%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 NoticIA-7B:スペイン語のクリックバait記事要約用モデル
NoticIA-7Bは、スペイン語のクリックバイト記事を要約するためのモデルです。このモデルは、クリックバイト記事のタイトルに隠された真実を明らかにするための要約を生成することができます。
🚀 クイックスタート
ウェブ上のクリックバイト記事の要約を作成する
以下のコードは、クリックバイト記事のURLから要約を生成するためのテンプレートの使用例を示しています。
import torch # pip install torch
from newspaper import Article #pip3 install newspaper3k
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
article_url ="https://www.huffingtonpost.es/virales/le-compra-abrigo-abuela-97nos-reaccion-fantasia.html"
article = Article(article_url)
article.download()
article.parse()
headline=article.title
body = article.text
def prompt(
headline: str,
body: str,
) -> str:
"""
Generate the prompt for the model.
Args:
headline (`str`):
The headline of the article.
body (`str`):
The body of the article.
Returns:
`str`: The formatted prompt.
"""
return (
f"Ahora eres una Inteligencia Artificial experta en desmontar titulares sensacionalistas o clickbait. "
f"Tu tarea consiste en analizar noticias con titulares sensacionalistas y "
f"generar un resumen de una sola frase que revele la verdad detrás del titular.\n"
f"Este es el titular de la noticia: {headline}\n"
f"El titular plantea una pregunta o proporciona información incompleta. "
f"Debes buscar en el cuerpo de la noticia una frase que responda lo que se sugiere en el título. "
f"Siempre que puedas cita el texto original, especialmente si se trata de una frase que alguien ha dicho. "
f"Si citas una frase que alguien ha dicho, usa comillas para indicar que es una cita. "
f"Usa siempre las mínimas palabras posibles. No es necesario que la respuesta sea una oración completa. "
f"Puede ser sólo el foco de la pregunta. "
f"Recuerda responder siempre en Español.\n"
f"Este es el cuerpo de la noticia:\n"
f"{body}\n"
)
prompt = prompt(headline=headline, body=body)
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto", quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
NoticIAデータセットで推論を行う
