🚀 Spec-T1-RL-7B
高精度な数学的およびアルゴリズム的推論モデルです。このモデルは、数学的推論、アルゴリズムの問題解決、実世界のコード生成に特化しており、専門分野での高精度なロジック思考に最適化されています。

📋 モデルカード
| プロパティ |
詳細 |
| 開発者 |
SVECTOR |
| モデルサイズ |
70億パラメータ |
| コンテキスト長 |
32,000トークン |
| 学習データ |
数学、論理、コード内容を中心とした推論に特化したデータセット |
| 精度 |
bfloat16, float16 |
| ライセンス |
MIT |
| リリース日 |
2025年5月 |
🌟 モデル概要
Spec-T1-RL-7Bは、数学的推論、アルゴリズムの問題解決、実世界のコード生成において卓越した性能を発揮するように設計された特殊な大規模言語モデルです。汎用モデルとは異なり、Spec-T1は正確な論理的思考を必要とする分野で優れた性能を発揮するようにアーキテクチャが設計され、学習されています。このモデルは、70億パラメータ規模での特殊な推論能力において大きな進歩を示しており、技術的なベンチマークでははるかに大きなモデルを上回り、効率的なデプロイメント要件を維持しています。
✨ 主な機能
- 数学的推論: 複雑な数学問題を段階的な論理的推論で解くことができます。
- アルゴリズムの問題解決: 複数のドメインにわたるアルゴリズムの設計と分析が可能です。
- コード生成: 機能的で高品質なコードを生成し、高いテスト合格率を達成します。
- 正確な指示に従う: 構造化された技術的なプロンプトに正確に応答します。
- 記号的検証: 数学と論理のための組み込み検証メカニズムを使用します。
🏗️ モデルアーキテクチャ
Spec-T1-RL-7Bは、特殊な推論能力を実現するためにいくつかのアーキテクチャ上の革新を組み合わせています。
- 基礎: 最適化されたアテンションメカニズムを備えた高度なトランスフォーマーアーキテクチャ
- エキスパート混合 (MoE): 効率的なスケーリングのための軽量な条件付き計算
- 活性化関数: 数学演算における勾配の流れを改善するためのSwiGLU活性化関数
- 正規化: 推論タスクにおけるより速い収束と安定性のためのRMSNorm
📈 学習方法
当社のモデルは、推論能力を最適化するために3段階の学習プロセスを経ています。
1段階: 推論意識のある事前学習
- 数学的表記、論理的構文、コードに重点を置いた特殊なコーパス
- 構造化された推論パターンを優先するカリキュラム学習アプローチ
- 数学とプログラミング構文に最適化されたカスタムトークナイザー
2段階: 命令微調整
- 推論タスクに焦点を当てた40万以上のマルチドメイン、構造化されたプロンプト
- ThoughtChainプロンプトと組み合わせたCodeInstruct方法論
- 検証フィードバックループを備えた合成データ生成
3段階: 強化学習アライメント
- 数学とコードの正確性のための決定論的な合格/不合格信号を使用した報酬モデリング
- 生成された解のリアルタイム検証のための単体テスト統合
- 数学的証明と導出の記号的検証
📊 ベンチマーク性能
Spec-T1-RL-7Bモデルは、推論ベンチマーク全体で卓越した性能を示しており、特に数学とコード生成タスクで顕著です。
一般的な推論
| ベンチマーク |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
| GPQA Diamond (Pass@1) |
49.9 |
65.0 |
60.0 |
54.5 |
65.1 |
| SuperGPQA (Pass@1) |
42.4 |
48.2 |
45.2 |
43.6 |
52.8 |
| DROP (3-shot F1) |
83.7 |
88.3 |
83.9 |
71.2 |
86.2 |
| MMLU-Pro (EM) |
72.6 |
78.0 |
80.3 |
52.0 |
76.4 |
| IF-Eval (Prompt Strict) |
84.3 |
86.5 |
84.8 |
40.4 |
83.3 |
数学ベンチマーク
数学
| ベンチマーク |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
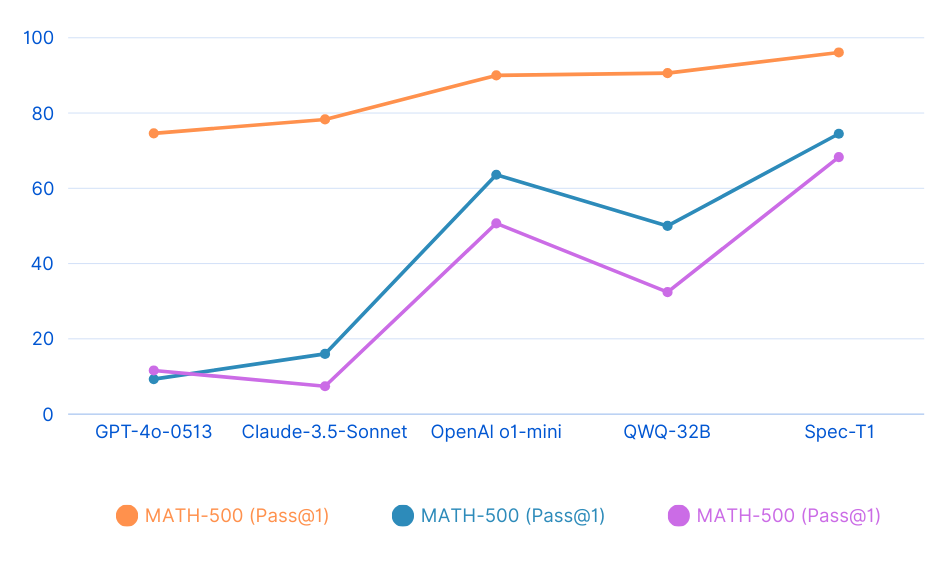
