%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 NoticIA-7B:用於西班牙語標題黨文章摘要生成的模型
NoticIA-7B 是一個擁有 70 億參數的模型,它基於 NoticIA-it 數據集進行訓練,能夠為標題黨文章生成簡潔且高質量的摘要,有助於揭示標題背後的真實內容。
![]()
🚀 快速開始
對網頁上的標題黨文章進行摘要生成
以下代碼展示瞭如何使用模板從標題黨文章的 URL 生成摘要:
import torch # pip install torch
from newspaper import Article #pip3 install newspaper3k
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
article_url ="https://www.huffingtonpost.es/virales/le-compra-abrigo-abuela-97nos-reaccion-fantasia.html"
article = Article(article_url)
article.download()
article.parse()
headline=article.title
body = article.text
def prompt(
headline: str,
body: str,
) -> str:
"""
Generate the prompt for the model.
Args:
headline (`str`):
The headline of the article.
body (`str`):
The body of the article.
Returns:
`str`: The formatted prompt.
"""
return (
f"Ahora eres una Inteligencia Artificial experta en desmontar titulares sensacionalistas o clickbait. "
f"Tu tarea consiste en analizar noticias con titulares sensacionalistas y "
f"generar un resumen de una sola frase que revele la verdad detrás del titular.\n"
f"Este es el titular de la noticia: {headline}\n"
f"El titular plantea una pregunta o proporciona información incompleta. "
f"Debes buscar en el cuerpo de la noticia una frase que responda lo que se sugiere en el título. "
f"Siempre que puedas cita el texto original, especialmente si se trata de una frase que alguien ha dicho. "
f"Si citas una frase que alguien ha dicho, usa comillas para indicar que es una cita. "
f"Usa siempre las mínimas palabras posibles. No es necesario que la respuesta sea una oración completa. "
f"Puede ser sólo el foco de la pregunta. "
f"Recuerda responder siempre en Español.\n"
f"Este es el cuerpo de la noticia:\n"
f"{body}\n"
)
prompt = prompt(headline=headline, body=body)
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto", quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
在 NoticIA 數據集上進行推理
以下代碼展示瞭如何在數據集的示例上進行推理:
import torch # pip install torch
from datasets import load_dataset # pip install datasets
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
dataset = load_dataset("somosnlp/NoticIA-it",split="test")
