%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 文檔理解模型(在DocLayNet基礎數據集上按行級別微調的LayoutXLM基礎模型)
該模型是一個文檔理解模型,基於microsoft/layoutxlm-base,使用DocLayNet base數據集進行微調。它在文檔佈局分析和理解方面表現出色,能為各類文檔提供準確的結構識別和內容分類。
🚀 快速開始
本模型可用於文檔理解任務,特別是在文檔佈局分析和行級別的文本分類方面。你可以通過以下資源快速上手:
- 推理:參考筆記本 Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)。
- 訓練和評估:參考筆記本 Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)。
✨ 主要特性
- 多語言支持:支持多種語言,適用於不同語言環境下的文檔理解。
- 高精度:在評估集上取得了良好的指標,如F1值達到0.7336,準確率達到0.9373。
- 行級處理:模型在384個標記的塊上按行級別進行微調,能夠對每行文本進行準確分類。
📚 詳細文檔
模型描述
該模型在384個標記的塊上按行級別進行微調,重疊128個標記。因此,模型使用了數據集中所有頁面的佈局和文本數據進行訓練。在推理時,通過計算最佳概率為每個行邊界框分配標籤。
推理
你可以參考以下筆記本進行推理:Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)。
訓練和評估數據
關於訓練和評估數據的詳細信息,請參考筆記本:Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)。
訓練過程
訓練超參數
訓練過程中使用了以下超參數:
| 屬性 | 詳情 |
|---|---|
| 學習率 | 2e-05 |
| 訓練批次大小 | 8 |
| 評估批次大小 | 16 |
| 隨機種子 | 42 |
| 優化器 | Adam(betas=(0.9, 0.999),epsilon=1e-08) |
| 學習率調度器類型 | 線性 |
| 學習率調度器熱身比例 | 0.1 |
| 訓練輪數 | 3 |
| 混合精度訓練 | 原生AMP |
訓練結果
| 訓練損失 | 輪數 | 步數 | 準確率 | F1值 | 驗證損失 | 精確率 | 召回率 |
|---|---|---|---|---|---|---|---|
| No log | 0.12 | 300 | 0.8413 | 0.1311 | 0.5185 | 0.1437 | 0.1205 |
| 0.9231 | 0.25 | 600 | 0.8751 | 0.5031 | 0.4108 | 0.4637 | 0.5498 |
| 0.9231 | 0.37 | 900 | 0.8887 | 0.5206 | 0.3911 | 0.5076 | 0.5343 |
| 0.369 | 0.5 | 1200 | 0.8724 | 0.5365 | 0.4118 | 0.5094 | 0.5667 |
| 0.2737 | 0.62 | 1500 | 0.8960 | 0.6033 | 0.3328 | 0.6046 | 0.6020 |
| 0.2737 | 0.75 | 1800 | 0.9186 | 0.6404 | 0.2984 | 0.6062 | 0.6787 |
| 0.2542 | 0.87 | 2100 | 0.9163 | 0.6593 | 0.3115 | 0.6324 | 0.6887 |
| 0.2542 | 1.0 | 2400 | 0.9198 | 0.6537 | 0.2878 | 0.6160 | 0.6962 |
| 0.1938 | 1.12 | 2700 | 0.9165 | 0.6752 | 0.3414 | 0.6673 | 0.6833 |
| 0.1581 | 1.25 | 3000 | 0.9193 | 0.6871 | 0.3611 | 0.6868 | 0.6875 |
| 0.1581 | 1.37 | 3300 | 0.9256 | 0.6822 | 0.2763 | 0.6988 | 0.6663 |
| 0.1428 | 1.5 | 3600 | 0.9287 | 0.7084 | 0.3065 | 0.7246 | 0.6929 |
| 0.1428 | 1.62 | 3900 | 0.9194 | 0.6812 | 0.2942 | 0.6866 | 0.6760 |
| 0.1025 | 1.74 | 4200 | 0.9347 | 0.7223 | 0.2990 | 0.7315 | 0.7133 |
| 0.1225 | 1.87 | 4500 | 0.9360 | 0.7048 | 0.2729 | 0.7249 | 0.6858 |
| 0.1225 | 1.99 | 4800 | 0.9396 | 0.7222 | 0.2826 | 0.7497 | 0.6966 |
| 0.108 | 2.12 | 5100 | 0.9301 | 0.7193 | 0.3071 | 0.7022 | 0.7372 |
