🚀 🦙 KoLlama2-7b Repository 🦙
KoLlama2 (Korean Large Language Model Meta AI 2) is an open - source project aimed at enhancing the Korean performance of Llama2, an English - based LLM.
Datasets
Languages
🚀 Quick Start
This section provides a high - level overview of the KoLlama2 project. For more detailed information, please refer to the corresponding sections below.
✨ Features
- Addressing Language Imbalance: KoLlama2 aims to solve the problem of the low proportion of Korean in the pre - training data of large - scale language models, enabling Korean users to better experience the capabilities of LLMs.
- Multiple Approaches: It explores various methods such as different fine - tuning techniques and applying diverse datasets to improve Korean proficiency.
📚 Documentation
Problem
From GPT3 to Bert and Llama2, the remarkable progress of large - scale language models has attracted widespread attention. However, due to the nature of LLMs pre - training on large corpora, most of the training data is in English, and Korean accounts for a very small percentage.
- Percentage of Korean in GPT3's pre - training data: 0.01697%
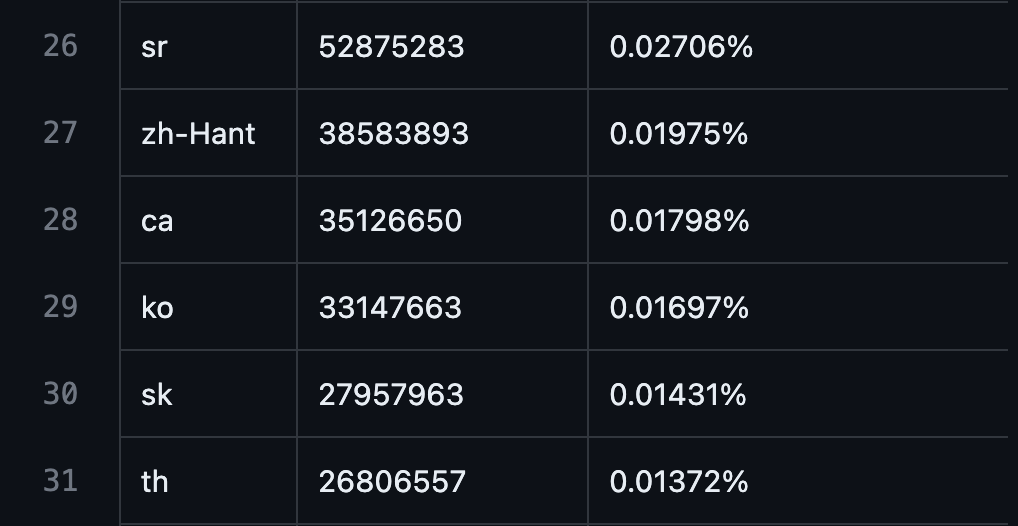
Source: https://github.com/openai/gpt - 3/blob/master/dataset_statistics/languages_by_word_count.csv
- **Percentage of Korean in the Llama2 model's pre - training data**: 0.06%
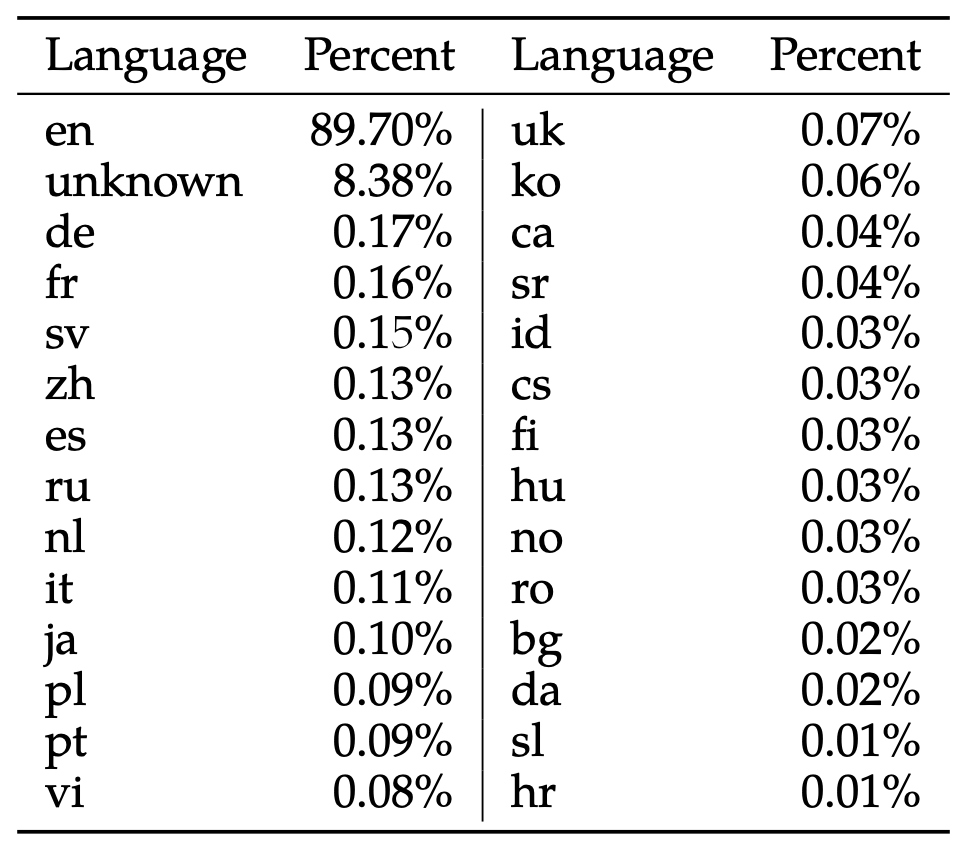
Source: 22p Table 10, Llama 2: Open Foundation and Fine - Tuned Chat Models, Hugo Touvron et al, July 18 - 2023.
This percentage is significantly lower than the proportion of Korean speakers (81.7M) in the world's population (7.888 billion) (1.035%). This is due to multiple factors such as the isolated nature of Korean and the lack of a well - prepared Korean corpus, which severely limits Korean users from fully experiencing the rich capabilities of LLMs.
Problem Statement
Korean - based LLM Pretrain
One of the best solutions is to create a self - developed language model pre - trained with Korean data. This approach is being led by large, well - funded companies.
- Naver HyperCLOVA X: https://clova.ai/hyperclova
- Kakao KoGPT: https://github.com/kakaobrain/kogpt
- EleutherAI polyglot - ko: https://github.com/EleutherAI/polyglot