以下のコードは、データセットの例に対して推論を行う方法の例を示しています。
import torch # pip install torch
from datasets import load_dataset # pip install datasets
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
dataset = load_dataset("somosnlp/NoticIA-it",split="test")
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto", quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": dataset[0]["pregunta"]}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
✨ 主な機能
- スペイン語のクリックバイト記事の要約を生成することができます。
- 科学的な研究に使用でき、特にタスク固有のモデルのパフォーマンスを評価するために使用できます。
- 個人がクリックバイト記事を要約するために使用できます。
📦 インストール
コード例に記載されているライブラリをインストールする必要があります。
pip install torch
pip3 install newspaper3k
pip install transformers
pip install bitsandbytes
pip install datasets
📚 ドキュメント
モデルの詳細
モデルの説明
クリックバイト記事は、読者の好奇心を引くことを目的として、タイトルに質問や不完全な、煽情的な、誇張された、または誤解を招く声明を含んでいます。質問の答えは通常、大量の関係ない内容の後に記事の最後に現れます。この目的は、読者がタイトルを通じてウェブサイトにアクセスし、できるだけ多くの広告を閲覧するようにすることです。クリックバイト記事は一般的に低品質で、読者にとって最初の好奇心を超えた価値を提供しません。この現象は、ニュースソースに対する公衆の信頼を損ない、正当なコンテンツ作成者の広告収入に悪影響を与えます。
このモデルは、70億のパラメータを持ち、NoticIA-itデータセットで訓練されています。このモデルは、クリックバイト記事の簡潔で高品質の要約を生成することができます。
| 属性 | 詳情 |
|---|---|
| 開発者 | Iker García-Ferrero、Begoña Altuna |
| 資金提供元 | SomosNLP、HuggingFace、HiTZ Zentroa |
| モデルタイプ | 言語モデル、命令調整済み |
| 言語 | es-ES |
| ライセンス | apache-2.0 |
| ファインチューニング元のモデル | openchat/openchat-3.5-0106 |
| 使用データセット | https://huggingface.co/datasets/somosnlp/NoticIA-it |
モデルのソース
- 💻 リポジトリ:https://github.com/ikergarcia1996/NoticIA
- 📖 論文:NoticIA: A Clickbait Article Summarization Dataset in Spanish
- 🤖 データセットと事前学習モデル:https://huggingface.co/collections/Iker/noticia-and-clickbaitfighter-65fdb2f80c34d7c063d3e48e
- 🔌 デモ:https://huggingface.co/spaces/somosnlp/NoticIA-demo
- ▶️ 動画紹介 (スペイン語):https://youtu.be/xc60K_NzUgk?si=QMqk6OzQZfKP1EUS
- 🐱💻 ハッカソン #Somos600M:https://somosnlp.org/hackathon
使用方法
直接的な使用
- 📖 クリックバイト記事の要約
- 📈 スペイン語の言語モデルの評価
- 📚 新しい学術資源の開発(例:合成データの生成)
- 🎓 その他の学術研究目的
範囲外の使用
このモデルを、正当な専門的なメディアの正当性や経済的な存続可能性を害するような行為に使用することは禁止されています。
バイアス、リスク、および制限
