%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Model Overview
Model Features
Model Capabilities
Use Cases
🚀 UL2: A Unified Pretraining Framework
UL2 is a unified framework for pretraining models that can achieve universal effectiveness across various datasets and setups. It uses Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms. UL2 also introduces the concept of mode switching, where downstream fine-tuning is associated with specific pre-training schemes.

📚 Documentation
Abstract
Existing pre-trained models are generally designed for a particular class of problems. To date, there is still no consensus on the right architecture and pre-training setup. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. First, we separate architectural archetypes from pre-training objectives, two concepts that are often confused. Then, we present a generalized and unified perspective for self-supervision in NLP, showing how different pre-training objectives can be transformed into each other and how interpolating between them can be effective. We propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms. We also introduce the concept of mode switching, where downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablation experiments to compare multiple pre-training objectives and find that our method outperforms T5 and/or GPT-like models across multiple diverse setups, pushing the Pareto-frontier. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks, including language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding, and information retrieval. Our model also achieves strong results in in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.
For more information, please refer to the original paper.
Paper: Unifying Language Learning Paradigms
Authors: Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
📦 Installation
This section does not contain installation steps, so it is skipped.
🔧 Technical Details
Training
The checkpoint was iteratively pre-trained on C4 and fine-tuned on a variety of datasets.
PreTraining
The model is pretrained on the C4 corpus. During pretraining, the model is trained on a total of 1 trillion tokens on C4 (2 million steps) with a batch size of 1024. The sequence length is set to 512/512 for inputs and targets. Dropout is set to 0 during pretraining. Pre-training took slightly more than one month for about 1 trillion tokens. The model has 32 encoder layers and 32 decoder layers, dmodel of 4096 and df of 16384. The dimension of each head is 256 for a total of 16 heads. Our model uses a model parallelism of 8. The same sentencepiece tokenizer as T5 with a vocab size of 32000 is used (click here for more information about the T5 tokenizer).
UL-20B can be regarded as a model quite similar to T5 but trained with a different objective and slightly different scaling knobs. UL-20B was trained using the Jax and T5X infrastructure.
The training objective during pretraining is a mixture of different denoising strategies, which are explained as follows:
Mixture of Denoisers
To quote the paper:
We conjecture that a strong universal model has to be exposed to solving diverse set of problems during pre-training. Given that pre-training is done using self-supervision, we argue that such diversity should be injected to the objective of the model, otherwise the model might suffer from lack a certain ability, like long-coherent text generation. Motivated by this, as well as current class of objective functions, we define three main paradigms that are used during pre-training:
-
R-Denoiser: The regular denoising is the standard span corruption introduced in T5, which uses a range of 2 to 5 tokens as the span length, masking about 15% of input tokens. These spans are short and potentially useful for acquiring knowledge rather than learning to generate fluent text.
-
S-Denoiser: A specific case of denoising where we observe a strict sequential order when framing the inputs-to-targets task, i.e., prefix language modeling. To do so, we simply partition the input sequence into two sub-sequences of tokens as context and target such that the targets do not rely on future information. This is different from standard span corruption, where there could be a target token with an earlier position than a context token. Note that similar to the Prefix-LM setup, the context (prefix) retains a bidirectional receptive field. We note that S-Denoising with very short memory or no memory is in a similar spirit to standard causal language modeling.
-
X-Denoiser: An extreme version of denoising where the model must recover a large part of the input given a small to moderate part of it. This simulates a situation where a model needs to generate a long target from a memory with relatively limited information. To achieve this, we include examples with aggressive denoising, where approximately 50% of the input sequence is masked by increasing the span length and/or corruption rate. We consider a pre-training task to be extreme if it has a long span (e.g., ≥ 12 tokens) or a large corruption rate (e.g., ≥ 30%). X-denoising is motivated by being an interpolation between regular span corruption and language model-like objectives.
