🚀 protgpt2-distilled-tiny模型
本項目的protgpt2-distilled-tiny模型是ProtGPT2的蒸餾版本。通過知識蒸餾技術,該模型在提升推理速度的同時,仍能保持與原始模型相近的性能,可廣泛應用於藥物發現、醫療診斷和學術教育等領域。
🚀 快速開始
你可以按照以下步驟使用protgpt2-distilled-tiny模型:
from transformers import GPT2Tokenizer, GPT2LMHeadModel, TextGenerationPipeline
import re
model_name = "littleworth/protgpt2-distilled-tiny"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
text_generator = TextGenerationPipeline(
model=model, tokenizer=tokenizer, device=0
)
generated_sequences = text_generator(
"<|endoftext|>",
max_length=100,
do_sample=True,
top_k=950,
repetition_penalty=1.2,
num_return_sequences=10,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=0,
truncation=True,
)
def clean_sequence(text):
text = text.replace("<|endoftext|>", "")
text = "".join(char for char in text if char.isalpha())
return text
for i, seq in enumerate(generated_sequences):
cleaned_text = clean_sequence(seq["generated_text"])
print(f">Seq_{i}")
print(cleaned_text)
✨ 主要特性
- 推理速度快:蒸餾後的
protgpt2-distilled-tiny模型推理速度大幅提升,最高可達預訓練版本的6倍。
- 性能相近:在速度顯著提升的同時,模型仍能保持與原始模型相近的困惑度。
- 應用廣泛:可應用於藥物發現中的高通量篩選、醫療保健中的便攜式診斷以及學術領域的交互式學習工具等。
📦 安裝指南
文檔未提及具體安裝步驟,你可參考transformers庫的官方文檔進行安裝:
pip install transformers
💻 使用示例
基礎用法
