%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 UL2:通用預訓練模型框架
UL2 是一個用於預訓練模型的統一框架,該框架在不同數據集和設置下都具有普遍有效性。它採用了混合去噪器(Mixture-of-Denoisers,MoD)這一預訓練目標,將多種不同的預訓練範式結合在一起。此外,UL2 還引入了模式切換的概念,即下游微調與特定的預訓練方案相關聯。

📚 詳細文檔
摘要
現有的預訓練模型通常針對特定類型的問題。到目前為止,對於何種架構和預訓練設置才是正確的,似乎仍未達成共識。本文提出了一個用於預訓練模型的統一框架,該框架在不同數據集和設置下都具有普遍有效性。我們首先將架構原型與預訓練目標這兩個常被混淆的概念分離開來。接著,我們提出了一個用於自然語言處理(NLP)自監督學習的廣義統一視角,並展示了不同的預訓練目標如何相互轉換,以及在不同目標之間進行插值為何會有效。然後,我們提出了混合去噪器(MoD)這一預訓練目標,它將多種不同的預訓練範式結合在一起。此外,我們還引入了模式切換的概念,即下游微調與特定的預訓練方案相關聯。我們進行了廣泛的消融實驗,以比較多種預訓練目標,並發現我們的方法在多個不同設置下優於 T5 和/或類似 GPT 的模型,推動了帕累託前沿。最後,通過將我們的模型擴展到 200 億參數,我們在 50 個成熟的有監督 NLP 任務上取得了最先進的性能,這些任務涵蓋了語言生成(包括自動和人工評估)、語言理解、文本分類、問答、常識推理、長文本推理、結構化知識接地和信息檢索等領域。我們的模型在上下文學習方面也取得了顯著成果,在零樣本 SuperGLUE 任務上優於 1750 億參數的 GPT - 3,並在單樣本摘要任務上使 T5 - XXL 的性能提升了兩倍。
更多信息,請查看原論文。
論文:Unifying Language Learning Paradigms
作者:Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
🔧 技術細節
訓練
該模型的檢查點在 C4 數據集上進行迭代預訓練,並在多種數據集上進行微調。
預訓練
模型在 C4 語料庫上進行預訓練。預訓練時,模型在 C4 上總共處理 1 萬億個標記(200 萬步),批量大小為 1024。輸入和目標的序列長度均設置為 512/512。預訓練期間,丟棄率設置為 0。對於約 1 萬億個標記的預訓練,大約花費了一個多月的時間。該模型有 32 個編碼器層和 32 個解碼器層,dmodel 為 4096,df 為 16384。每個頭的維度為 256,總共 16 個頭。我們的模型使用了 8 路模型並行。使用與 T5 相同的 SentencePiece 分詞器,詞彙量大小為 32000(點擊 此處 瞭解更多關於 T5 分詞器的信息)。
UL - 20B 可以被看作是一個與 T5 非常相似的模型,但使用了不同的訓練目標和略有不同的縮放旋鈕。UL - 20B 使用 Jax 和 T5X 基礎設施進行訓練。
預訓練期間的訓練目標是多種不同去噪策略的混合,具體如下:
混合去噪器
引用論文中的內容:
我們推測,一個強大的通用模型在預訓練期間必須接觸並解決各種不同的問題。鑑於預訓練是通過自監督學習完成的,我們認為應該將這種多樣性注入到模型的目標中,否則模型可能會缺乏某些能力,例如長連貫文本生成能力。 基於此,以及當前的目標函數類別,我們定義了預訓練期間使用的三種主要範式:
- R - 去噪器:常規去噪是 T5 中引入的標準跨度損壞方法,使用 2 到 5 個標記作為跨度長度,大約掩蓋輸入標記的 15%。這些跨度較短,可能有助於獲取知識,而不是學習生成流暢的文本。
- S - 去噪器:這是一種特殊的去噪情況,在構建輸入到目標的任務時,我們遵循嚴格的順序,即前綴語言建模。為此,我們只需將輸入序列劃分為兩個子標記序列,分別作為上下文和目標,使得目標不依賴於未來信息。這與標準的跨度損壞不同,在標準跨度損壞中,可能存在目標標記的位置早於上下文標記的情況。請注意,與前綴語言模型(Prefix - LM)設置類似,上下文(前綴)保留了雙向感受野。我們注意到,具有非常短記憶或無記憶的 S - 去噪與標準的因果語言建模在本質上是相似的。
- X - 去噪器:這是一種極端的去噪版本,模型必須根據輸入的一小部分到中等部分恢復輸入的大部分內容。這模擬了模型需要從信息相對有限的記憶中生成較長目標的情況。為此,我們選擇包含激進去噪的示例,其中大約 50% 的輸入序列被掩蓋。這可以通過增加跨度長度和/或損壞率來實現。如果預訓練任務具有較長的跨度(例如,≥ 12 個標記)或較大的損壞率(例如,≥ 30%),我們認為該任務是極端的。X - 去噪的動機是在常規跨度損壞和類似語言模型的目標之間進行插值。
請參考以下圖表以獲得更直觀的解釋:
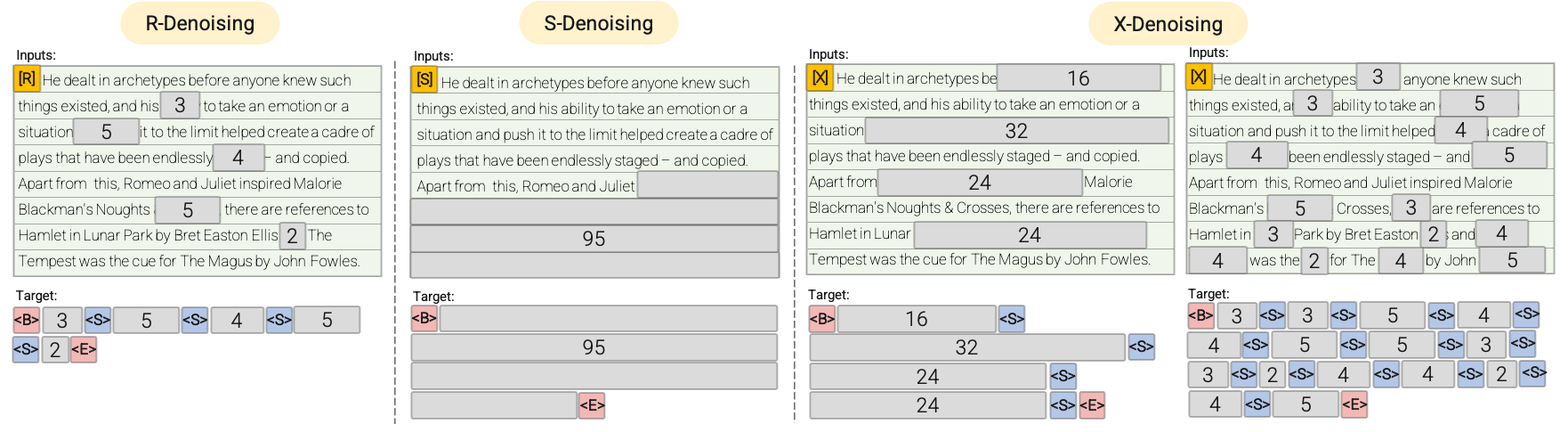
重要提示:更多詳細信息,請參閱論文 Unifying Language Learning Paradigms 的 3.1.2 節。
微調
模型在 N 次預訓練步驟後進行連續微調,其中 N 通常在 50k 到 100k 之間。換句話說,在每次 Nk 步的預訓練之後,模型會在每個下游任務上進行微調。請參閱論文 Unifying Language Learning Paradigms 的 5.2.2 節以瞭解用於微調的所有數據集的概述。