See the following diagram for a more visual explanation:
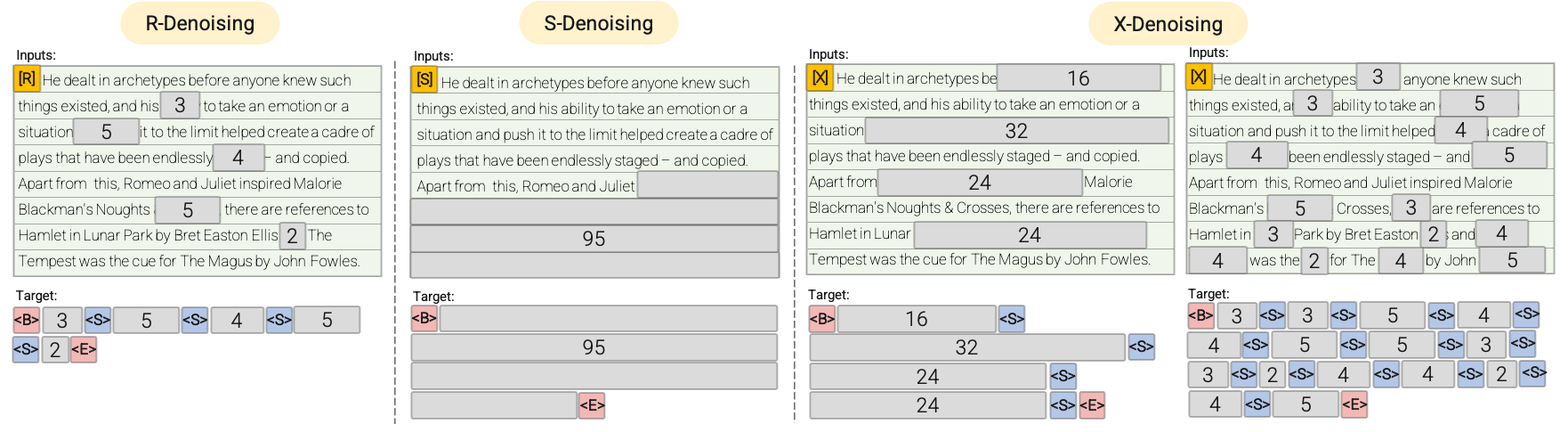
Important: For more details, please see sections 3.1.2 of the paper.
Fine-tuning
The model was continuously fine-tuned after N pretraining steps, where N is typically from 50k to 100k. In other words, after each Nk steps of pretraining, the model is finetuned on each downstream task. See section 5.2.2 of paper for an overview of all datasets used for fine-tuning.
As the model is continuously finetuned, finetuning is stopped on a task once it has reached state-of-the-art to save compute. In total, the model was trained for 2.65 million steps.
Important: For more details, please see sections 5.2.1 and 5.2.2 of the paper.
✨ Features
This model was contributed by Daniel Hesslow.
💻 Usage Examples
Basic Usage
The following shows how to predict masked passages using different denoising strategies. Given the size of the model, the following examples need to be run on at least a 40GB A100 GPU.
S-Denoising
For S-Denoising, please make sure to prompt the text with the prefix [S2S] as shown below.
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[S2S] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man with a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere <extra_id_0>"
inputs = tokenizer(input_string, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> <pad>. Dudley was a very good boy, but he was also very stupid.</s>
R-Denoising
For R-Denoising, please make sure to prompt the text with the prefix [NLU] as shown below.
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLU] Mr. Dursley was the director of a firm called <extra_id_0>, which made <extra_id_1>. He was a big, solid man with a bald head. Mrs. Dursley was thin and <extra_id_2> of neck, which came in very useful as she spent so much of her time <extra_id_3>. The Dursleys had a small son called Dudley and <extra_id_4>"
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> brooms for witches and wizards<extra_id_2> had a lot<extra_id_3> scolding Dudley<extra_id_4> a daughter called Petunia. Dudley was a nasty, spoiled little boy who was always getting into trouble. He was very fond of his pet rat, Scabbers.<extra_id_5> Burrows<extra_id_3> screaming at him<extra_id_4> a daughter called Petunia</s>
"
X-Denoising
For X-Denoising, please make sure to prompt the text with the prefix [NLG] as shown below.
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLG] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man wiht a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she
spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere. <extra_id_0>"
model.cuda()
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> a lot of money from the manufacture of a product called '' Burrows'''s ''<extra_id_2> had a lot<extra_id_3> looking down people's throats<extra_id_4> a daughter called Petunia. Dudley was a very stupid boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat,"
📄 License
- Language: en
- Datasets: c4
- License: apache-2.0