from transformers import GPT2Tokenizer, GPT2LMHeadModel, TextGenerationPipeline
import re
model_name = "littleworth/protgpt2-distilled-tiny"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
text_generator = TextGenerationPipeline(
model=model, tokenizer=tokenizer, device=0
)
generated_sequences = text_generator(
"<|endoftext|>",
max_length=100,
do_sample=True,
top_k=950,
repetition_penalty=1.2,
num_return_sequences=10,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=0,
truncation=True,
)
def clean_sequence(text):
text = text.replace("<|endoftext|>", "")
text = "".join(char for char in text if char.isalpha())
return text
for i, seq in enumerate(generated_sequences):
cleaned_text = clean_sequence(seq["generated_text"])
print(f">Seq_{i}")
print(cleaned_text)
📚 詳細文檔
模型描述
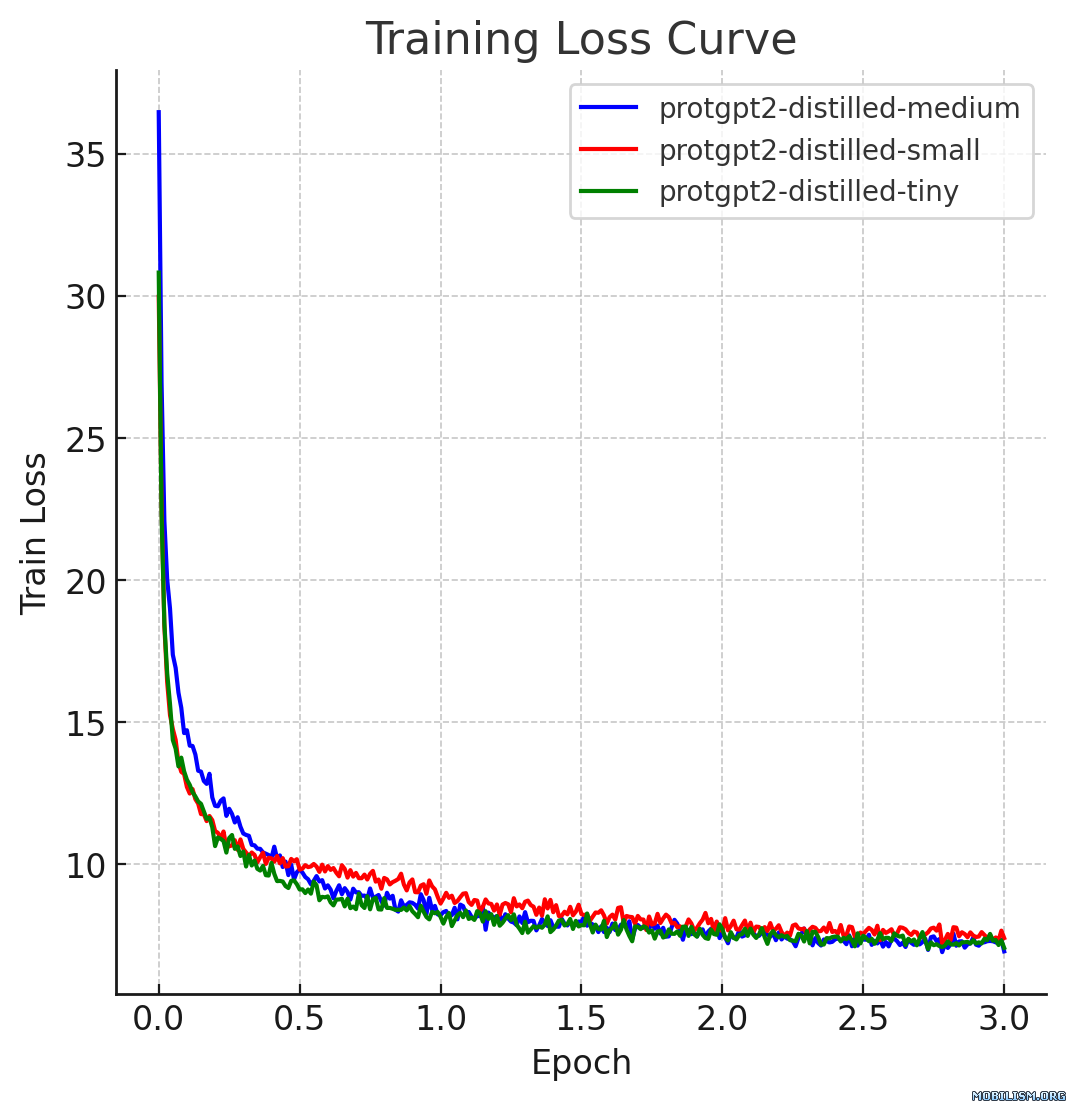
本模型卡片描述的是ProtGPT2的蒸餾版本,即protgpt2-distilled-tiny。該模型的蒸餾過程遵循從大型教師模型到小型高效學生模型的知識蒸餾方法,結合了“軟損失”(知識蒸餾損失)和“硬損失”(交叉熵損失),以確保學生模型不僅能像教師模型一樣泛化,還能保留實際的預測能力。
使用場景
- 藥物發現中的高通量篩選:蒸餾後的ProtGPT2通過高效預測蛋白質變體的穩定性,有助於在藥物發現中進行快速突變篩選。其較小的模型規模允許在新數據集上進行快速微調,加快目標識別的速度。
- 醫療保健中的便攜式診斷:該模型適用於手持設備,可在遠程臨床環境中進行即時蛋白質分析,提供即時診斷結果。
- 學術領域的交互式學習工具:將蒸餾模型集成到教育軟件中,可幫助生物學學生在無需高級計算資源的情況下模擬和理解蛋白質動力學。
參考資料
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv:1503.02531.
