🚀 DistilBERT基础无大小写微调SST - 2
本模型是基于DistilBERT的文本分类模型,在SST - 2数据集上进行微调,可用于主题分类任务,在开发集上达到了较高的准确率。
🚀 快速开始
单标签分类示例
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
✨ 主要特性
📚 详细文档
模型详情
- 模型描述:此模型是DistilBERT - base - uncased在SST - 2上的微调检查点,在开发集上的准确率达到91.3(作为对比,Bert bert - base - uncased版本的准确率为92.7)。
- 开发者:Hugging Face
- 模型类型:文本分类
- 语言:英语
- 许可证:Apache - 2.0
- 父模型:有关DistilBERT的更多详细信息,建议用户查看此模型卡片。
- 更多信息资源:
使用方式
直接使用
该模型可用于主题分类。可以使用原始模型进行掩码语言建模或下一句预测,但它主要用于在下游任务上进行微调。可在模型中心查找针对你感兴趣的任务进行微调的版本。
误用和超出范围的使用
不应使用该模型故意为人们创造敌对或排斥性的环境。此外,该模型并非用于对人或事件进行事实性或真实的表述,因此使用该模型生成此类内容超出了该模型的能力范围。
风险、限制和偏差
基于一些实验,我们观察到该模型可能会产生针对代表性不足群体的有偏差的预测。
例如,对于像This film was filmed in COUNTRY这样的句子,这个二元分类模型会根据国家的不同对正标签给出截然不同的概率(如果国家是法国,概率为0.89,但如果国家是阿富汗,概率为0.08),而输入中并没有任何内容表明存在如此强烈的语义变化。在这个colab中,Aurélien Géron制作了一个有趣的地图,绘制了每个国家的这些概率。
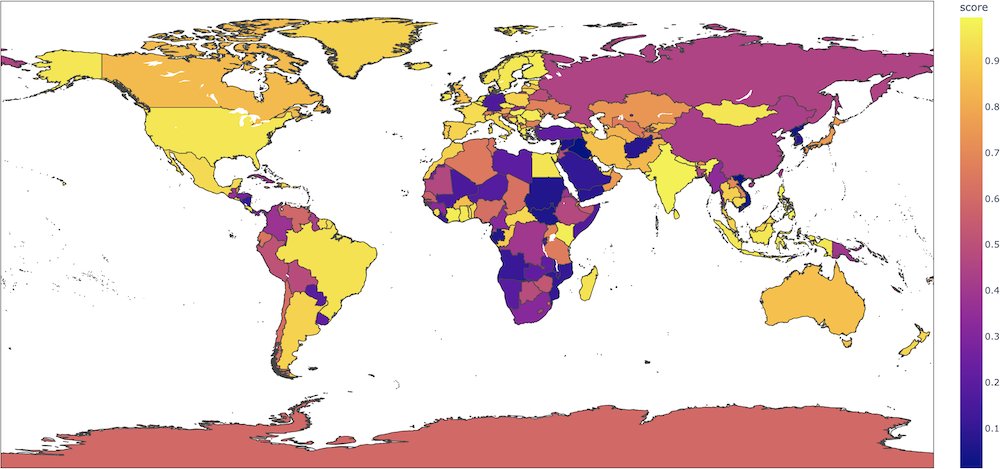
我们强烈建议用户在其用例中彻底探究这些方面,以评估该模型的风险。我们建议将以下偏差评估数据集作为起点:WinoBias、WinoGender、Stereoset。
训练
训练数据
作者使用以下斯坦福情感树库(sst2)语料库对模型进行训练。
训练过程
微调超参数
- 学习率 = 1e - 5
- 批量大小 = 32
- 预热步数 = 600
- 最大序列长度 = 128
- 训练轮数 = 3.0
📄 许可证
本项目采用Apache - 2.0许可证。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言