%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 NoticIA-7B:用于西班牙语标题党文章摘要生成的模型
NoticIA-7B 是一个拥有 70 亿参数的模型,它基于 NoticIA-it 数据集进行训练,能够为标题党文章生成简洁且高质量的摘要,有助于揭示标题背后的真实内容。
![]()
🚀 快速开始
对网页上的标题党文章进行摘要生成
以下代码展示了如何使用模板从标题党文章的 URL 生成摘要:
import torch # pip install torch
from newspaper import Article #pip3 install newspaper3k
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
article_url ="https://www.huffingtonpost.es/virales/le-compra-abrigo-abuela-97nos-reaccion-fantasia.html"
article = Article(article_url)
article.download()
article.parse()
headline=article.title
body = article.text
def prompt(
headline: str,
body: str,
) -> str:
"""
Generate the prompt for the model.
Args:
headline (`str`):
The headline of the article.
body (`str`):
The body of the article.
Returns:
`str`: The formatted prompt.
"""
return (
f"Ahora eres una Inteligencia Artificial experta en desmontar titulares sensacionalistas o clickbait. "
f"Tu tarea consiste en analizar noticias con titulares sensacionalistas y "
f"generar un resumen de una sola frase que revele la verdad detrás del titular.\n"
f"Este es el titular de la noticia: {headline}\n"
f"El titular plantea una pregunta o proporciona información incompleta. "
f"Debes buscar en el cuerpo de la noticia una frase que responda lo que se sugiere en el título. "
f"Siempre que puedas cita el texto original, especialmente si se trata de una frase que alguien ha dicho. "
f"Si citas una frase que alguien ha dicho, usa comillas para indicar que es una cita. "
f"Usa siempre las mínimas palabras posibles. No es necesario que la respuesta sea una oración completa. "
f"Puede ser sólo el foco de la pregunta. "
f"Recuerda responder siempre en Español.\n"
f"Este es el cuerpo de la noticia:\n"
f"{body}\n"
)
prompt = prompt(headline=headline, body=body)
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto", quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
在 NoticIA 数据集上进行推理
以下代码展示了如何在数据集的示例上进行推理:
import torch # pip install torch
from datasets import load_dataset # pip install datasets
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
dataset = load_dataset("somosnlp/NoticIA-it",split="test")