由於模型是連續微調的,一旦某個任務達到了最先進的性能,就會停止在該任務上的微調,以節省計算資源。模型總共訓練了 265 萬步。
重要提示:更多詳細信息,請參閱論文 Unifying Language Learning Paradigms 的 5.2.1 和 5.2.2 節。
💻 使用示例
基礎用法
以下展示瞭如何使用不同的去噪策略來預測掩碼段落。由於模型規模較大,以下示例需要在至少 40GB 的 A100 GPU 上運行。
S - 去噪
對於 S - 去噪,請確保按照以下方式在文本前添加前綴 [S2S]。
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[S2S] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man with a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere <extra_id_0>"
inputs = tokenizer(input_string, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> <pad>. Dudley was a very good boy, but he was also very stupid.</s>
R - 去噪
對於 R - 去噪,請確保按照以下方式在文本前添加前綴 [NLU]。
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLU] Mr. Dursley was the director of a firm called <extra_id_0>, which made <extra_id_1>. He was a big, solid man with a bald head. Mrs. Dursley was thin and <extra_id_2> of neck, which came in very useful as she spent so much of her time <extra_id_3>. The Dursleys had a small son called Dudley and <extra_id_4>"
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> brooms for witches and wizards<extra_id_2> had a lot<extra_id_3> scolding Dudley<extra_id_4> a daughter called Petunia. Dudley was a nasty, spoiled little boy who was always getting into trouble. He was very fond of his pet rat, Scabbers.<extra_id_5> Burrows<extra_id_3> screaming at him<extra_id_4> a daughter called Petunia</s>
"
X - 去噪
對於 X - 去噪,請確保按照以下方式在文本前添加前綴 [NLG]。
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLG] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man wiht a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she
spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere. <extra_id_0>"
model.cuda()
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> a lot of money from the manufacture of a product called '' Burrows'''s ''<extra_id_2> had a lot<extra_id_3> looking down people's throats<extra_id_4> a daughter called Petunia. Dudley was a very stupid boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat,"
📄 許可證
本模型採用 Apache - 2.0 許可證。
貢獻者
此模型由 Daniel Hesslow 貢獻。
信息表格
| 屬性 | 詳情 |
|---|---|
| 模型類型 | UL2 是一個用於預訓練模型的統一框架,採用混合去噪器(MoD)預訓練目標,結合多種預訓練範式,並引入模式切換概念。 |
| 訓練數據 | 模型在 C4 語料庫上進行預訓練,在多種數據集上進行微調。 |