%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 UL2
UL2は、データセットや設定に関わらず普遍的に有効な事前学習モデルの統一フレームワークです。UL2は、多様な事前学習パラダイムを組み合わせた事前学習目的であるMixture-of-Denoisers (MoD) を使用しています。また、UL2はモード切り替えの概念を導入しており、下流の微調整は特定の事前学習スキームに関連付けられています。

🚀 クイックスタート
UL2は、データセットや設定に関係なく普遍的に有効な事前学習モデルのための統一フレームワークです。このモデルは、多様な事前学習パラダイムを組み合わせたMixture-of-Denoisers (MoD) を使用しています。
✨ 主な機能
- UL2は、データセットや設定に関係なく普遍的に有効な事前学習モデルのための統一フレームワークです。
- Mixture-of-Denoisers (MoD) という事前学習目的を使用し、多様な事前学習パラダイムを組み合わせています。
- モード切り替えの概念を導入し、下流の微調整を特定の事前学習スキームに関連付けています。
📦 インストール
原READMEにインストール手順に関する具体的な内容がないため、このセクションは省略されます。
💻 使用例
基本的な使用法
以下は、異なるデノイジング戦略を使用してマスクされた文章を予測する方法を示しています。モデルのサイズを考慮すると、以下の例は少なくとも40GBのA100 GPUで実行する必要があります。
S-Denoising
S-Denoising の場合、以下のようにテキストに接頭辞 [S2S] を付ける必要があります。
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[S2S] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man with a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere <extra_id_0>"
inputs = tokenizer(input_string, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> <pad>. Dudley was a very good boy, but he was also very stupid.</s>
R-Denoising
R-Denoising の場合、以下のようにテキストに接頭辞 [NLU] を付ける必要があります。
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLU] Mr. Dursley was the director of a firm called <extra_id_0>, which made <extra_id_1>. He was a big, solid man with a bald head. Mrs. Dursley was thin and <extra_id_2> of neck, which came in very useful as she spent so much of her time <extra_id_3>. The Dursleys had a small son called Dudley and <extra_id_4>"
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> brooms for witches and wizards<extra_id_2> had a lot<extra_id_3> scolding Dudley<extra_id_4> a daughter called Petunia. Dudley was a nasty, spoiled little boy who was always getting into trouble. He was very fond of his pet rat, Scabbers.<extra_id_5> Burrows<extra_id_3> screaming at him<extra_id_4> a daughter called Petunia</s>
