%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 UL2:通用预训练模型框架
UL2 是一个用于预训练模型的统一框架,该框架在不同数据集和设置下都具有普遍有效性。它采用了混合去噪器(Mixture-of-Denoisers,MoD)这一预训练目标,将多种不同的预训练范式结合在一起。此外,UL2 还引入了模式切换的概念,即下游微调与特定的预训练方案相关联。

📚 详细文档
摘要
现有的预训练模型通常针对特定类型的问题。到目前为止,对于何种架构和预训练设置才是正确的,似乎仍未达成共识。本文提出了一个用于预训练模型的统一框架,该框架在不同数据集和设置下都具有普遍有效性。我们首先将架构原型与预训练目标这两个常被混淆的概念分离开来。接着,我们提出了一个用于自然语言处理(NLP)自监督学习的广义统一视角,并展示了不同的预训练目标如何相互转换,以及在不同目标之间进行插值为何会有效。然后,我们提出了混合去噪器(MoD)这一预训练目标,它将多种不同的预训练范式结合在一起。此外,我们还引入了模式切换的概念,即下游微调与特定的预训练方案相关联。我们进行了广泛的消融实验,以比较多种预训练目标,并发现我们的方法在多个不同设置下优于 T5 和/或类似 GPT 的模型,推动了帕累托前沿。最后,通过将我们的模型扩展到 200 亿参数,我们在 50 个成熟的有监督 NLP 任务上取得了最先进的性能,这些任务涵盖了语言生成(包括自动和人工评估)、语言理解、文本分类、问答、常识推理、长文本推理、结构化知识接地和信息检索等领域。我们的模型在上下文学习方面也取得了显著成果,在零样本 SuperGLUE 任务上优于 1750 亿参数的 GPT - 3,并在单样本摘要任务上使 T5 - XXL 的性能提升了两倍。
更多信息,请查看原论文。
论文:Unifying Language Learning Paradigms
作者:Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
🔧 技术细节
训练
该模型的检查点在 C4 数据集上进行迭代预训练,并在多种数据集上进行微调。
预训练
模型在 C4 语料库上进行预训练。预训练时,模型在 C4 上总共处理 1 万亿个标记(200 万步),批量大小为 1024。输入和目标的序列长度均设置为 512/512。预训练期间,丢弃率设置为 0。对于约 1 万亿个标记的预训练,大约花费了一个多月的时间。该模型有 32 个编码器层和 32 个解码器层,dmodel 为 4096,df 为 16384。每个头的维度为 256,总共 16 个头。我们的模型使用了 8 路模型并行。使用与 T5 相同的 SentencePiece 分词器,词汇量大小为 32000(点击 此处 了解更多关于 T5 分词器的信息)。
UL - 20B 可以被看作是一个与 T5 非常相似的模型,但使用了不同的训练目标和略有不同的缩放旋钮。UL - 20B 使用 Jax 和 T5X 基础设施进行训练。
预训练期间的训练目标是多种不同去噪策略的混合,具体如下:
混合去噪器
引用论文中的内容:
我们推测,一个强大的通用模型在预训练期间必须接触并解决各种不同的问题。鉴于预训练是通过自监督学习完成的,我们认为应该将这种多样性注入到模型的目标中,否则模型可能会缺乏某些能力,例如长连贯文本生成能力。 基于此,以及当前的目标函数类别,我们定义了预训练期间使用的三种主要范式:
- R - 去噪器:常规去噪是 T5 中引入的标准跨度损坏方法,使用 2 到 5 个标记作为跨度长度,大约掩盖输入标记的 15%。这些跨度较短,可能有助于获取知识,而不是学习生成流畅的文本。
- S - 去噪器:这是一种特殊的去噪情况,在构建输入到目标的任务时,我们遵循严格的顺序,即前缀语言建模。为此,我们只需将输入序列划分为两个子标记序列,分别作为上下文和目标,使得目标不依赖于未来信息。这与标准的跨度损坏不同,在标准跨度损坏中,可能存在目标标记的位置早于上下文标记的情况。请注意,与前缀语言模型(Prefix - LM)设置类似,上下文(前缀)保留了双向感受野。我们注意到,具有非常短记忆或无记忆的 S - 去噪与标准的因果语言建模在本质上是相似的。
- X - 去噪器:这是一种极端的去噪版本,模型必须根据输入的一小部分到中等部分恢复输入的大部分内容。这模拟了模型需要从信息相对有限的记忆中生成较长目标的情况。为此,我们选择包含激进去噪的示例,其中大约 50% 的输入序列被掩盖。这可以通过增加跨度长度和/或损坏率来实现。如果预训练任务具有较长的跨度(例如,≥ 12 个标记)或较大的损坏率(例如,≥ 30%),我们认为该任务是极端的。X - 去噪的动机是在常规跨度损坏和类似语言模型的目标之间进行插值。
请参考以下图表以获得更直观的解释:
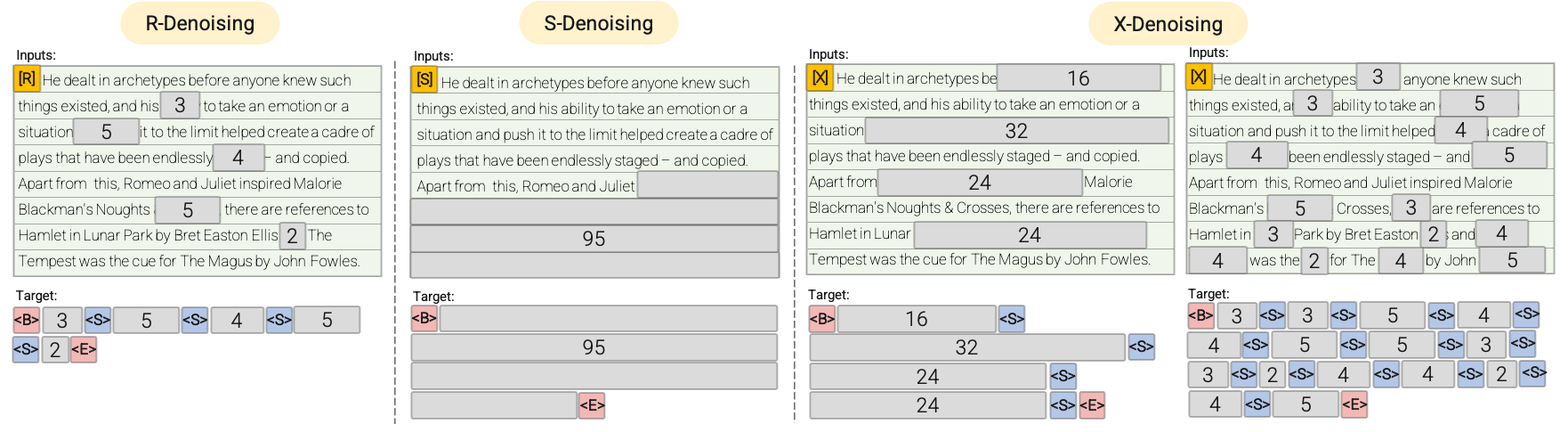
重要提示:更多详细信息,请参阅论文 Unifying Language Learning Paradigms 的 3.1.2 节。
微调
模型在 N 次预训练步骤后进行连续微调,其中 N 通常在 50k 到 100k 之间。换句话说,在每次 Nk 步的预训练之后,模型会在每个下游任务上进行微调。请参阅论文 Unifying Language Learning Paradigms 的 5.2.2 节以了解用于微调的所有数据集的概述。