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto", quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": dataset[0]["pregunta"]}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
✨ 主要特性
- 精准摘要:能够准确分析标题党文章,生成揭示标题背后真实内容的单句摘要。
- 多场景适用:可用于网页文章摘要生成和数据集推理。
- 性能优良:在 ROUGE 指标上表现出色,生成的摘要简洁明了。
📦 安装指南
运行代码前,需要安装以下依赖库:
pip install torch
pip3 install newspaper3k
pip install transformers
pip install bitsandbytes
pip install datasets
📚 详细文档
模型详情
模型描述
标题党文章通过引发读者的好奇心来吸引其注意力,标题通常会提出问题或给出不完整、耸人听闻、夸张或误导性的陈述。文章中问题的答案往往在大量无关内容之后才出现,其目的是让用户通过标题进入网站,浏览尽可能多的广告。标题党文章质量通常较低,除了最初的好奇心外,无法为读者提供有价值的信息。这种现象破坏了公众对新闻来源的信任,并对合法内容创作者的广告收入产生负面影响,可能导致他们的网站流量减少。
我们推出的 NoticIA-7B 模型拥有 70 亿参数,基于 NoticIA-it 数据集进行训练,能够为标题党文章生成简洁且高质量的摘要。
- 开发者:Iker García-Ferrero、Begoña Altuna
- 资助方:SomosNLP、HuggingFace、HiTZ Zentroa
- 模型类型:语言模型,经过指令微调
- 语言:西班牙语(西班牙)
- 许可证:Apache-2.0
- 微调基础模型:openchat/openchat-3.5-0106
- 使用的数据集:https://huggingface.co/datasets/somosnlp/NoticIA-it
模型来源
- 💻 代码仓库
- 📖 论文:NoticIA: A Clickbait Article Summarization Dataset in Spanish
- 🤖 数据集和预训练模型
- 🔌 演示
- ▶️ 视频介绍(西班牙语)
- 🐱💻 Hackathon #Somos600M
用途
直接用途
- 📖 对标题党文章进行摘要生成
- 📈 评估西班牙语语言模型
- 📚 开发新的学术资源(如合成数据生成)
- 🎓 用于其他学术研究目的
超出适用范围的用途
禁止使用此模型进行任何可能损害合法专业媒体机构合法性或经济可行性的行为。
偏差、风险和局限性
该模型主要使用来自西班牙的西班牙语新闻进行训练,数据标注人员也来自西班牙。因此,我们预计该模型在处理西班牙西班牙语新闻时表现良好,但不能保证其在处理拉丁美洲新闻或其他语言的新闻时也能有出色的表现。
训练详情
训练数据
标题党文章旨在通过引发读者的好奇心来吸引其注意力。为此,标题通常会提出问题或给出不完整、耸人听闻、夸张或误导性的陈述。文章中问题的答案往往在大量无关内容之后才出现,其目的是让用户通过标题进入网站,浏览尽可能多的广告。标题党文章质量通常较低,除了最初的好奇心外,无法为读者提供有价值的信息。这种现象破坏了公众对新闻来源的信任,并对合法内容创作者的广告收入产生负面影响,可能导致他们的网站流量减少。
我们使用 NoticIA 数据集对模型进行训练,该数据集包含 850 篇带有标题党标题的西班牙语新闻文章,每篇文章都配有由人工撰写的高质量单句生成摘要。这项任务需要先进的文本理解和摘要生成技能,对模型推断和连接各种信息以满足用户因标题党标题而产生的信息好奇心的能力提出了挑战。
训练过程
为了训练模型,我们开发了自己的训练和标注库:https://github.com/ikergarcia1996/NoticIA。该库使用了 🤗 Transformers、🤗 PEFT、Bitsandbytes 和 Deepspeed。
在 Hackathon 中,我们决定训练一个具有 7 万亿参数的模型,因为使用 4 位量化技术,可以在家用硬件上运行该模型。在分析了大量大语言模型的性能后,我们选择了 openchat-3.5-0106,因为它无需预训练就能表现出色。为了尽量不干扰使模型具备这种性能的先验知识,我们选择使用 低秩自适应(LoRA)训练技术。
训练超参数
- 训练模式:bfloat16
- 训练方法:LoRA + Deepspeed Zero3
- 批量大小:64
- 序列长度:8192
- 训练轮数:3
- 优化器:AdamW
- 软件:Huggingface、Peft、Pytorch、Deepspeed