Although this approach can effectively solve the problem of the lack of Korean proficiency in LLMs, the rapid development of LLMs makes it difficult to accurately predict future trends and train large - scale language models to adapt to every new change. Therefore, we need a lighter and faster method that can be used in parallel with training our own language models.
Fine - tuning a Foreign - language - based LLM
Fine - tuning a foreign - language - based LLM into Korean is a good solution. The following attempts have been made based on the LLaMa model:
- KoAlpaca: https://github.com/Beomi/KoAlpaca
- KULLM: https://github.com/nlpai - lab/KULLM
- KoVicuna: https://github.com/melodysdreamj/KoVicuna
- KORani: https://github.com/krafton - ai/KORani
These attempts have increased interest in open - source LLMs and helped us understand different fine - tuning methods. However, their limitations are also obvious:
- For the LLaMA model, since Korean was excluded from the pre - training data, no method (including Full - Finetuning, LoRA, and QLoRA) could achieve satisfactory Korean performance.
- There was no unified evaluation method for Korean language learning, making it difficult to determine the most effective learning method.
- Each project was developed sporadically by individual entities, resulting in redundant efforts.
KoLlama2 Project Suggested
Based on the experience from the LLaMA model, KoLlama2 aims to find the best way to fine - tune a foreign - language - based LLM into Korean. The following attempts are required:
- Try different methodologies such as QLoRA, LoRA, and Full - Finetuning to evaluate the improvement of the 0.01697% Korean proficiency included in Llama2.
- Apply various datasets such as Alpaca and Vicuna to identify the most effective dataset type for improving Korean proficiency.
- Experiment with new techniques, including curriculum learning that gradually increases the difficulty from simple English - to - Korean translation, additional pre - learning steps with a large Korean corpus, and vocabulary expansion used in Chinese - LLaMA.
- Devise a reasonable evaluation method to assess each methodology.
Benchmarks
This section is yet to be filled with specific benchmarking information.
