのモデルウェイトとサンプルコードが含まれています。
このリポジトリは、Llama 2モデルをロードして推論を実行する最小限のサンプルを提供することを目的としています。HuggingFaceを活用したより詳細なサンプルについては、llama-recipesを参照してください。
ダウンロード
⚠️ 重要な注意
7/18: 今日、多くの人がダウンロード問題に遭遇していることを認識しています。まだ問題が解決していない場合は、すべてのローカルファイルを削除し、リポジトリを再クローンし、新しいダウンロードリンクを要求してください。ローカルに破損したファイルがある可能性があるため、これらすべての手順を実行することが重要です。メールを受け取ったら、リンクテキストのみをコピーしてください。https://download.llamameta.netで始まる必要があり、https://l.facebook.comで始まるとエラーが発生します。
モデルウェイトとトークナイザーをダウンロードするには、Meta AIウェブサイトにアクセスし、ライセンスに同意してください。
要求が承認されると、署名付きのURLがメールで送信されます。その後、download.shスクリプトを実行し、ダウンロードを開始するように促されたときに提供されたURLを入力してください。URLテキスト自体をコピーすることを確認してください。URLを右クリックして「リンクのアドレスをコピー」オプションを使用しないでください。コピーしたURLテキストがhttps://download.llamameta.netで始まる場合は、正しくコピーされています。https://l.facebook.comで始まる場合は、誤った方法でコピーされています。
前提条件: wgetとmd5sumがインストールされていることを確認してください。その後、スクリプトを実行するには、./download.shを実行します。
リンクは24時間後と一定のダウンロード回数で期限切れになることに注意してください。403: Forbiddenなどのエラーが表示され始めた場合は、いつでも新しいリンクを要求できます。
Hugging Faceでのアクセス
私たちは、Hugging Faceでもダウンロードを提供しています。まず、Hugging Faceアカウントと同じメールアドレスを使用してMeta AIウェブサイトからダウンロードを要求する必要があります。その後、Hugging Face上の任意のモデルへのアクセスを要求すると、1 - 2日以内にすべてのバージョンへのアクセスが許可されます。
セットアップ
PyTorch / CUDAが利用可能なconda環境で、リポジトリをクローンし、トップレベルディレクトリで以下のコマンドを実行します。
pip install -e .
推論
異なるモデルは、異なるモデル並列(MP)値を必要とします。
すべてのモデルは、最大4096トークンのシーケンス長をサポートしていますが、キャッシュはmax_seq_lenとmax_batch_sizeの値に応じて事前割り当てされます。したがって、ハードウェアに合わせてこれらの値を設定してください。
事前学習モデル
これらのモデルは、チャットやQ&A用に微調整されていません。期待される回答がプロンプトの自然な続きになるように、適切なプロンプトを与える必要があります。
いくつかのサンプルについては、example_text_completion.pyを参照してください。例として、llama-2-7bモデルで実行するためのコマンドを以下に示します(nproc_per_nodeはMP値に設定する必要があります)。
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir llama-2-7b/ \
--tokenizer_path tokenizer.model \
--max_seq_len 128 --max_batch_size 4
微調整されたチャットモデル
微調整されたモデルは、対話アプリケーション用に学習されています。これらのモデルの期待される機能と性能を得るためには、chat_completionで定義された特定のフォーマットに従う必要があります。これには、INSTと<<SYS>>タグ、BOSとEOSトークン、およびそれらの間の空白と改行が含まれます(二重スペースを避けるために、入力にstrip()を呼び出すことをお勧めします)。
また、不適切な入力や出力をフィルタリングするための追加の分類器をデプロイすることもできます。推論コードの入力と出力にセーフティチェッカーを追加する方法のサンプルについては、llama-recipesリポジトリのこの例を参照してください。
llama-2-7b-chatを使用したサンプル:
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir llama-2-7b-chat/ \
--tokenizer_path tokenizer.model \
--max_seq_len 512 --max_batch_size 4
Llama 2は、使用に伴う潜在的なリスクを持つ新しい技術です。これまで行われたテストは、すべてのシナリオを網羅することはできませんでしたし、網羅することもできません。
開発者がこれらのリスクに対処するのを支援するために、責任ある使用ガイドを作成しました。詳細については、研究論文にも記載されています。
問題報告
モデルに関するソフトウェアの「バグ」やその他の問題は、以下のいずれかの方法で報告してください。
モデルカード
MODEL_CARD.mdを参照してください。
📄 ライセンス
私たちのモデルとウェイトは、研究者と商用企業の両方に対して、オープンな原則を守りながらライセンス供与されています。私たちの使命は、この機会を通じて個人や産業界に力を与え、発見と倫理的なAIの進歩の環境を育むことです。
LICENSEファイルと、付属の使用許諾ポリシーを参照してください。
参考文献
- 研究論文
- Llama 2技術概要
- オープンイノベーションAI研究コミュニティ
元のLLaMA
元のllamaリリースのリポジトリは、llama_v1ブランチにあります。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応