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto", quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": dataset[0]["pregunta"]}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
✨ 主要特性
- 精準摘要:能夠準確分析標題黨文章,生成揭示標題背後真實內容的單句摘要。
- 多場景適用:可用於網頁文章摘要生成和數據集推理。
- 性能優良:在 ROUGE 指標上表現出色,生成的摘要簡潔明瞭。
📦 安裝指南
運行代碼前,需要安裝以下依賴庫:
pip install torch
pip3 install newspaper3k
pip install transformers
pip install bitsandbytes
pip install datasets
📚 詳細文檔
模型詳情
模型描述
標題黨文章通過引發讀者的好奇心來吸引其注意力,標題通常會提出問題或給出不完整、聳人聽聞、誇張或誤導性的陳述。文章中問題的答案往往在大量無關內容之後才出現,其目的是讓用戶通過標題進入網站,瀏覽儘可能多的廣告。標題黨文章質量通常較低,除了最初的好奇心外,無法為讀者提供有價值的信息。這種現象破壞了公眾對新聞來源的信任,並對合法內容創作者的廣告收入產生負面影響,可能導致他們的網站流量減少。
我們推出的 NoticIA-7B 模型擁有 70 億參數,基於 NoticIA-it 數據集進行訓練,能夠為標題黨文章生成簡潔且高質量的摘要。
- 開發者:Iker García-Ferrero、Begoña Altuna
- 資助方:SomosNLP、HuggingFace、HiTZ Zentroa
- 模型類型:語言模型,經過指令微調
- 語言:西班牙語(西班牙)
- 許可證:Apache-2.0
- 微調基礎模型:openchat/openchat-3.5-0106
- 使用的數據集:https://huggingface.co/datasets/somosnlp/NoticIA-it
模型來源
- 💻 代碼倉庫
- 📖 論文:NoticIA: A Clickbait Article Summarization Dataset in Spanish
- 🤖 數據集和預訓練模型
- 🔌 演示
- ▶️ 視頻介紹(西班牙語)
- 🐱💻 Hackathon #Somos600M
用途
直接用途
- 📖 對標題黨文章進行摘要生成
- 📈 評估西班牙語語言模型
- 📚 開發新的學術資源(如合成數據生成)
- 🎓 用於其他學術研究目的
超出適用範圍的用途
禁止使用此模型進行任何可能損害合法專業媒體機構合法性或經濟可行性的行為。
偏差、風險和侷限性
該模型主要使用來自西班牙的西班牙語新聞進行訓練,數據標註人員也來自西班牙。因此,我們預計該模型在處理西班牙西班牙語新聞時表現良好,但不能保證其在處理拉丁美洲新聞或其他語言的新聞時也能有出色的表現。
訓練詳情
訓練數據
標題黨文章旨在通過引發讀者的好奇心來吸引其注意力。為此,標題通常會提出問題或給出不完整、聳人聽聞、誇張或誤導性的陳述。文章中問題的答案往往在大量無關內容之後才出現,其目的是讓用戶通過標題進入網站,瀏覽儘可能多的廣告。標題黨文章質量通常較低,除了最初的好奇心外,無法為讀者提供有價值的信息。這種現象破壞了公眾對新聞來源的信任,並對合法內容創作者的廣告收入產生負面影響,可能導致他們的網站流量減少。
我們使用 NoticIA 數據集對模型進行訓練,該數據集包含 850 篇帶有標題黨標題的西班牙語新聞文章,每篇文章都配有由人工撰寫的高質量單句生成摘要。這項任務需要先進的文本理解和摘要生成技能,對模型推斷和連接各種信息以滿足用戶因標題黨標題而產生的信息好奇心的能力提出了挑戰。
訓練過程
為了訓練模型,我們開發了自己的訓練和標註庫:https://github.com/ikergarcia1996/NoticIA。該庫使用了 🤗 Transformers、🤗 PEFT、Bitsandbytes 和 Deepspeed。
在 Hackathon 中,我們決定訓練一個具有 7 萬億參數的模型,因為使用 4 位量化技術,可以在家用硬件上運行該模型。在分析了大量大語言模型的性能後,我們選擇了 openchat-3.5-0106,因為它無需預訓練就能表現出色。為了儘量不干擾使模型具備這種性能的先驗知識,我們選擇使用 低秩自適應(LoRA)訓練技術。
訓練超參數
- 訓練模式:bfloat16
- 訓練方法:LoRA + Deepspeed Zero3
- 批量大小:64
- 序列長度:8192
- 訓練輪數:3
- 優化器:AdamW
- 軟件:Huggingface、Peft、Pytorch、Deepspeed
