🚀 Spec-T1-RL-7B
A high-precision mathematical and algorithmic reasoning model that offers exceptional performance in specialized domains.

📚 Documentation
Model Card
| Property |
Details |
| Developer |
SVECTOR |
| Model Size |
7 billion parameters |
| Context Length |
32,000 tokens |
| Training Data |
Reasoning-focused datasets with mathematical, logical, and code content |
| Precision |
bfloat16, float16 |
| License |
MIT |
| Release Date |
May 2025 |
Model Overview
Spec-T1-RL-7B is a specialized large language model engineered for exceptional performance in mathematical reasoning, algorithmic problem-solving, and real-world code generation. Unlike general-purpose models, Spec-T1 has been architecturally designed and trained specifically to excel in domains requiring precise, logical thinking. The model represents a significant advancement in specialized reasoning capabilities at the 7B parameter scale, outperforming much larger models on technical benchmarks while maintaining efficient deployment requirements.
Features
- Mathematical Reasoning: Solves complex math problems with step-by-step logical deduction.
- Algorithmic Problem-Solving: Designs and analyzes algorithms across multiple domains.
- Code Generation: Produces functional, high-quality code with strong test pass rates.
- Precise Instruction Following: Responds accurately to structured technical prompts.
- Symbolic Verification: Uses built-in verification mechanisms for mathematics and logic.
Technical Details
Model Architecture
Spec-T1-RL-7B combines several architectural innovations to achieve its specialized reasoning capabilities:
- Foundation: Advanced transformer architecture with optimized attention mechanisms.
- Mixture-of-Experts (MoE): Lightweight conditional computation for efficient scaling.
- Activations: SwiGLU activations for improved gradient flow in mathematical operations.
- Normalization: RMSNorm for faster convergence and stability in reasoning tasks.
Training Methodology
Our model underwent a three-phase training process designed to optimize reasoning capabilities:
Reasoning-Aware Pretraining
- Specialized corpus with heavy emphasis on mathematical notation, logical syntax, and code.
- Curriculum learning approach prioritizing structured reasoning patterns.
- Custom tokenizer optimized for mathematical and programming syntax.
Instruction Fine-Tuning
- 400K+ multi-domain, structured prompts focused on reasoning tasks.
- Combined CodeInstruct methodology with ThoughtChain prompting.
- Synthetic data generation with verification feedback loops.
Reinforcement Learning Alignment
- Reward modeling using deterministic pass/fail signals for math and code correctness.
- Unit test integration for real-time verification of generated solutions.
- Symbolic verification of mathematical proofs and derivations.
Benchmark Performance
The Spec-T1-RL-7B model demonstrates exceptional performance across reasoning benchmarks, particularly in mathematics and code generation tasks:
General Reasoning
| Benchmark |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
| GPQA Diamond (Pass@1) |
49.9 |
65.0 |
60.0 |
54.5 |
65.1 |
| SuperGPQA (Pass@1) |
42.4 |
48.2 |
45.2 |
43.6 |
52.8 |
| DROP (3-shot F1) |
83.7 |
88.3 |
83.9 |
71.2 |
86.2 |
| MMLU-Pro (EM) |
72.6 |
78.0 |
80.3 |
52.0 |
76.4 |
| IF-Eval (Prompt Strict) |
84.3 |
86.5 |
84.8 |
40.4 |
83.3 |
Math Benchmarks
Mathematics
| Benchmark |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
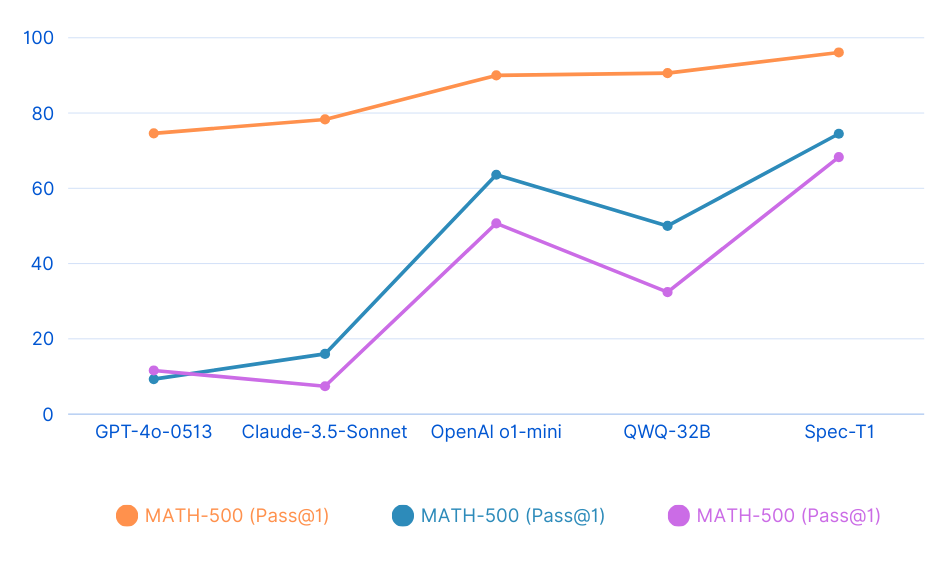
| MATH-500 (Pass@1) |
74.6 |
78.3 |
90.0 |
90.6 |
96.1 |
| AIME 2024 (Pass@1) |
9.3 |
16.0 |
63.6 |
50.0 |
74.5 |
| AIME 2025 (Pass@1) |
11.6 |
7.4 |
50.7 |
32.4 |
68.3 |
Code Generation
| Benchmark |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
| LiveCodeBench v5 (Pass@1) |
32.9 |
38.9 |
53.8 |
41.9 |
60.2 |
| LiveCodeBench v6 (Pass@1) |
30.9 |
37.2 |
46.8 |
39.1 |
54.4 |
💻 Usage Examples
Basic Usage
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("SVECTOR-CORPORATION/Spec-T1-RL-7B")
tokenizer = AutoTokenizer.from_pretrained("SVECTOR-CORPORATION/Spec-T1-RL-7B")
prompt = """
Prove: The sum of the first n odd numbers is n^2.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Advanced Usage with Generation Parameters
prompt = """
Design an efficient algorithm to find the longest increasing subsequence in an array of integers.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs,
max_new_tokens=1024,
temperature=0.1,
top_p=0.95,
do_sample=True,
num_return_sequences=1,
repetition_penalty=1.1
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Code Generation Example
prompt = """
Write a Python function that implements the A* search algorithm for pathfinding.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs,
max_new_tokens=2048,
temperature=0.2,
top_p=0.9,
do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
🚀 Quick Start
Deployment
Spec-T1-RL-7B can be deployed on consumer hardware due to its efficient architecture and parameter count:
Minimum Requirements
- 16GB VRAM (bfloat16/float16)
- 32GB system RAM
- CUDA-compatible GPU
Recommended Configuration
- 24GB+ VRAM for optimal performance
- 64GB+ system RAM for long-context applications
- NVIDIA A10 or better
Citation
If you use Spec-T1-RL-7B in your research, please cite:
@misc{svector2025spect1,
title={Spec-T1-RL-7B: Structured Reasoning through Reinforcement Alignment},
author={SVECTOR Team},
year={2025},
}
License
Spec-T1-RL-7B is released under the MIT License.
Contact
For questions, feedback, or collaboration inquiries, please contact:
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

{kind=link}