🚀 Spec-T1-RL-7B
Spec-T1-RL-7B 是一款高精度的数学与算法推理模型,在数学推理、算法问题解决和代码生成等领域表现卓越,能为相关技术研究和应用提供强大支持。

📄 模型卡片
| 属性 |
详情 |
| 开发者 |
SVECTOR |
| 模型大小 |
70 亿参数 |
| 上下文长度 |
32,000 个词元 |
| 训练数据 |
专注于推理的数据集,包含数学、逻辑和代码内容 |
| 精度 |
bfloat16, float16 |
| 许可证 |
MIT |
| 发布日期 |
2025 年 5 月 |
🌟 模型概述
Spec-T1-RL-7B 是一款专门设计的大语言模型,旨在数学推理、算法问题解决和实际代码生成方面表现出色。与通用模型不同,Spec-T1 在架构设计和训练过程中特别针对需要精确逻辑思维的领域进行了优化。
该模型在 70 亿参数规模下,推理能力有了显著提升,在技术基准测试中超越了许多更大规模的模型,同时保持了高效的部署要求。
✨ 主要特性
- 数学推理:通过逐步的逻辑推导解决复杂的数学问题。
- 算法问题解决:在多个领域设计和分析算法。
- 代码生成:生成功能完善、高质量的代码,测试通过率高。
- 精确指令遵循:准确响应结构化的技术提示。
- 符号验证:使用内置的验证机制进行数学和逻辑验证。
🏗️ 模型架构
Spec-T1-RL-7B 结合了多种架构创新,以实现其专门的推理能力:
- 基础架构:具有优化注意力机制的先进变压器架构。
- 专家混合(MoE):轻量级条件计算,实现高效扩展。
- 激活函数:SwiGLU 激活函数,改善数学运算中的梯度流。
- 归一化:RMSNorm,在推理任务中实现更快的收敛和稳定性。
📈 训练方法
我们的模型经过了三个阶段的训练过程,旨在优化推理能力:
1️⃣ 推理感知预训练
- 专业语料库:高度强调数学符号、逻辑语法和代码。
- 课程学习方法:优先处理结构化推理模式。
- 自定义分词器:针对数学和编程语法进行优化。
2️⃣ 指令微调
- 400K+ 多领域结构化提示:专注于推理任务。
- 结合 CodeInstruct 方法和 ThoughtChain 提示。
- 合成数据生成:带有验证反馈循环。
3️⃣ 强化学习对齐
- 奖励建模:使用确定性的通过/失败信号来评估数学和代码的正确性。
- 单元测试集成:实时验证生成的解决方案。
- 符号验证:对数学证明和推导进行验证。
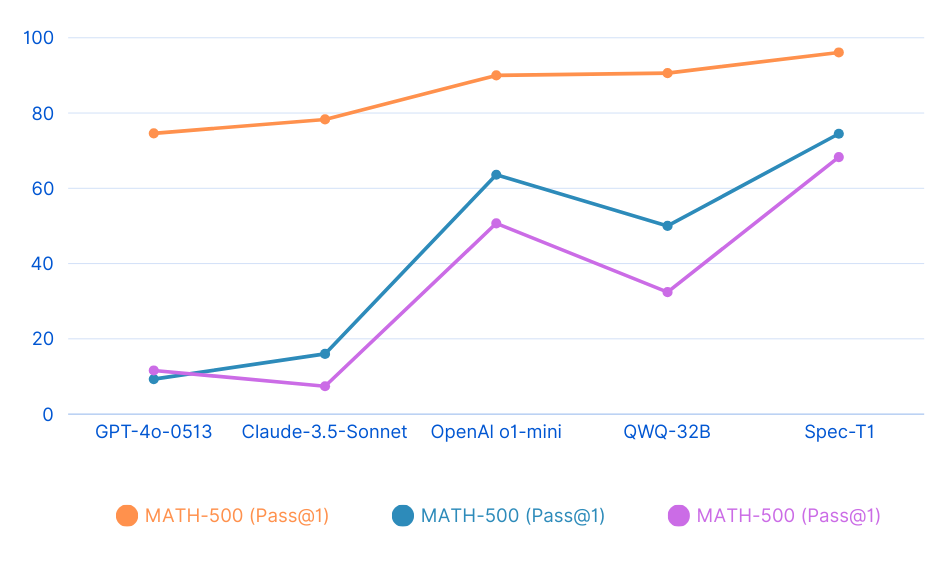
📊 基准测试性能
Spec-T1-RL-7B 模型在推理基准测试中表现出色,特别是在数学和代码生成任务中:
通用推理
| 基准测试 |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
| GPQA Diamond (Pass@1) |
49.9 |
65.0 |
60.0 |
54.5 |
65.1 |
| SuperGPQA (Pass@1) |
42.4 |
48.2 |
45.2 |
43.6 |
52.8 |
| DROP (3-shot F1) |
83.7 |
88.3 |
83.9 |
71.2 |
86.2 |
| MMLU-Pro (EM) |
72.6 |
78.0 |
80.3 |
52.0 |
76.4 |
| IF-Eval (Prompt Strict) |
84.3 |
86.5 |
84.8 |
40.4 |
83.3 |
数学基准测试
数学
| 基准测试 |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
| MATH-500 (Pass@1) |
74.6 |
78.3 |
90.0 |
90.6 |
96.1 |
| AIME 2024 (Pass@1) |
9.3 |
16.0 |
63.6 |
50.0 |
74.5 |
| AIME 2025 (Pass@1) |
