🚀 protgpt2-distilled-tiny模型
本项目的protgpt2-distilled-tiny模型是ProtGPT2的蒸馏版本。通过知识蒸馏技术,该模型在提升推理速度的同时,仍能保持与原始模型相近的性能,可广泛应用于药物发现、医疗诊断和学术教育等领域。
🚀 快速开始
你可以按照以下步骤使用protgpt2-distilled-tiny模型:
from transformers import GPT2Tokenizer, GPT2LMHeadModel, TextGenerationPipeline
import re
model_name = "littleworth/protgpt2-distilled-tiny"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
text_generator = TextGenerationPipeline(
model=model, tokenizer=tokenizer, device=0
)
generated_sequences = text_generator(
"<|endoftext|>",
max_length=100,
do_sample=True,
top_k=950,
repetition_penalty=1.2,
num_return_sequences=10,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=0,
truncation=True,
)
def clean_sequence(text):
text = text.replace("<|endoftext|>", "")
text = "".join(char for char in text if char.isalpha())
return text
for i, seq in enumerate(generated_sequences):
cleaned_text = clean_sequence(seq["generated_text"])
print(f">Seq_{i}")
print(cleaned_text)
✨ 主要特性
- 推理速度快:蒸馏后的
protgpt2-distilled-tiny模型推理速度大幅提升,最高可达预训练版本的6倍。
- 性能相近:在速度显著提升的同时,模型仍能保持与原始模型相近的困惑度。
- 应用广泛:可应用于药物发现中的高通量筛选、医疗保健中的便携式诊断以及学术领域的交互式学习工具等。
📦 安装指南
文档未提及具体安装步骤,你可参考transformers库的官方文档进行安装:
pip install transformers
💻 使用示例
基础用法