References
- [Research Paper](https://ai.meta.com/research/publications/llama - 2 - open - foundation - and - fine - tuned - chat - models/)
- [Llama 2 technical overview](https://ai.meta.com/resources/models - and - libraries/llama)
- [Open Innovation AI Research Community](https://ai.meta.com/llama/open - innovation - ai - research - community/)
📦 Installation
Download
⚠️ Important Note
7/18: We're aware that some users are encountering download issues. If you still face problems, please remove all local files, re - clone the repository, and [request a new download link](https://ai.meta.com/resources/models - and - libraries/llama - downloads/). It's crucial to do this in case you have local corrupt files. When you receive the email, copy only the link text (it should start with https://download.llamameta.net, not https://l.facebook.com, as the latter will cause errors).
To download the model weights and tokenizer, visit the [Meta AI website](https://ai.meta.com/resources/models - and - libraries/llama - downloads/) and accept the License. Once your request is approved, you will receive a signed URL via email. Then run the download.sh script and enter the provided URL when prompted to start the download. Make sure to copy the URL text directly, do not use the 'Copy link address' option when right - clicking the URL. If the copied URL starts with https://download.llamameta.net, you've copied it correctly. If it starts with https://l.facebook.com, the copy is incorrect.
Pre - requisites: Ensure that wget and md5sum are installed. Then run the script: ./download.sh.
Note that the links expire after 24 hours and a certain number of downloads. If you encounter errors like 403: Forbidden, you can request a new link.
Access on Hugging Face
You can also download from [Hugging Face](https://huggingface.co/meta - llama). First, request a download from the Meta AI website using the same email as your Hugging Face account. After that, you can request access to any of the models on Hugging Face, and your account will be granted access to all versions within 1 - 2 days.
Setup
In a conda environment with PyTorch / CUDA available, clone the repository and run the following command in the top - level directory:
pip install -e .
💻 Usage Examples
Inference
Different models require different model - parallel (MP) values:
| Model |
MP |
| 7B |
1 |
| 13B |
2 |
| 70B |
8 |
All models support a sequence length of up to 4096 tokens. However, the cache is pre - allocated according to the max_seq_len and max_batch_size values. So, set these values according to your hardware.
Pretrained Models
These models are not fine - tuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt.
See example_text_completion.py for examples. To run it with the llama - 2 - 7b model (nproc_per_node needs to be set to the MP value):
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir llama - 2 - 7b/ \
--tokenizer_path tokenizer.model \
--max_seq_len 128 --max_batch_size 4
Fine - tuned Chat Models
The fine - tuned models are trained for dialogue applications. To achieve the expected features and performance, a specific formatting defined in chat_completion must be followed, including the INST and <<SYS>> tags, BOS and EOS tokens, and the appropriate whitespaces and breaklines (we recommend calling strip() on inputs to avoid double - spaces).
You can also deploy additional classifiers to filter out unsafe inputs and outputs. See the llama - recipes repo for [an example](https://github.com/facebookresearch/llama - recipes/blob/main/inference/inference.py) of adding a safety checker to the inputs and outputs of your inference code.
Example of using llama - 2 - 7b - chat:
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir llama - 2 - 7b - chat/ \
--tokenizer_path tokenizer.model \
--max_seq_len 512 --max_batch_size 4
🔧 Technical Details
Llama 2 is a new technology that carries potential risks with use. Testing conducted to date has not — and could not — cover all scenarios. To help developers address these risks, we have created the [Responsible Use Guide](Responsible - Use - Guide.pdf). More details can be found in our research paper.
📄 License
Our model and weights are licensed for both researchers and commercial entities, adhering to the principles of openness. Our mission is to empower individuals and the industry through this opportunity while promoting an environment of discovery and ethical AI advancements. See the LICENSE file, as well as our accompanying Acceptable Use Policy.
Original LLaMA
The repository for the original llama release is in the llama_v1 branch.
Issues
Please report any software “bug,” or other problems with the models through one of the following means:
Model Card
See MODEL_CARD.md.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers Supports Multiple Languages#Korean optimization#LoRA fine-tuning#Multilingual support
Transformers Supports Multiple Languages#Korean optimization#LoRA fine-tuning#Multilingual support