%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 子牙-LLaMA-13B-v1
子牙-LLaMA-13B-v1是基於LLaMA的130億參數大規模預訓練模型,具備翻譯、編程、文本分類等多種能力。它經過大規模預訓練、多任務有監督微調和人類反饋學習三個階段的訓練,能更好地理解人類意圖,減少“幻覺”和不安全輸出。
🚀 快速開始
由於LLaMA權重的許可限制,該模型不能用於商業用途,請嚴格遵守LLaMA的使用政策。考慮到LLaMA權重的許可證限制,我們無法直接發佈完整的模型權重。因此,我們使用了FastChat開源工具作為基礎,並對其進行了進一步的優化。我們計算併發布了Ziya-LLaMA-13B-v1權重與原始LLaMA權重之間的差值。用戶可以按照以下步驟操作以獲得Ziya-LLaMA-13B-v1完整權重,具體步驟如下:
Step 1:獲取LLaMA權重並轉成Hugging Face Transformers模型格式,可參考轉換腳本(若已經有huggingface權重則跳過)
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 13B --output_dir /output/path
Step 2:下載Ziya-LLaMA-13B-v1的delta權重以及step 1中轉換好的原始LLaMA權重,使用如下腳本轉換:https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/utils/apply_delta.py
python3 -m apply_delta --base ~/model_weights/llama-13b --target ~/model_weights/Ziya-LLaMA-13B --delta ~/model_weights/Ziya-LLaMA-13B-v1
Step 3: 加載step 2得到的模型推理
from transformers import AutoTokenizer
from transformers import LlamaForCausalLM
import torch
device = torch.device("cuda")
ckpt = '基於delta參數合併後的完整模型權重'
query="幫我寫一份去西安的旅遊計劃"
model = LlamaForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(ckpt, use_fast=False)
inputs = '<human>:' + query.strip() + '\n<bot>:'
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=1024,
do_sample = True,
top_p = 0.85,
temperature = 1.0,
repetition_penalty=1.,
eos_token_id=2,
bos_token_id=1,
pad_token_id=0)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
✨ 主要特性
- 多語言支持:支持英文和中文,原始數據包含英文和中文,其中英文數據來自openwebtext、Books、Wikipedia和Code,中文數據來自清洗後的悟道數據集、自建的中文數據集。
- 多任務能力:具備翻譯、編程、文本分類、信息抽取、摘要、文案生成、常識問答和數學計算等能力。
- 多階段訓練:經過大規模預訓練、多任務有監督微調和人類反饋學習三階段的訓練過程,能更好地理解人類意圖,減少“幻覺”和不安全輸出。
📦 安裝指南
pip install torch==1.12.1 tokenizers==0.13.3 git+https://github.com/huggingface/transformers
💻 使用示例
基礎用法
from transformers import AutoTokenizer
from transformers import LlamaForCausalLM
import torch
device = torch.device("cuda")
ckpt = '基於delta參數合併後的完整模型權重'
query="幫我寫一份去西安的旅遊計劃"
model = LlamaForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(ckpt, use_fast=False)
inputs = '<human>:' + query.strip() + '\n<bot>:'
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=1024,