"
X-Denoising
X-Denoising の場合、以下のようにテキストに接頭辞 [NLG] を付ける必要があります。
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLG] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man wiht a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she
spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere. <extra_id_0>"
model.cuda()
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> a lot of money from the manufacture of a product called '' Burrows'''s ''<extra_id_2> had a lot<extra_id_3> looking down people's throats<extra_id_4> a daughter called Petunia. Dudley was a very stupid boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat,"
📚 ドキュメント
概要
既存の事前学習モデルは一般的に特定のクラスの問題に向けられています。これまで、適切なアーキテクチャと事前学習の設定についてまだコンセンサスが得られていないようです。この論文では、データセットや設定に関係なく普遍的に有効な事前学習モデルのための統一フレームワークを提案しています。まず、一般的に混同される2つの概念であるアーキテクチャの原型と事前学習の目的を切り離します。次に、自然言語処理における自己教師あり学習の一般化された統一的な視点を提示し、異なる事前学習目的がどのように相互に変換できるか、および異なる目的間の補間がどのように有効であるかを示します。そして、多様な事前学習パラダイムを組み合わせた事前学習目的であるMixture-of-Denoisers (MoD) を提案します。さらに、モード切り替えの概念を導入し、下流の微調整を特定の事前学習スキームに関連付けます。多数のアブレーション実験を行い、複数の事前学習目的を比較した結果、我々の方法は複数の多様な設定でT5やGPTのようなモデルを上回り、パレートフロンティアを押し上げることがわかりました。最後に、モデルを200億パラメータまでスケーリングすることで、言語生成(自動評価と人間評価)、言語理解、テキスト分類、質問応答、常識推論、長文推論、構造化知識の基礎付け、情報検索など、50の確立された教師あり自然言語処理タスクで最先端の性能を達成しました。また、コンテキスト内学習でも強い結果を得ており、ゼロショットSuperGLUEでは1750億パラメータのGPT-3を上回り、ワンショット要約ではT5-XXLの性能を3倍にしています。
詳細については、元の論文を参照してください。
論文: Unifying Language Learning Paradigms
著者: Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
学習
チェックポイントは、C4で反復的に事前学習され、さまざまなデータセットで微調整されました。
事前学習
モデルはC4コーパスで事前学習されています。事前学習には、C4上の合計1兆トークン(200万ステップ)でバッチサイズ1024で学習されました。シーケンス長は入力とターゲットに対して512/512に設定されています。事前学習中のドロップアウトは0に設定されています。事前学習には約1兆トークンに対して1か月強かかりました。モデルは32層のエンコーダと32層のデコーダを持ち、dmodel は4096、df は16384です。各ヘッドの次元は256で、合計16ヘッドです。我々のモデルはモデル並列度8を使用しています。語彙サイズ32000のT5と同じsentencepieceトークナイザが使用されています(T5トークナイザの詳細についてはこちらをクリック)。
