🚀 Spec-T1-RL-7B
Spec-T1-RL-7B 是一款高精度的數學與算法推理模型,在數學推理、算法問題解決和代碼生成等領域表現卓越,能為相關技術研究和應用提供強大支持。

📄 模型卡片
| 屬性 |
詳情 |
| 開發者 |
SVECTOR |
| 模型大小 |
70 億參數 |
| 上下文長度 |
32,000 個詞元 |
| 訓練數據 |
專注於推理的數據集,包含數學、邏輯和代碼內容 |
| 精度 |
bfloat16, float16 |
| 許可證 |
MIT |
| 發佈日期 |
2025 年 5 月 |
🌟 模型概述
Spec-T1-RL-7B 是一款專門設計的大語言模型,旨在數學推理、算法問題解決和實際代碼生成方面表現出色。與通用模型不同,Spec-T1 在架構設計和訓練過程中特別針對需要精確邏輯思維的領域進行了優化。
該模型在 70 億參數規模下,推理能力有了顯著提升,在技術基準測試中超越了許多更大規模的模型,同時保持了高效的部署要求。
✨ 主要特性
- 數學推理:通過逐步的邏輯推導解決複雜的數學問題。
- 算法問題解決:在多個領域設計和分析算法。
- 代碼生成:生成功能完善、高質量的代碼,測試通過率高。
- 精確指令遵循:準確響應結構化的技術提示。
- 符號驗證:使用內置的驗證機制進行數學和邏輯驗證。
🏗️ 模型架構
Spec-T1-RL-7B 結合了多種架構創新,以實現其專門的推理能力:
- 基礎架構:具有優化注意力機制的先進變壓器架構。
- 專家混合(MoE):輕量級條件計算,實現高效擴展。
- 激活函數:SwiGLU 激活函數,改善數學運算中的梯度流。
- 歸一化:RMSNorm,在推理任務中實現更快的收斂和穩定性。
📈 訓練方法
我們的模型經過了三個階段的訓練過程,旨在優化推理能力:
1️⃣ 推理感知預訓練
- 專業語料庫:高度強調數學符號、邏輯語法和代碼。
- 課程學習方法:優先處理結構化推理模式。
- 自定義分詞器:針對數學和編程語法進行優化。
2️⃣ 指令微調
- 400K+ 多領域結構化提示:專注於推理任務。
- 結合 CodeInstruct 方法和 ThoughtChain 提示。
- 合成數據生成:帶有驗證反饋循環。
3️⃣ 強化學習對齊
- 獎勵建模:使用確定性的通過/失敗信號來評估數學和代碼的正確性。
- 單元測試集成:即時驗證生成的解決方案。
- 符號驗證:對數學證明和推導進行驗證。
📊 基準測試性能
Spec-T1-RL-7B 模型在推理基準測試中表現出色,特別是在數學和代碼生成任務中:
通用推理
| 基準測試 |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
| GPQA Diamond (Pass@1) |
49.9 |
65.0 |
60.0 |
54.5 |
65.1 |
| SuperGPQA (Pass@1) |
42.4 |
48.2 |
45.2 |
43.6 |
52.8 |
| DROP (3-shot F1) |
83.7 |
88.3 |
83.9 |
71.2 |
86.2 |
| MMLU-Pro (EM) |
72.6 |
78.0 |
80.3 |
52.0 |
76.4 |
| IF-Eval (Prompt Strict) |
84.3 |
86.5 |
84.8 |
40.4 |
83.3 |
數學基準測試
數學
| 基準測試 |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
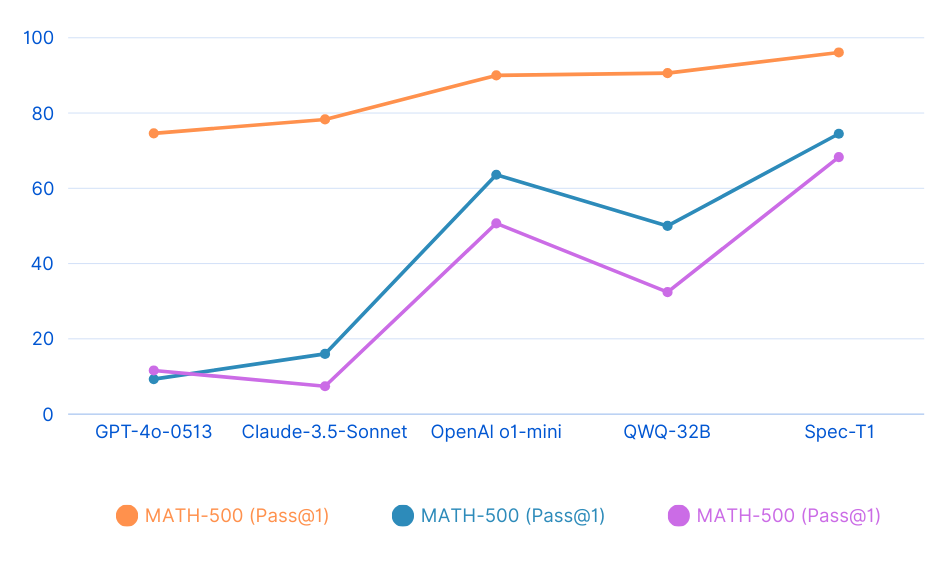
| MATH-500 (Pass@1) |
74.6 |
78.3 |
90.0 |
90.6 |
96.1 |
| AIME 2024 (Pass@1) |
9.3 |
16.0 |
63.6 |
50.0 |
74.5 |
| AIME 2025 (Pass@1) |
11.6 |
7.4 |
50.7 |
32.4 |
68.3 |
代碼生成
| 基準測試 |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
| LiveCodeBench v5 (Pass@1) |
32.9 |
38.9 |
53.8 |
41.9 |
60.2 |
| LiveCodeBench v6 (Pass@1) |
30.9 |
37.2 |
46.8 |
39.1 |
54.4 |
💻 使用示例
基礎用法(使用 Transformers)
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("SVECTOR-CORPORATION/Spec-T1-RL-7B")
tokenizer = AutoTokenizer.from_pretrained("SVECTOR-CORPORATION/Spec-T1-RL-7B")
prompt = """
Prove: The sum of the first n odd numbers is n^2.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
高級用法(使用生成參數)
prompt = """
Design an efficient algorithm to find the longest increasing subsequence in an array of integers.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs,
max_new_tokens=1024,
temperature=0.1,
top_p=0.95,
do_sample=True,
num_return_sequences=1,
repetition_penalty=1.1
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
代碼生成示例
prompt = """
Write a Python function that implements the A* search algorithm for pathfinding.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs,
max_new_tokens=2048,
temperature=0.2,
top_p=0.9,
do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
🚀 部署
由於其高效的架構和參數數量,Spec-T1-RL-7B 可以部署在消費級硬件上:
最低要求
- 16GB 顯存(bfloat16/float16)
- 32GB 系統內存
- 支持 CUDA 的 GPU
推薦配置
- 24GB 以上顯存,以獲得最佳性能
- 64GB 以上系統內存,用於長上下文應用
- NVIDIA A10 或更高版本
📝 引用
如果您在研究中使用了 Spec-T1-RL-7B,請引用:
@misc{svector2025spect1,
title={Spec-T1-RL-7B: Structured Reasoning through Reinforcement Alignment},
author={SVECTOR Team},
year={2025},
}
📄 許可證
Spec-T1-RL-7B 採用 MIT 許可證發佈。
📞 聯繫我們
如有問題、反饋或合作諮詢,請聯繫:
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

{kind=link}
 Transformers 支持多種語言
Transformers 支持多種語言