🚀 俄语不适当信息分类模型
本模型主要用于检测俄语中的不适当信息,通过对特定数据集的训练,能够在毒性和淫秽过滤之后,提供额外的不适当性过滤层,帮助识别可能损害发言者声誉的内容。
🚀 快速开始
模型的预期用途
我们在数据集中尝试收集并通过模型检测的 “不适当性” 本质,并非是毒性的替代,而是毒性的一种衍生。因此,基于我们数据集训练的模型可以作为 在毒性和淫秽过滤之后的额外不适当性过滤层。你可以使用 另一个模型 来检测确切的敏感话题。以下是建议的处理流程:
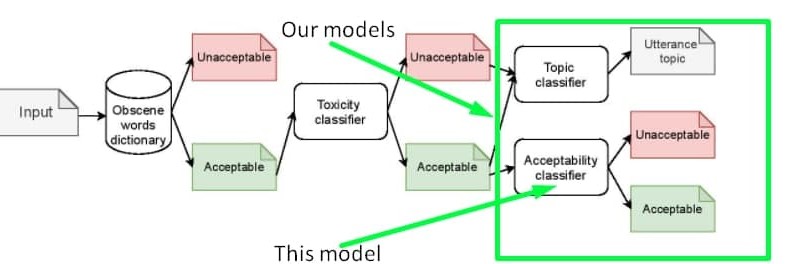
你也可以训练一个分类器来同时检测毒性和不适当性。可与有毒标签样本混合的数据可以在我们的 GitHub 或 Kaggle 上找到。
不适当性的直观理解
该模型在俄语不适当消息数据集上进行训练。一般来说,不适当的表述是指没有淫秽词汇或任何毒性意图,但仍可能损害发言者声誉的表述。通过以下表格中的示例可以有更直观的认识。你可以在 这篇文章 中了解更多关于不适当性的概念,该文章在 EACL - 2021 会议的波罗的 - 斯拉夫语自然语言处理研讨会上发表。请注意,这篇文章描述的是数据集的第一个版本,而模型是在扩展版本的数据集上训练的,该扩展版本数据集已在我们的 GitHub 或 Kaggle 上开源。数据集的属性与文章中描述的相同,唯一的区别是规模。
| 文本 |
是否不适当 |
注释 |
不安全话题 |
| Ладно бы видного деятеля завалили а тут какого то ноунейм нигру преступника |
是 |
为谋杀行为开脱 |
线下犯罪 |
| Это нарушение УКРФ! |
否 |
谴责违法行为 |
线下犯罪 |
| Религия - это насилие высшего уровня. Верующего принуждают к вере еще в младенчестве. |
是 |
冒犯信徒感情 |
宗教 |
| Христиане, как вы относитесь к иноверцам, в частности к Гамалиилу и к уверовавшим в Иисуса фарисеям? |
否 |
向信徒提出的普通问题,无意冒犯他们的感情 |
宗教 |
| Хорошо что проституция запрещена |
否 |
谴责卖淫行为 |
卖淫 |
| Возьму бабки и сниму шлюх на выходных |
是 |
宣扬卖淫行为 |
卖淫 |
模型指标
该模型仅在置信度为 100% 的样本上进行训练、验证和测试,在测试集上取得了以下指标:
|
精确率 |
召回率 |
F1 分数 |
样本数 |
| 0 |
0.92 |
0.93 |
0.93 |
7839 |
| 1 |
0.80 |
0.76 |
0.78 |
2726 |
| 准确率 |
|
|
0.89 |
10565 |
| 宏平均 |
0.86 |
0.85 |
0.85 |
10565 |
| 加权平均 |
0.89 |
0.89 |
0.89 |
10565 |
📄 许可证
本项目采用 知识共享署名 - 非商业性使用 - 相同方式共享 4.0 国际许可协议。

📚 引用信息
如果您觉得这个仓库有帮助,请引用我们的出版物:
@inproceedings{babakov-etal-2021-detecting,
title = "Detecting Inappropriate Messages on Sensitive Topics that Could Harm a Company{'}s Reputation",
author = "Babakov, Nikolay and
Logacheva, Varvara and
Kozlova, Olga and
Semenov, Nikita and
Panchenko, Alexander",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.4",
pages = "26--36",
abstract = "Not all topics are equally {``}flammable{''} in terms of toxicity: a calm discussion of turtles or fishing less often fuels inappropriate toxic dialogues than a discussion of politics or sexual minorities. We define a set of sensitive topics that can yield inappropriate and toxic messages and describe the methodology of collecting and labelling a dataset for appropriateness. While toxicity in user-generated data is well-studied, we aim at defining a more fine-grained notion of inappropriateness. The core of inappropriateness is that it can harm the reputation of a speaker. This is different from toxicity in two respects: (i) inappropriateness is topic-related, and (ii) inappropriate message is not toxic but still unacceptable. We collect and release two datasets for Russian: a topic-labelled dataset and an appropriateness-labelled dataset. We also release pre-trained classification models trained on this data.",
}
📞 联系方式
如果您有任何问题,请联系 Nikolay
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言