このモデルは主にスペインのスペイン語ニュースで訓練されており、データのアノテーターもスペイン出身です。したがって、このモデルはスペインのスペイン語に精通していることが期待されます。ただし、ラテンアメリカのニュースや他の言語のニュースでのパフォーマンスを保証することはできません。
学習の詳細
学習データ
クリックバイト記事は、読者の好奇心を引くことを目的として、タイトルに質問や不完全な、煽情的な、誇張された、または誤解を招く声明を含んでいます。質問の答えは通常、大量の関係ない内容の後に記事の最後に現れます。この目的は、読者がタイトルを通じてウェブサイトにアクセスし、できるだけ多くの広告を閲覧するようにすることです。クリックバイト記事は一般的に低品質で、読者にとって最初の好奇心を超えた価値を提供しません。この現象は、ニュースソースに対する公衆の信頼を損ない、正当なコンテンツ作成者の広告収入に悪影響を与えます。
このモデルは、NoticIAデータセットで訓練されています。このデータセットは、850のスペイン語のクリックバイト記事と、それぞれに対応する高品質の1文の要約で構成されています。
学習手順
モデルを学習するために、独自の学習とアノテーションライブラリを開発しました:https://github.com/ikergarcia1996/NoticIA。このライブラリは、🤗 Transformers、🤗 PEFT、Bitsandbytes、およびDeepspeedを利用しています。
ハッカソンでは、4ビット量子化を使用することで家庭用ハードウェアで実行できる7兆パラメータのモデルを学習することにしました。多数の大規模言語モデルのパフォーマンスを分析した後、事前学習が不要で高いパフォーマンスを示すopenchat-3.5-0106を選択しました。このパフォーマンスを可能にするモデルの事前知識を最小限に乱すために、Low-Rank Adaptation (LoRA)学習手法を使用することにしました。
学習ハイパーパラメータ
- 学習レジーム:bfloat16
- 学習方法:LoRA + Deepspeed Zero3
- バッチサイズ:64
- シーケンス長:8192
- エポック数:3
- オプティマイザ:AdamW
- ソフトウェア:Huggingface、Peft、Pytorch、Deepspeed
正確な学習設定は、以下のリンクで確認できます:https://huggingface.co/somosnlp/NoticIA-7B/blob/main/openchat-3.5-0106_LoRA.yaml
評価
テストデータ、要因、およびメトリクス
テストデータ
NoticIA-itデータセットのテスト分割を使用しています:https://huggingface.co/datasets/somosnlp/NoticIA-it
プロンプト
学習に使用されるプロンプトは、https://huggingface.co/datasets/somosnlp/NoticIA-itで定義され説明されているものと同じです。プロンプトは、各モデルに固有のチャットテンプレートに変換されます。
メトリクス
要約タスクで一般的に使用されるように、このモデルの評価にはROUGEスコアリングメトリクスを使用しています。主なメトリクスはROUGE-1で、単語を基本単位として考慮します。ROUGEスコアを計算する際には、両方の要約を小文字に変換し、句読点を削除します。ROUGEスコアに加えて、要約の平均長も考慮しています。このタスクでは、要約が簡潔であることが目標であり、これはROUGEスコアでは評価されない側面です。したがって、モデルを評価する際には、ROUGE-1スコアと要約の平均長の両方を考慮しています。目標は、できるだけ高いROUGEスコアを達成しながら、できるだけ短い要約長を実現するモデルを見つけることです。
結果
現在の命令に従うように訓練された最高の言語モデルを評価し、人間のアノテーターによるパフォーマンスも含めました。結果を再現するためのコードは、以下のリンクで入手できます:https://github.com/ikergarcia1996/NoticIA
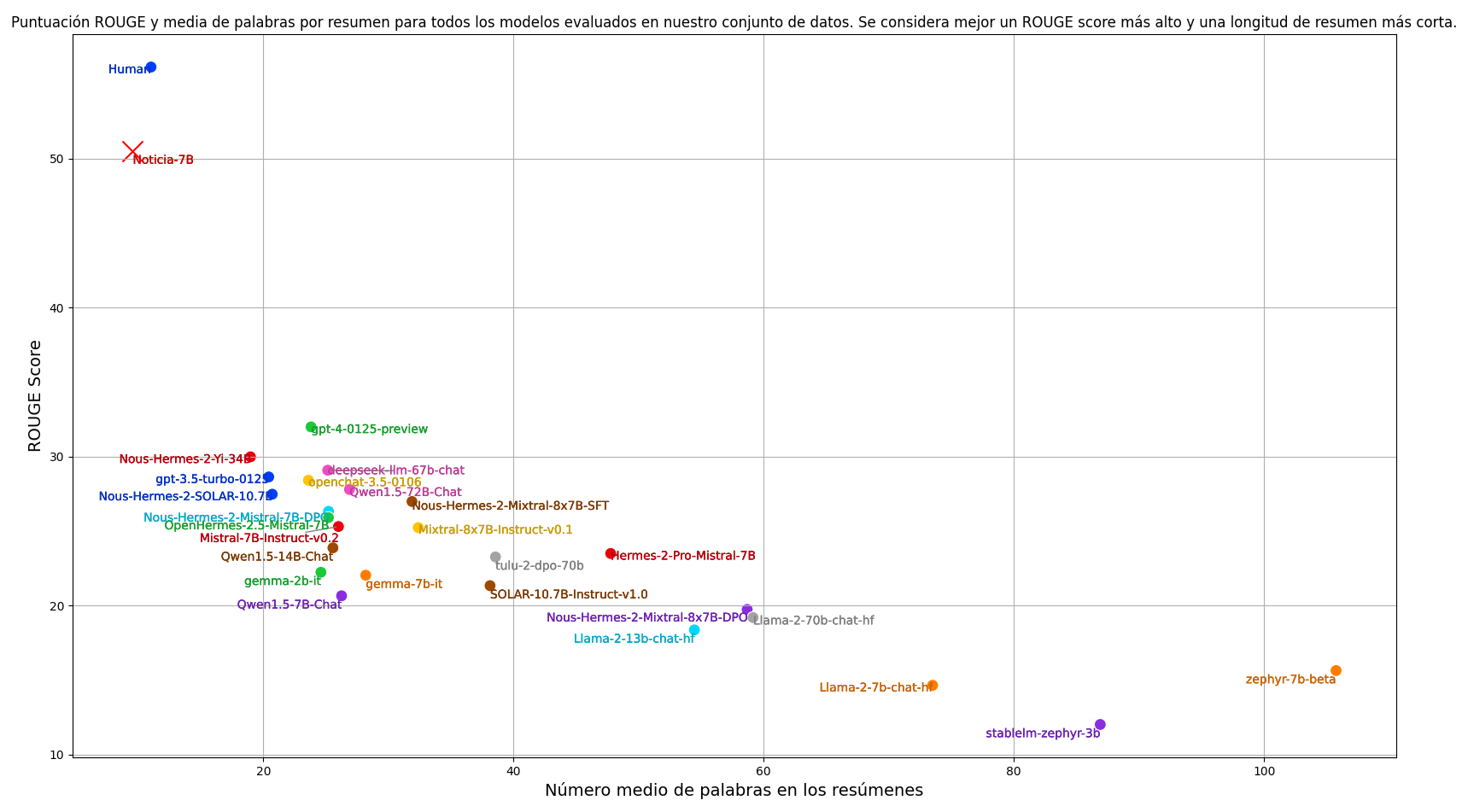
学習後、このモデルは人間に近い能力で要約を行うことができ、ゼロショット設定のどのモデルをも大きく上回っています。同時に、このモデルはより簡潔な要約を生成します。
📄 ライセンス
このモデルは、Apache 2.0ライセンスの下で提供されています。