from transformers import GPT2Tokenizer, GPT2LMHeadModel, TextGenerationPipeline
import re
model_name = "littleworth/protgpt2-distilled-tiny"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
text_generator = TextGenerationPipeline(
model=model, tokenizer=tokenizer, device=0
)
generated_sequences = text_generator(
"<|endoftext|>",
max_length=100,
do_sample=True,
top_k=950,
repetition_penalty=1.2,
num_return_sequences=10,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=0,
truncation=True,
)
def clean_sequence(text):
text = text.replace("<|endoftext|>", "")
text = "".join(char for char in text if char.isalpha())
return text
for i, seq in enumerate(generated_sequences):
cleaned_text = clean_sequence(seq["generated_text"])
print(f">Seq_{i}")
print(cleaned_text)
📚 详细文档
模型描述
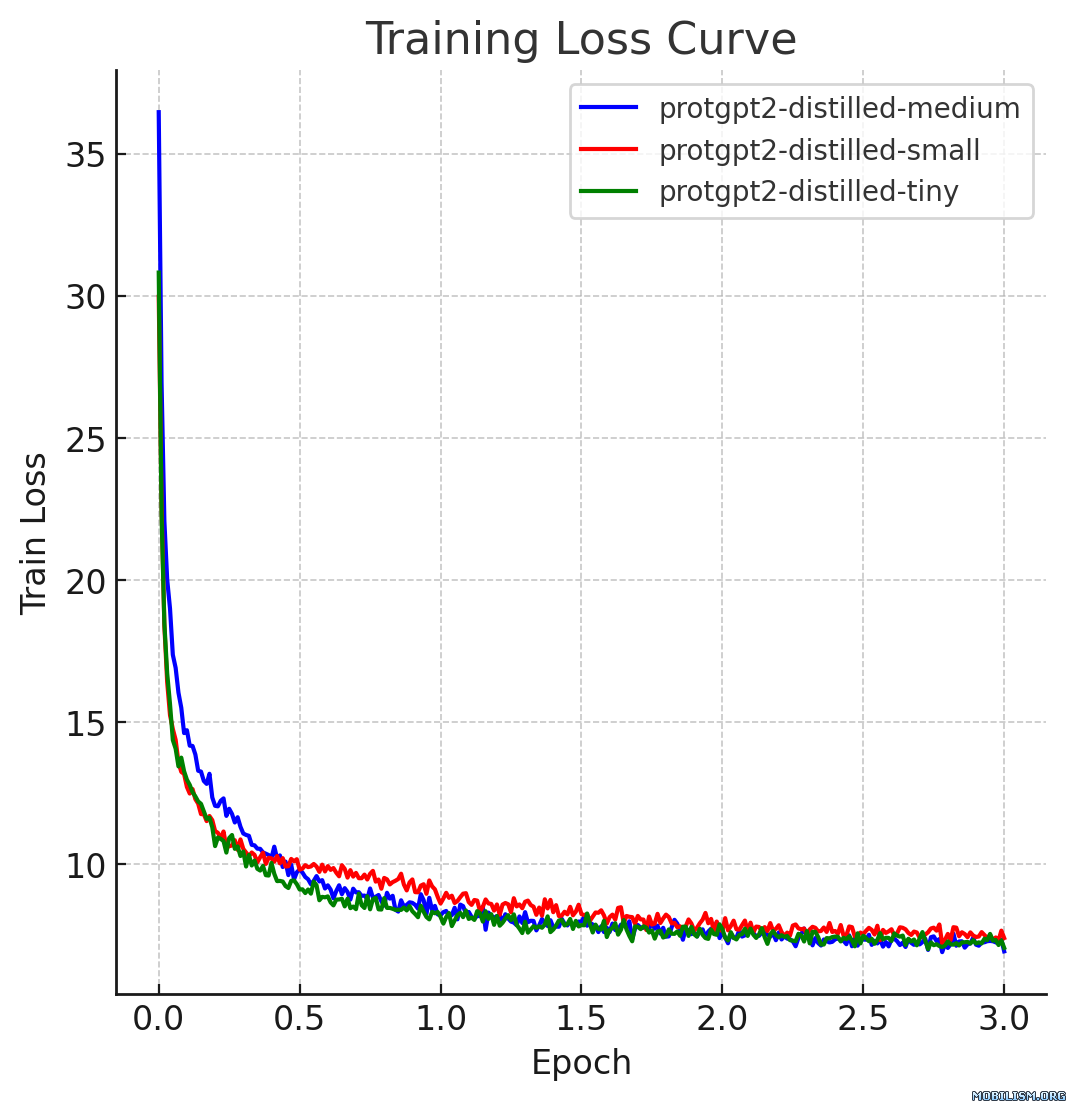
本模型卡片描述的是ProtGPT2的蒸馏版本,即protgpt2-distilled-tiny。该模型的蒸馏过程遵循从大型教师模型到小型高效学生模型的知识蒸馏方法,结合了“软损失”(知识蒸馏损失)和“硬损失”(交叉熵损失),以确保学生模型不仅能像教师模型一样泛化,还能保留实际的预测能力。
使用场景
- 药物发现中的高通量筛选:蒸馏后的ProtGPT2通过高效预测蛋白质变体的稳定性,有助于在药物发现中进行快速突变筛选。其较小的模型规模允许在新数据集上进行快速微调,加快目标识别的速度。
- 医疗保健中的便携式诊断:该模型适用于手持设备,可在远程临床环境中进行实时蛋白质分析,提供即时诊断结果。
- 学术领域的交互式学习工具:将蒸馏模型集成到教育软件中,可帮助生物学学生在无需高级计算资源的情况下模拟和理解蛋白质动力学。
参考资料
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv:1503.02531.