具体的训练配置可在 https://huggingface.co/somosnlp/NoticIA-7B/blob/main/openchat-3.5-0106_LoRA.yaml 查看。
评估
测试数据、因素和指标
- 测试数据:我们使用 NoticIA-it 数据集的测试集:https://huggingface.co/datasets/somosnlp/NoticIA-it。
- 提示:训练使用的提示与 https://huggingface.co/datasets/somosnlp/NoticIA-it 中定义和解释的相同。提示会转换为每个模型特定的聊天模板。
- 指标:在摘要任务中,我们通常使用 ROUGE 评分指标来自动评估模型生成的摘要。我们的主要指标是 ROUGE-1,它以整个单词为基本单位。为了计算 ROUGE 分数,我们将两个摘要都转换为小写并去除标点符号。除了 ROUGE 分数,我们还考虑摘要的平均长度。对于我们的任务,我们希望摘要简洁明了,而 ROUGE 分数无法评估这一方面。因此,在评估模型时,我们同时考虑 ROUGE-1 分数和摘要的平均长度。我们的目标是找到一个能够在最短的摘要长度下获得尽可能高的 ROUGE 分数的模型,以平衡质量和简洁性。
结果
我们评估了目前训练的最佳指令跟随语言模型,并纳入了人类标注员的表现。重现结果的代码可在以下链接获取:https://github.com/ikergarcia1996/NoticIA。
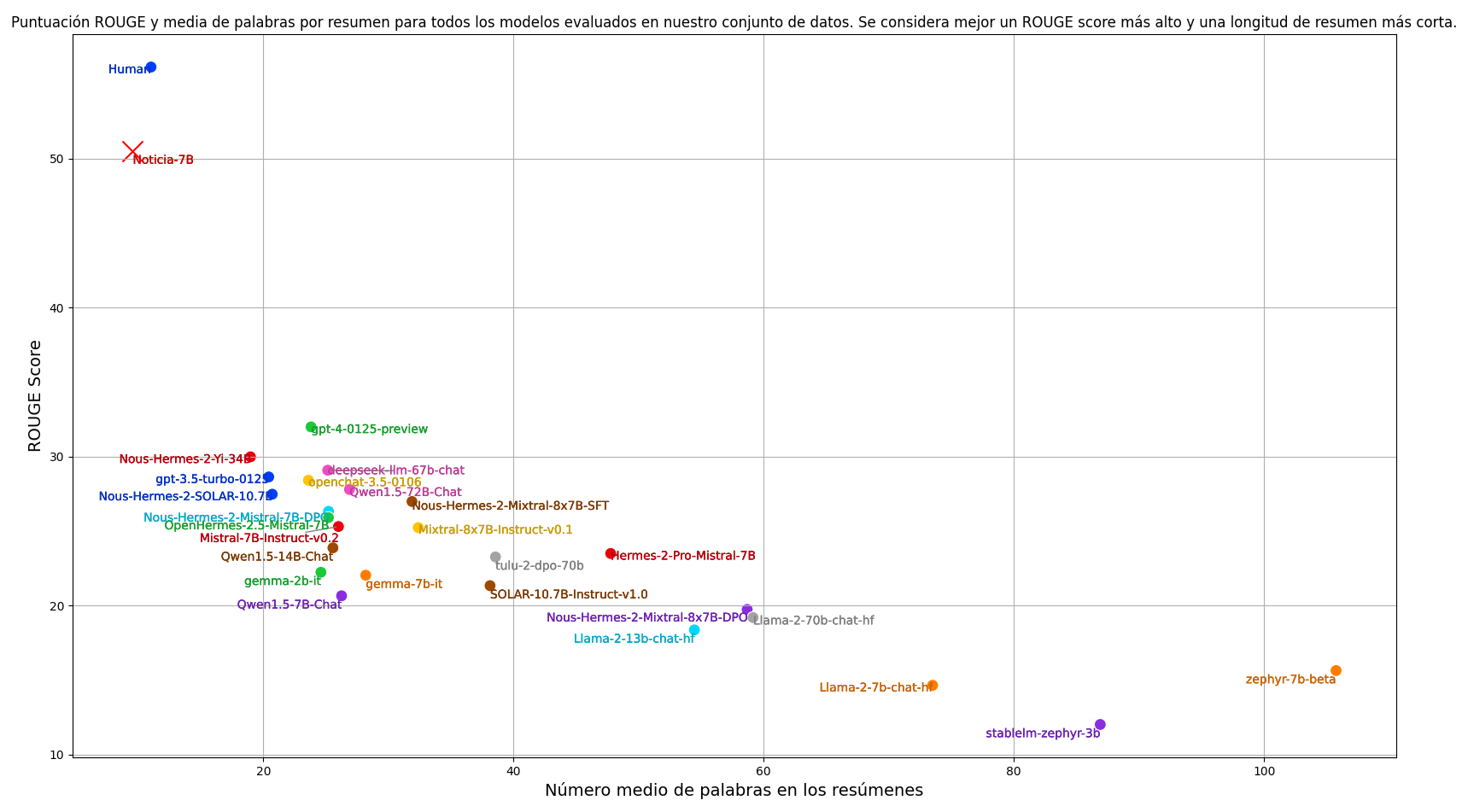
训练后,我们的模型具备了接近人类的摘要生成能力,显著优于任何零样本设置下的模型。同时,模型生成的摘要更加简洁。
环境影响
在估算碳足迹时,我们考虑了每个 GPU 400W 的功耗和 0.083 kg/kWh 的碳强度:https://app.electricitymaps.com/map。
- 硬件类型:4 个 Nvidia A100 80Gb GPU
- 使用时长:2 小时
- 计算区域:西班牙巴斯克地区多诺斯蒂亚
- 碳排放:0.3984 kg Co2
模型架构和目标
该模型为仅解码器架构,经过指令预训练。我们使用标准的下一个令牌预测(NTP)损失来训练模型。为了防止文章正文令牌的损失掩盖摘要输出令牌的损失,我们仅对摘要令牌计算损失。
计算基础设施
我们在配备四个 NVIDIA A100 GPU(每个 GPU 具有 80GB 内存)的机器上进行了所有实验,这些 GPU 通过 NVLink 互连。该机器配备了两个 AMD EPYC 7513 32 核处理器和 1TB(1024GB)的 RAM。
软件
- Huggingface Transformers:https://github.com/huggingface/transformers
- PEFT:https://github.com/huggingface/peft
- Deepspeed:https://github.com/microsoft/DeepSpeed
- Pytorch:https://pytorch.org/
我们的代码可在 https://github.com/ikergarcia1996/NoticIA 找到。
🔧 技术细节
模型输入输出
- 输入:文章标题和正文,通过特定的提示模板进行格式化。
- 输出:单句摘要,揭示标题背后的真实内容。
训练技术
使用 LoRA 技术进行微调,结合 Deepspeed Zero3 优化内存使用,提高训练效率。
量化技术
采用 4 位量化技术(BitsAndBytesConfig),减少模型内存占用,使模型能够在普通硬件上运行。
📄 许可证
本模型采用 Apache 2.0 许可证发布。
引用
如果您使用此数据集,请引用我们的论文:NoticIA: A Clickbait Article Summarization Dataset in Spanish
BibTeX:
@misc{garcíaferrero2024noticia,
title={NoticIA: A Clickbait Article Summarization Dataset in Spanish},
author={Iker García-Ferrero and Begoña Altuna},
year={2024},
eprint={2404.07611},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
更多信息
本项目是在 SomosNLP 组织的 Hackathon #Somos600M 期间开发的。演示端点由 HuggingFace 赞助。
团队成员:
联系方式:{iker.garciaf,begona.altuna}@ehu.eus
本数据集由 Iker García-Ferrero 和 Begoña Altuna 创建。我们是巴斯克大学自然语言处理领域的研究人员,隶属于 IXA 研究小组,也是 HiTZ,巴斯克语言技术中心 的成员。