11.6 |
7.4 |
50.7 |
32.4 |
68.3 |
代码生成
| 基准测试 |
GPT-4o-0513 |
Claude-3.5-Sonnet |
OpenAI o1-mini |
QwQ-32B |
Spec-T1 |
| LiveCodeBench v5 (Pass@1) |
32.9 |
38.9 |
53.8 |
41.9 |
60.2 |
| LiveCodeBench v6 (Pass@1) |
30.9 |
37.2 |
46.8 |
39.1 |
54.4 |
💻 使用示例
基础用法(使用 Transformers)
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("SVECTOR-CORPORATION/Spec-T1-RL-7B")
tokenizer = AutoTokenizer.from_pretrained("SVECTOR-CORPORATION/Spec-T1-RL-7B")
prompt = """
Prove: The sum of the first n odd numbers is n^2.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
高级用法(使用生成参数)
prompt = """
Design an efficient algorithm to find the longest increasing subsequence in an array of integers.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs,
max_new_tokens=1024,
temperature=0.1,
top_p=0.95,
do_sample=True,
num_return_sequences=1,
repetition_penalty=1.1
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
代码生成示例
prompt = """
Write a Python function that implements the A* search algorithm for pathfinding.
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
inputs,
max_new_tokens=2048,
temperature=0.2,
top_p=0.9,
do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
🚀 部署
由于其高效的架构和参数数量,Spec-T1-RL-7B 可以部署在消费级硬件上:
最低要求
- 16GB 显存(bfloat16/float16)
- 32GB 系统内存
- 支持 CUDA 的 GPU
推荐配置
- 24GB 以上显存,以获得最佳性能
- 64GB 以上系统内存,用于长上下文应用
- NVIDIA A10 或更高版本
📝 引用
如果您在研究中使用了 Spec-T1-RL-7B,请引用:
@misc{svector2025spect1,
title={Spec-T1-RL-7B: Structured Reasoning through Reinforcement Alignment},
author={SVECTOR Team},
year={2025},
}
📄 许可证
Spec-T1-RL-7B 采用 MIT 许可证发布。
📞 联系我们
如有问题、反馈或合作咨询,请联系:
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

{kind=link}
 Transformers 支持多种语言
Transformers 支持多种语言