UL-20Bは、T5に非常に似ているが、異なる目的とわずかに異なるスケーリングノブで学習されたモデルと解釈できます。UL-20Bは、Jax と T5X インフラストラクチャを使用して学習されました。
事前学習中の学習目的は、以下で説明されるさまざまなデノイジング戦略の混合です。
Mixture of Denoisers
論文から引用すると、
我々は、強力な普遍的モデルは事前学習中に多様な問題のセットを解くことにさらされなければならないと推測しています。事前学習は自己教師あり学習を使用して行われるため、我々はこのような多様性はモデルの目的に注入されるべきであり、そうでなければモデルは長い一貫性のあるテキスト生成のような特定の能力の欠如に苦しむ可能性があると主張します。 これと現在のクラスの目的関数に触発されて、我々は事前学習中に使用される3つの主要なパラダイムを定義します。
- R-Denoiser: 通常のデノイジングは、T5 で導入された標準的なスパン破損で、2から5トークンの範囲をスパン長として使用し、入力トークンの約15%をマスクします。これらのスパンは短く、知識を獲得するのに潜在的に有用であり、流暢なテキストを生成することを学ぶよりも有用です。
- S-Denoiser: 入力からターゲットへのタスクを構築する際に厳密な順序を観察する特定のデノイジングのケース、つまりプレフィックス言語モデリングです。これを行うために、単に入力シーケンスをコンテキストとターゲットの2つのサブシーケンスに分割し、ターゲットが将来の情報に依存しないようにします。これは、コンテキストトークンよりも早い位置にターゲットトークンがある可能性のある標準的なスパン破損とは異なります。なお、Prefix-LM設定と同様に、コンテキスト(プレフィックス)は双方向の受容野を保持します。非常に短いメモリまたはメモリのないS-Denoisingは、標準的な因果言語モデリングと同じ精神です。
- X-Denoiser: モデルが入力の小から中程度の部分を与えられたときに、入力の大部分を回復しなければならない極端なデノイジングのバージョンです。これは、比較的限られた情報のメモリから長いターゲットを生成する必要がある状況をシミュレートします。これを行うために、入力シーケンスの約50%がマスクされる積極的なデノイジングの例を含めることにします。これは、スパン長を増やすか、破損率を上げることによって行われます。我々は、長いスパン(例えば、≥ 12トークン)または大きい破損率(例えば、≥ 30%)を持つ事前学習タスクを極端なものと見なします。X-デノイジングは、通常のスパン破損と言語モデルのような目的の間の補間として動機付けられています。
より視覚的な説明については、以下の図を参照してください。
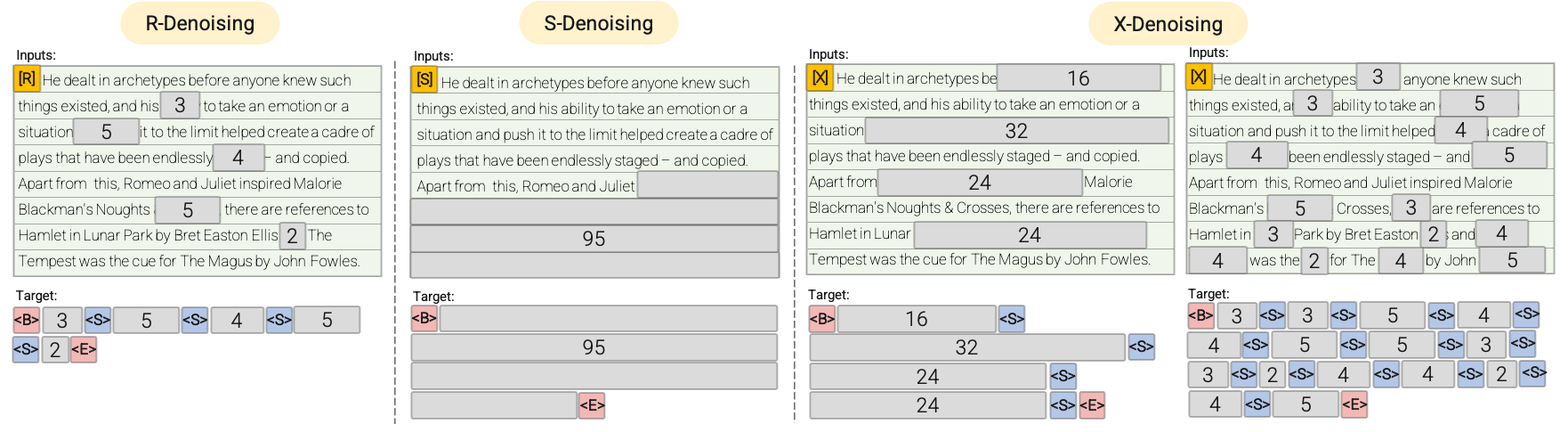
重要: 詳細については、論文 のセクション3.1.2を参照してください。
微調整
モデルは、通常50kから100kの事前学習ステップの後に継続的に微調整されました。つまり、事前学習の各Nkステップの後に、モデルは各下流タスクで微調整されます(微調整に使用されたすべてのデータセットの概要については、論文 のセクション5.2.2を参照)。
モデルは継続的に微調整されるため、タスクが最先端の状態に達したら、計算資源を節約するために微調整を停止します。合計で、モデルは265万ステップで学習されました。
重要: 詳細については、論文 のセクション5.2.1と5.2.2を参照してください。
貢献者
このモデルは Daniel Hesslow によって貢献されました。
🔧 技術詳細
原READMEに技術的な詳細説明が十分に記載されているため、このセクションではそれらの内容をまとめています。
- UL2は、多様な事前学習パラダイムを組み合わせたMixture-of-Denoisers (MoD) を使用しています。
- モード切り替えの概念を導入し、下流の微調整を特定の事前学習スキームに関連付けています。
- 事前学習はC4コーパスで行われ、微調整はさまざまなデータセットで行われました。
- モデルは32層のエンコーダと32層のデコーダを持ち、
dmodelは4096、dfは16384です。 - 各ヘッドの次元は256で、合計16ヘッドです。
- モデルはモデル並列度8を使用しています。
📄 ライセンス
このモデルはApache-2.0ライセンスの下で提供されています。