- 原始ProtGPT2论文:论文链接
🔧 技术细节
蒸馏参数
- 温度 (T):10
- 阿尔法 (α):0.1
- 模型架构:
使用的数据集
该模型使用了nferruz/UR50_2021_04提供的评估数据集的一个子集进行蒸馏。
损失公式
- 软损失:$L_{soft} = KL(softmax(s/T), softmax(t/T))$,其中 $s$ 是学生模型的对数几率,$t$ 是教师模型的对数几率,$T$ 是用于软化概率的温度。
- 硬损失:$L_{hard} = -∑{i} y{i} log(softmax(s_{i}))$,其中 $y_{i}$ 表示真实标签,$s_{i}$ 是学生模型对应每个标签的对数几率。
- 组合损失:$L = α L_{hard} + (1 - α) L_{soft}$,其中 $α$(阿尔法)是平衡硬损失和软损失的权重因子。
注意:KL表示Kullback-Leibler散度,是一种用于量化一个概率分布与第二个预期概率分布之间差异的度量。
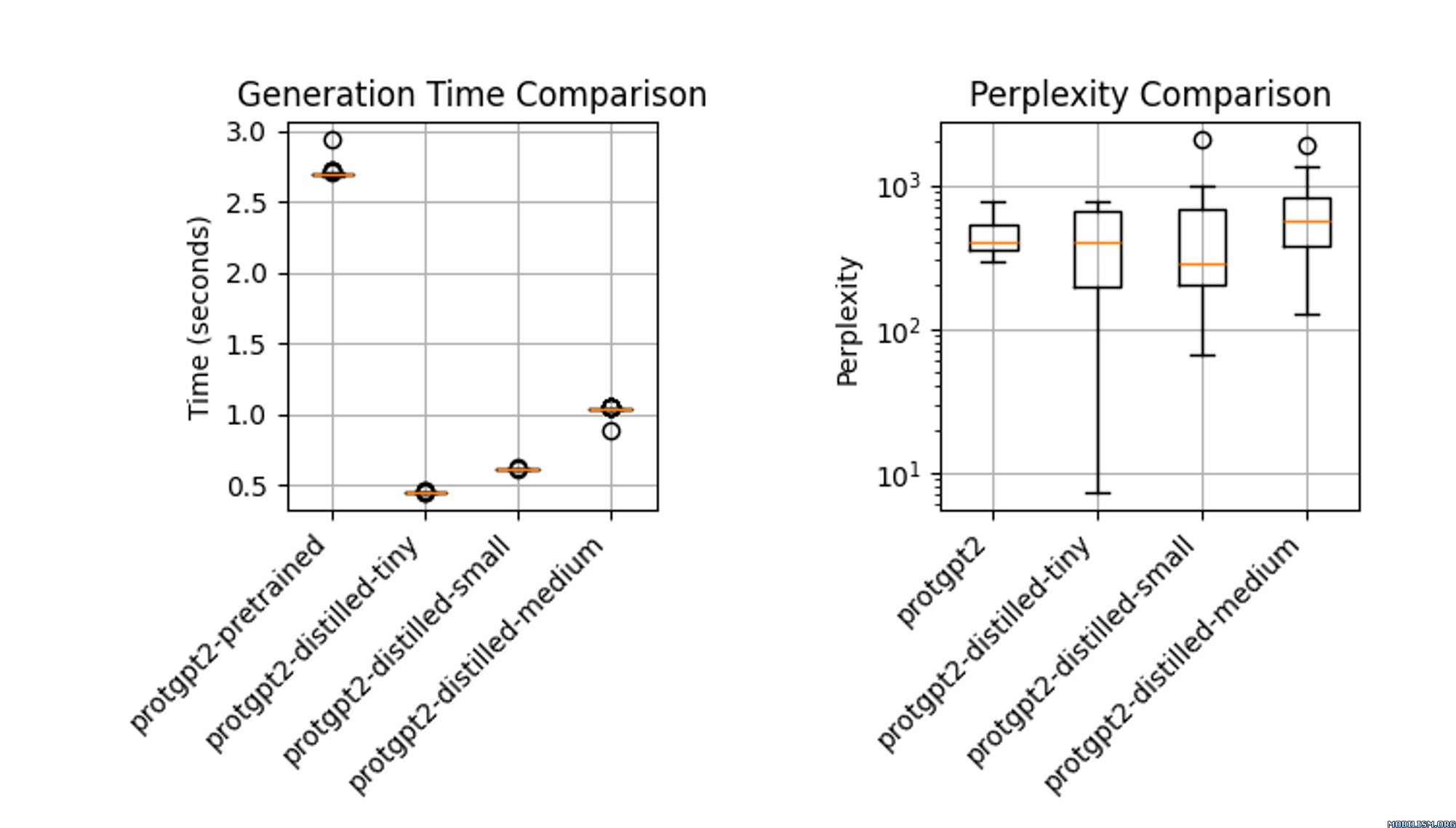
性能表现
蒸馏后的模型protgpt2-distilled-tiny推理速度大幅提升,最高可达预训练版本的6倍。该评估基于 $n = 100$ 次测试,结果显示,虽然速度显著提高,但模型仍能保持与原始模型相近的困惑度。
📄 许可证
本项目采用Apache-2.0许可证。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言