| MATH-500 (Pass@1) |
74.6 |
78.3 |
90.0 |
90.6 |
96.1 |
| AIME 2024 (Pass@1) |
9.3 |
16.0 |
63.6 |
50.0 |
74.5 |
| AIME 2025 (Pass@1) |
11.6 |
7.4 |
50.7 |
32.4 |
68.3 |
コード生成
| ベンチマーク |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
| LiveCodeBench v5 (Pass@1) |
32.9 |
38.9 |
53.8 |
41.9 |
60.2 |
| LiveCodeBench v6 (Pass@1) |
30.9 |
37.2 |
46.8 |
39.1 |
54.4 |
💻 使用例
基本的な使用法 (Transformersを使用)
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("SVECTOR-CORPORATION/Spec-T1-RL-7B")
tokenizer = AutoTokenizer.from_pretrained("SVECTOR-CORPORATION/Spec-T1-RL-7B")
prompt = """
Prove: The sum of the first n odd numbers is n^2.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
高度な使用法 (生成パラメータを使用)
prompt = """
Design an efficient algorithm to find the longest increasing subsequence in an array of integers.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs,
max_new_tokens=1024,
temperature=0.1,
top_p=0.95,
do_sample=True,
num_return_sequences=1,
repetition_penalty=1.1
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
コード生成の例
prompt = """
Write a Python function that implements the A* search algorithm for pathfinding.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs,
max_new_tokens=2048,
temperature=0.2,
top_p=0.9,
do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
🚀 デプロイメント
Spec-T1-RL-7Bは、効率的なアーキテクチャとパラメータ数のため、一般的なハードウェアでのデプロイが可能です。
最小要件
- 16GB VRAM (bfloat16/float16)
- 32GBシステムRAM
- CUDA対応GPU
推奨構成
- 最適なパフォーマンスのために24GB以上のVRAM
- 長いコンテキストアプリケーションのために64GB以上のシステムRAM
- NVIDIA A10以上
📚 引用
もしあなたが研究でSpec-T1-RL-7Bを使用する場合は、以下を引用してください。
@misc{svector2025spect1,
title={Spec-T1-RL-7B: Structured Reasoning through Reinforcement Alignment},
author={SVECTOR Team},
year={2025},
}
📄 ライセンス
Spec-T1-RL-7BはMITライセンスの下でリリースされています。
📞 連絡先
質問、フィードバック、または協力に関する問い合わせは、以下の方法でお問い合わせください。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

{kind=link}
 Transformers 複数言語対応
Transformers 複数言語対応