%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
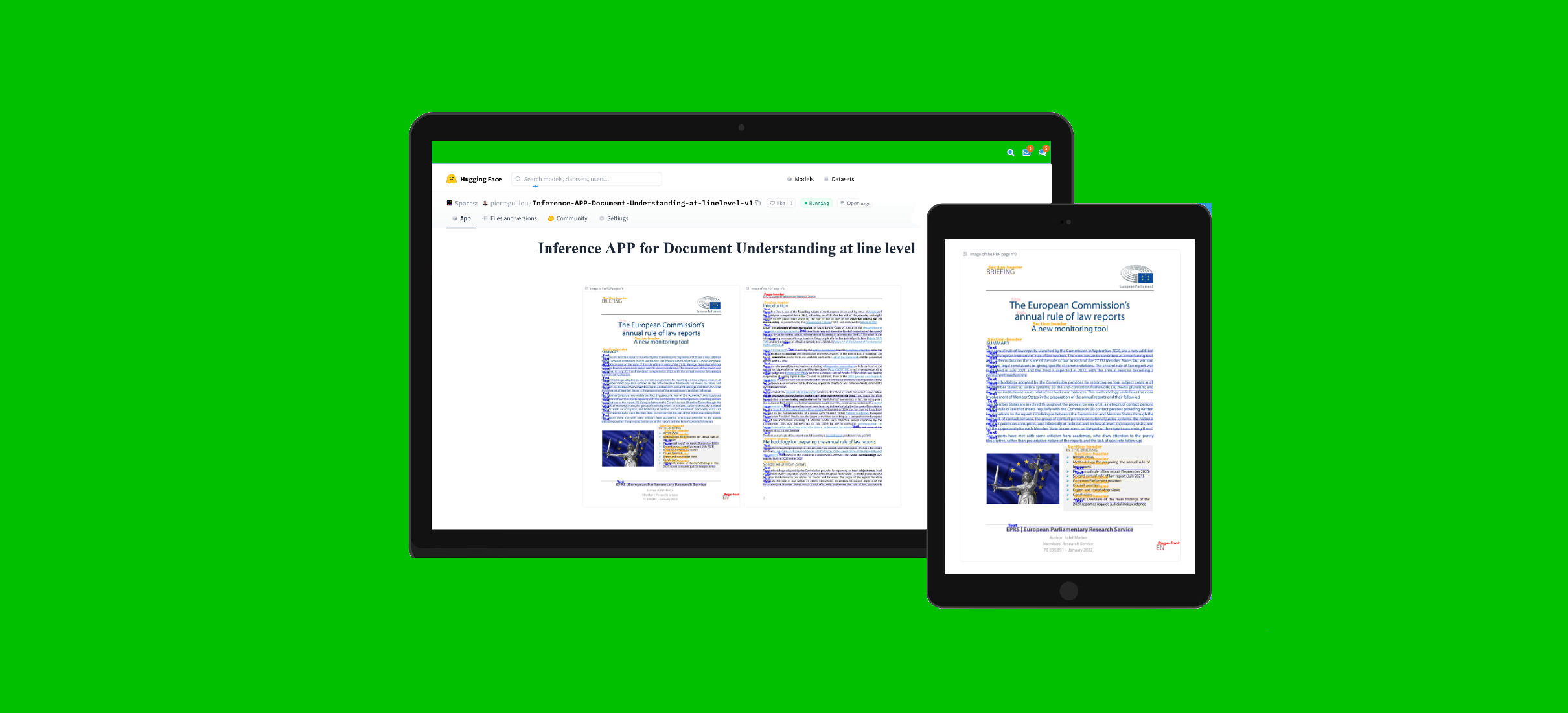
Layout Xlm Base Finetuned With DocLayNet Base At Linelevel Ml384
LayoutXLMベースモデルをDocLayNetデータセットで微調整した行レベルドキュメント理解モデルで、多言語ドキュメントのレイアウト分析とマーク分類をサポートします。
ダウンロード数 103
リリース時間 : 3/2/2023
モデル概要
このモデルはドキュメントのレイアウト分析と理解に特化しており、テキスト、見出し、表などのドキュメント内のさまざまな要素を識別・分類できます。財務報告書、科学論文、法律文書など、さまざまなドキュメントタイプの処理に適しています。
モデル特徴
多言語サポート
英語、ドイツ語、フランス語、日本語など、複数言語のドキュメント理解をサポートします。
行レベル分析
384トークンブロック(128トークンのオーバーラップ付き)の行レベルで微調整されており、詳細なドキュメント要素の識別を提供します。
高性能マーク分類
DocLayNet評価セットでF1値0.7336、精度0.9373を達成しました。
モデル能力
ドキュメントレイアウト分析
マーク分類
多言語テキスト理解
行レベル要素識別
使用事例
金融ドキュメント処理
財務報告書分析
財務報告書内の表、見出し、本文コンテンツを自動識別します。
財務データ抽出の効率と精度を向上させます。
学術研究
科学論文解析
科学論文から章見出し、図表、参考文献を抽出します。
研究者が論文構造情報を迅速に取得するのを支援します。
法律文書処理
契約条項識別
法律文書内の条項、定義、署名領域を自動マークします。
法律文書レビュープロセスを加速します。
 Safetensors
SafetensorsおすすめAIモデル
Llama 3 Typhoon V1.5x 8b Instruct
タイ語専用に設計された80億パラメータの命令モデルで、GPT-3.5-turboに匹敵する性能を持ち、アプリケーションシナリオ、検索拡張生成、制限付き生成、推論タスクを最適化
大規模言語モデル Transformers 複数言語対応
Transformers 複数言語対応
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-TinyはSODAデータセットでトレーニングされた超小型対話モデルで、エッジデバイス推論向けに設計されており、体積はCosmo-3Bモデルの約2%です。
対話システム Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
RoBERTaアーキテクチャに基づく中国語抽出型QAモデルで、与えられたテキストから回答を抽出するタスクに適しています。
質問応答システム 中国語
R
uer
2,694
98