由于模型是连续微调的,一旦某个任务达到了最先进的性能,就会停止在该任务上的微调,以节省计算资源。模型总共训练了 265 万步。
重要提示:更多详细信息,请参阅论文 Unifying Language Learning Paradigms 的 5.2.1 和 5.2.2 节。
💻 使用示例
基础用法
以下展示了如何使用不同的去噪策略来预测掩码段落。由于模型规模较大,以下示例需要在至少 40GB 的 A100 GPU 上运行。
S - 去噪
对于 S - 去噪,请确保按照以下方式在文本前添加前缀 [S2S]。
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[S2S] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man with a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere <extra_id_0>"
inputs = tokenizer(input_string, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> <pad>. Dudley was a very good boy, but he was also very stupid.</s>
R - 去噪
对于 R - 去噪,请确保按照以下方式在文本前添加前缀 [NLU]。
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLU] Mr. Dursley was the director of a firm called <extra_id_0>, which made <extra_id_1>. He was a big, solid man with a bald head. Mrs. Dursley was thin and <extra_id_2> of neck, which came in very useful as she spent so much of her time <extra_id_3>. The Dursleys had a small son called Dudley and <extra_id_4>"
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> brooms for witches and wizards<extra_id_2> had a lot<extra_id_3> scolding Dudley<extra_id_4> a daughter called Petunia. Dudley was a nasty, spoiled little boy who was always getting into trouble. He was very fond of his pet rat, Scabbers.<extra_id_5> Burrows<extra_id_3> screaming at him<extra_id_4> a daughter called Petunia</s>
"
X - 去噪
对于 X - 去噪,请确保按照以下方式在文本前添加前缀 [NLG]。
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLG] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man wiht a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she
spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere. <extra_id_0>"
model.cuda()
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> a lot of money from the manufacture of a product called '' Burrows'''s ''<extra_id_2> had a lot<extra_id_3> looking down people's throats<extra_id_4> a daughter called Petunia. Dudley was a very stupid boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat,"
📄 许可证
本模型采用 Apache - 2.0 许可证。
贡献者
此模型由 Daniel Hesslow 贡献。
信息表格
| 属性 | 详情 |
|---|---|
| 模型类型 | UL2 是一个用于预训练模型的统一框架,采用混合去噪器(MoD)预训练目标,结合多种预训练范式,并引入模式切换概念。 |
| 训练数据 | 模型在 C4 语料库上进行预训练,在多种数据集上进行微调。 |