do_sample = True,
top_p = 0.85,
temperature = 1.0,
repetition_penalty=1.,
eos_token_id=2,
bos_token_id=1,
pad_token_id=0)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
📚 詳細文檔
模型分類
| 屬性 | 詳情 |
|---|---|
| 需求 | 通用 |
| 任務 | AGI模型 |
| 系列 | 姜子牙 |
| 模型 | LLaMA |
| 參數 | 13B |
| 額外 | 英文和中文 |
模型信息
繼續預訓練
原始數據包含英文和中文,其中英文數據來自openwebtext、Books、Wikipedia和Code,中文數據來自清洗後的悟道數據集、自建的中文數據集。在對原始數據進行去重、模型打分、數據分桶、規則過濾、敏感主題過濾和數據評估後,最終得到125B tokens的有效數據。
為了解決LLaMA原生分詞對中文編解碼效率低下的問題,我們在LLaMA詞表的基礎上增加了7k+個常見中文字,通過和LLaMA原生的詞表去重,最終得到一個39410大小的詞表,並通過複用Transformers裡LlamaTokenizer來實現了這一效果。
在增量訓練過程中,我們使用了160張40GB的A100,採用2.6M tokens的訓練集樣本數量和FP 16的混合精度,吞吐量達到118 TFLOP per GPU per second。因此我們能夠在8天的時間裡在原生的LLaMA-13B模型基礎上,增量訓練110B tokens的數據。
訓練期間,雖然遇到了機器宕機、底層框架bug、loss spike等各種問題,但我們通過快速調整,保證了增量訓練的穩定性。我們也放出訓練過程的loss曲線,讓大家瞭解可能出現的問題。

多任務有監督微調
在多任務有監督微調階段,採用了課程學習(curiculum learning)和增量訓練(continual learning)的策略,用大模型輔助劃分已有的數據難度,然後通過“Easy To Hard”的方式,分多個階段進行SFT訓練。
SFT訓練數據包含多個高質量的數據集,均經過人工篩選和校驗:
- Self-Instruct構造的數據(約2M):BELLE、Alpaca、Alpaca-GPT4等多個數據集
- 內部收集Code數據(300K):包含leetcode、多種Code任務形式
- 內部收集推理/邏輯相關數據(500K):推理、申論、數學應用題、數值計算等
- 中英平行語料(2M):中英互譯語料、COT類型翻譯語料、古文翻譯語料等
- 多輪對話語料(500K):Self-Instruct生成、任務型多輪對話、Role-Playing型多輪對話等
人類反饋學習
為了進一步提升模型的綜合表現,使其能夠充分理解人類意圖、減少“幻覺”和不安全的輸出,基於指令微調後的模型,進行了人類反饋訓練(Human-Feedback Training,HFT)。在訓練中,我們採用了以人類反饋強化學習(RM、PPO)為主,結合多種其他手段聯合訓練的方法,手段包括人類反饋微調(Human-Feedback Fine-tuning,HFFT)、後見鏈微調(Chain-of-Hindsight Fine-tuning,COHFT)、AI反饋(AI Feedback)和基於規則的獎勵系統(Rule-based Reward System,RBRS)等,用來彌補PPO方法的短板,加速訓練。
我們在內部自研的框架上實現了HFT的訓練流程,該框架可以利用最少8張40G的A100顯卡完成Ziya-LLaMA-13B-v1的全參數訓練。在PPO訓練中,我們沒有限制生成樣本的長度,以確保長文本任務的獎勵準確性。每次訓練的總經驗池尺寸超過100k樣本,確保了訓練的充分性。
效果評估
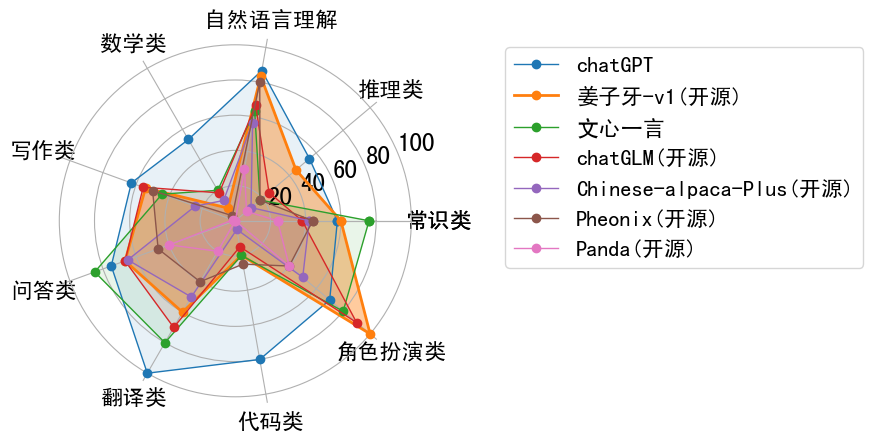
微調示例
推理量化示例
引用
如果您在您的工作中使用了我們的模型,可以引用我們的論文:
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
歡迎引用我們的網站:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
姜子牙系列模型
- Ziya-LLaMA-13B-v1.1
- Ziya-LLaMA-13B-v1
- Ziya-LLaMA-7B-Reward
- Ziya-LLaMA-13B-Pretrain-v1
- Ziya-BLIP2-14B-Visual-v1
相關鏈接
- 主頁:Fengshenbang
- Github:Fengshenbang-LM
許可證
本項目採用GPL-3.0許可證。
⚠️ 重要提示
由於LLaMA權重的許可限制,該模型不能用於商業用途,請嚴格遵守LLaMA的使用政策。