| 0.108 | 2.24 | 5400 | 0.9334 | 0.7243 | 0.2999 | 0.7250 | 0.7237 |
| 0.0799 | 2.37 | 5700 | 0.9382 | 0.7254 | 0.2710 | 0.7310 | 0.7198 |
| 0.0793 | 2.49 | 6000 | 0.9329 | 0.7228 | 0.3201 | 0.7352 | 0.7108 |
| 0.0793 | 2.62 | 6300 | 0.9373 | 0.7336 | 0.3035 | 0.7260 | 0.7415 |
| 0.0696 | 2.74 | 6600 | 0.9374 | 0.7275 | 0.3137 | 0.7313 | 0.7237 |
| 0.0696 | 2.87 | 6900 | 0.9381 | 0.7253 | 0.3242 | 0.7369 | 0.7142 |
| 0.0866 | 2.99 | 7200 | 0.2473 | 0.7439 | 0.7207 | 0.7321 | 0.9407 |
框架版本
- Transformers 4.26.1
- Pytorch 1.10.0+cu111
- Datasets 2.10.1
- Tokenizers 0.13.2
參考資料
博客文章
- Layout XLM base
- LiLT base
- (02/16/2023) Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level
- (02/14/2023) Document AI | Inference APP for Document Understanding at line level
- (02/10/2023) Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset
- (01/31/2023) Document AI | DocLayNet image viewer APP
- (01/27/2023) Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
筆記本(段落級別)
- LiLT base
- Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
筆記本(行級別)
- Layout XLM base
- Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- LiLT base
- Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- DocLayNet image viewer APP
- Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
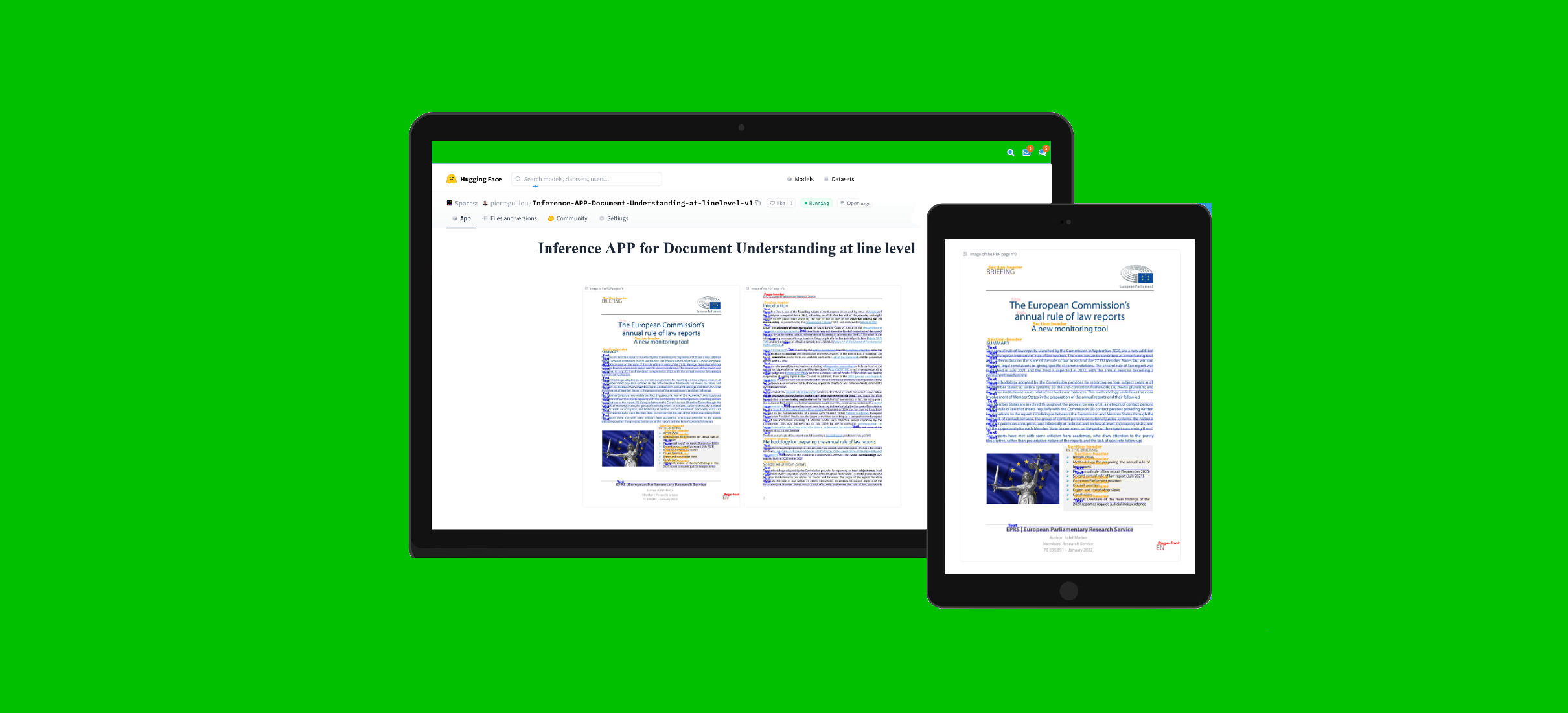
APP
你可以使用Hugging Face Spaces中的這個應用程序測試該模型:Inference APP for Document Understanding at line level (v2)。
DocLayNet數據集
DocLayNet數據集(IBM)為來自6個文檔類別的80863個唯一頁面上的11個不同類別標籤提供了逐頁佈局分割的真實標註,使用了邊界框。到目前為止,該數據集可以通過直接鏈接或從Hugging Face數據集下載:
- 直接鏈接:doclaynet_core.zip(28 GiB),doclaynet_extra.zip(7.5 GiB)
- Hugging Face數據集庫:dataset DocLayNet
論文:DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis(06/02/2022)
其他模型
- 行級別
- Document Understanding model (finetuned LiLT base at line level on DocLayNet base)(準確率 | 標記:85.84% - 行:91.97%)
- Document Understanding model (finetuned LayoutXLM base at line level on DocLayNet base)(準確率 | 標記:93.73% - 行:...)
- 段落級別
- Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base)(準確率 | 標記:86.34% - 段落:68.15%)
- Document Understanding model (finetuned LayoutXLM base at paragraph level on DocLayNet base)(準確率 | 標記:96.93% - 段落:86.55%)
📄 許可證
本模型採用MIT許可證。
 Safetensors
Safetensors