具體的訓練配置可在 https://huggingface.co/somosnlp/NoticIA-7B/blob/main/openchat-3.5-0106_LoRA.yaml 查看。
評估
測試數據、因素和指標
- 測試數據:我們使用 NoticIA-it 數據集的測試集:https://huggingface.co/datasets/somosnlp/NoticIA-it。
- 提示:訓練使用的提示與 https://huggingface.co/datasets/somosnlp/NoticIA-it 中定義和解釋的相同。提示會轉換為每個模型特定的聊天模板。
- 指標:在摘要任務中,我們通常使用 ROUGE 評分指標來自動評估模型生成的摘要。我們的主要指標是 ROUGE-1,它以整個單詞為基本單位。為了計算 ROUGE 分數,我們將兩個摘要都轉換為小寫並去除標點符號。除了 ROUGE 分數,我們還考慮摘要的平均長度。對於我們的任務,我們希望摘要簡潔明瞭,而 ROUGE 分數無法評估這一方面。因此,在評估模型時,我們同時考慮 ROUGE-1 分數和摘要的平均長度。我們的目標是找到一個能夠在最短的摘要長度下獲得儘可能高的 ROUGE 分數的模型,以平衡質量和簡潔性。
結果
我們評估了目前訓練的最佳指令跟隨語言模型,並納入了人類標註員的表現。重現結果的代碼可在以下鏈接獲取:https://github.com/ikergarcia1996/NoticIA。
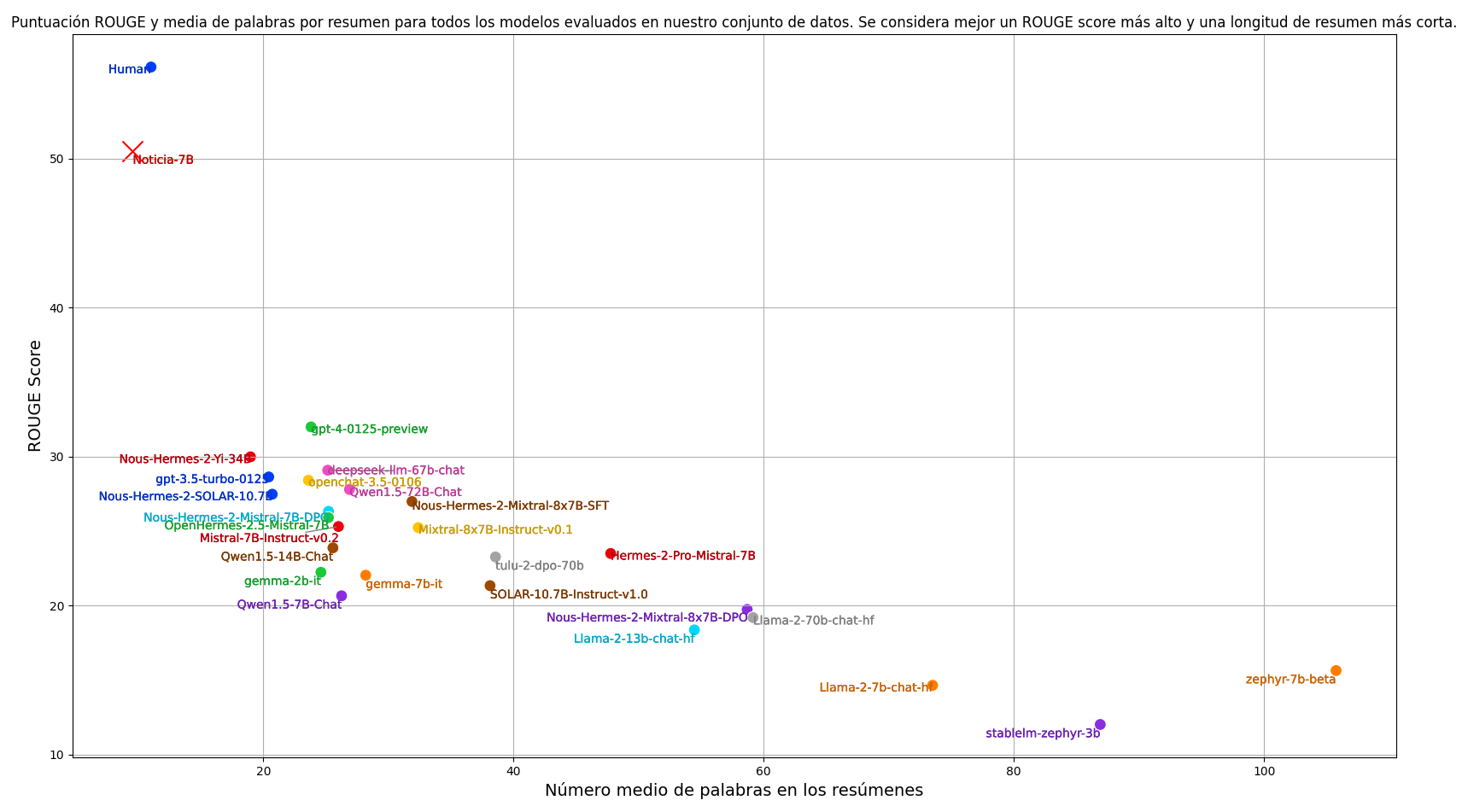
訓練後,我們的模型具備了接近人類的摘要生成能力,顯著優於任何零樣本設置下的模型。同時,模型生成的摘要更加簡潔。
環境影響
在估算碳足跡時,我們考慮了每個 GPU 400W 的功耗和 0.083 kg/kWh 的碳強度:https://app.electricitymaps.com/map。
- 硬件類型:4 個 Nvidia A100 80Gb GPU
- 使用時長:2 小時
- 計算區域:西班牙巴斯克地區多諾斯蒂亞
- 碳排放:0.3984 kg Co2
模型架構和目標
該模型為僅解碼器架構,經過指令預訓練。我們使用標準的下一個令牌預測(NTP)損失來訓練模型。為了防止文章正文令牌的損失掩蓋摘要輸出令牌的損失,我們僅對摘要令牌計算損失。
計算基礎設施
我們在配備四個 NVIDIA A100 GPU(每個 GPU 具有 80GB 內存)的機器上進行了所有實驗,這些 GPU 通過 NVLink 互連。該機器配備了兩個 AMD EPYC 7513 32 核處理器和 1TB(1024GB)的 RAM。
軟件
- Huggingface Transformers:https://github.com/huggingface/transformers
- PEFT:https://github.com/huggingface/peft
- Deepspeed:https://github.com/microsoft/DeepSpeed
- Pytorch:https://pytorch.org/
我們的代碼可在 https://github.com/ikergarcia1996/NoticIA 找到。
🔧 技術細節
模型輸入輸出
- 輸入:文章標題和正文,通過特定的提示模板進行格式化。
- 輸出:單句摘要,揭示標題背後的真實內容。
訓練技術
使用 LoRA 技術進行微調,結合 Deepspeed Zero3 優化內存使用,提高訓練效率。
量化技術
採用 4 位量化技術(BitsAndBytesConfig),減少模型內存佔用,使模型能夠在普通硬件上運行。
📄 許可證
本模型採用 Apache 2.0 許可證發佈。
引用
如果您使用此數據集,請引用我們的論文:NoticIA: A Clickbait Article Summarization Dataset in Spanish
BibTeX:
@misc{garcíaferrero2024noticia,
title={NoticIA: A Clickbait Article Summarization Dataset in Spanish},
author={Iker García-Ferrero and Begoña Altuna},
year={2024},
eprint={2404.07611},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
更多信息
本項目是在 SomosNLP 組織的 Hackathon #Somos600M 期間開發的。演示端點由 HuggingFace 贊助。
團隊成員:
聯繫方式:{iker.garciaf,begona.altuna}@ehu.eus
本數據集由 Iker García-Ferrero 和 Begoña Altuna 創建。我們是巴斯克大學自然語言處理領域的研究人員,隸屬於 IXA 研究小組,也是 HiTZ,巴斯克語言技術中心 的成員。