- 原始ProtGPT2論文:論文鏈接
🔧 技術細節
蒸餾參數
- 溫度 (T):10
- 阿爾法 (α):0.1
- 模型架構:
使用的數據集
該模型使用了nferruz/UR50_2021_04提供的評估數據集的一個子集進行蒸餾。
損失公式
- 軟損失:$L_{soft} = KL(softmax(s/T), softmax(t/T))$,其中 $s$ 是學生模型的對數幾率,$t$ 是教師模型的對數幾率,$T$ 是用於軟化概率的溫度。
- 硬損失:$L_{hard} = -∑{i} y{i} log(softmax(s_{i}))$,其中 $y_{i}$ 表示真實標籤,$s_{i}$ 是學生模型對應每個標籤的對數幾率。
- 組合損失:$L = α L_{hard} + (1 - α) L_{soft}$,其中 $α$(阿爾法)是平衡硬損失和軟損失的權重因子。
注意:KL表示Kullback-Leibler散度,是一種用於量化一個概率分佈與第二個預期概率分佈之間差異的度量。
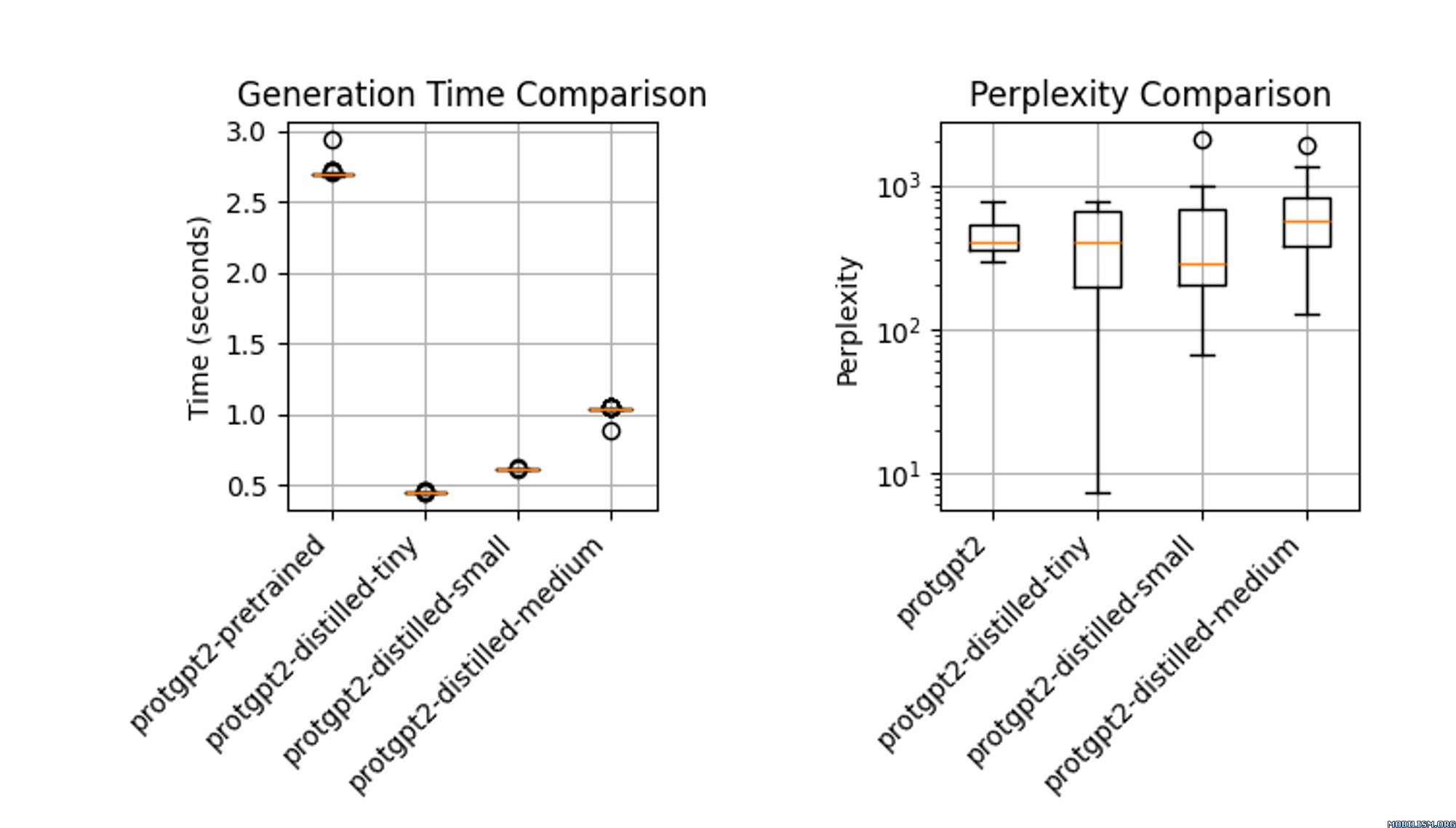
性能表現
蒸餾後的模型protgpt2-distilled-tiny推理速度大幅提升,最高可達預訓練版本的6倍。該評估基於 $n = 100$ 次測試,結果顯示,雖然速度顯著提高,但模型仍能保持與原始模型相近的困惑度。
📄 許可證
本項目採用Apache-2.0許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言