%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 子牙-LLaMA-13B-v1
子牙-LLaMA-13B-v1は、LLaMAに基づく130億パラメータの大規模事前学習モデルで、翻訳、プログラミング、テキスト分類、情報抽出、要約、コピーライティング、一般知識の質問応答、数学計算などのタスクを実行する能力を備えています。
🚀 クイックスタート
(LLaMAのウェイトに関するライセンス制限のため、完全なモデルウェイトを直接公開することはできません。ユーザーは使用方法を参照してマージする必要があります。)
✨ 主な機能
姜子牙シリーズモデル
- Ziya-LLaMA-13B-v1.1
- Ziya-LLaMA-13B-v1
- Ziya-LLaMA-7B-Reward
- Ziya-LLaMA-13B-Pretrain-v1
- Ziya-BLIP2-14B-Visual-v1
概要
姜子牙汎用大規模モデルV1は、LLaMaに基づく130億パラメータの大規模事前学習モデルで、翻訳、プログラミング、テキスト分類、情報抽出、要約、コピーライティング、一般知識の質問応答、数学計算などの能力を備えています。現在、姜子牙汎用大規模モデルは、大規模事前学習、多タスク教師あり微調整、人間フィードバック学習の3段階の学習プロセスを完了しています。
The Ziya-LLaMA-13B-v1 is a large-scale pre-trained model based on LLaMA with 13 billion parameters. It has the ability to perform tasks such as translation, programming, text classification, information extraction, summarization, copywriting, common sense Q&A, and mathematical calculation. The Ziya-LLaMA-13B-v1 has undergone three stages of training: large-scale continual pre-training (PT), multi-task supervised fine-tuning (SFT), and human feedback learning (RM, PPO).
📦 インストール
ソフトウェア依存関係
pip install torch==1.12.1 tokenizers==0.13.3 git+https://github.com/huggingface/transformers
📚 ドキュメント
モデル分類
| 要件 | タスク | シリーズ | モデル | パラメータ | 追加情報 |
|---|---|---|---|---|---|
| 汎用 | AGIモデル | 姜子牙 | LLaMA | 13B | 英語と中国語 |
モデル情報
継続的事前学習
元のデータには英語と中国語の両方が含まれており、英語のデータはopenwebtext、Books、Wikipedia、Codeから取得され、中国語のデータは洗浄された悟道データセットと自社で構築した中国語データセットから取得されます。重複排除、モデルスコアリング、データバケット化、ルールフィルタリング、敏感トピックフィルタリング、データ評価を行った後、最終的に1250億トークンの有効データが得られました。
LLaMAのネイティブトークナイザーが中国語のエンコードとデコードの効率が低い問題を解決するために、LLaMAの語彙に7000以上の一般的な中国語文字を追加し、LLaMAのネイティブ語彙との重複を排除して、最終的に39410の語彙を得ました。これは、TransformersのLlamaTokenizerを再利用することで実現されました。
増分学習の過程では、160枚の40GBのA100を使用し、260万トークンの学習データセットとFP16の混合精度を採用し、GPUあたりのスループットは118 TFLOP per secondに達しました。そのため、8日間でネイティブのLLaMA-13Bモデルに基づいて1100億トークンのデータを増分学習することができました。
学習中は、マシンのクラッシュ、基盤フレームワークのバグ、損失の急激な変動など、さまざまな問題に直面しましたが、迅速な調整により増分学習の安定性を保証しました。また、学習過程の損失曲線も公開して、発生する可能性のある問題を理解してもらえるようにしています。
The original data contains both English and Chinese, with English data from openwebtext, Books, Wikipedia, and Code, and Chinese data from the cleaned Wudao dataset and self-built Chinese dataset. After deduplication, model scoring, data bucketing, rule filtering, sensitive topic filtering, and data evaluation, we finally obtained 125 billion tokens of valid data.
To address the issue of low efficiency in Chinese encoding and decoding caused by the native word segmentation of LLaMa, we added 8,000 commonly used Chinese characters to the LLaMa vocabulary. By removing duplicates with the original LLaMa vocabulary, we finally obtained a vocabulary of size 39,410. We achieved this by reusing the LlamaTokenizer in Transformers.
During the incremental training process, we used 160 A100s with a total of 40GB memory, using a training dataset with 2.6 million tokens and mixed precision of FP16. The throughput reached 118 TFLOP per GPU per second. As a result, we were able to incrementally train 110 billion tokens of data on top of the native LLaMa-13B model in just 8 days.
Throughout the training process, we encountered various issues such as machine crashes, underlying framework bugs, and loss spikes. However, we ensured the stability of the incremental training by making rapid adjustments. We have also released the loss curve during the training process to help everyone understand the potential issues that may arise.

多タスク教師あり微調整
多タスク教師あり微調整段階では、カリキュラム学習(curiculum learning)と増分学習(continual learning)の戦略を採用し、大規模モデルを利用して既存のデータの難易度を分割し、「Easy To Hard」の方式で複数の段階に分けてSFT学習を行いました。
SFT学習データには、複数の高品質なデータセットが含まれており、すべて人手による選別と検証を経ています。
- Self-Instructで構築されたデータ(約200万件):BELLE、Alpaca、Alpaca-GPT4などの複数のデータセット
- 内部収集コードデータ(30万件):leetcode、さまざまなコードタスク形式を含む
- 内部収集推論/論理関連データ(50万件):推論、論文、数学の応用問題、数値計算など
- 中英平行コーパス(200万件):中英相互翻訳コーパス、COTタイプの翻訳コーパス、古文翻訳コーパスなど
- 多輪対話コーパス(50万件):Self-Instruct生成、タスク型多輪対話、ロールプレイング型多輪対話など
During the supervised fine-tuning (SFT) phase of multitask learning, we used a strategy of curriculum learning and incremental training. We used the large model to assist in partitioning the existing data by difficulty and then conducted SFT training in multiple stages using the "easy to hard" approach.
The SFT training data consists of multiple high-quality datasets that have been manually selected and verified, including approximately 2 million samples from datasets such as BELLE, Alpaca, and Alpaca-GPT4, 300,000 samples of internally collected code data including LeetCode and various code tasks, 500,000 samples of internally collected inference/logic-related data such as reasoning, argumentative essays, mathematical application questions, and numerical calculations, 2 million samples of Chinese-English parallel corpora including translation, COT-type translation, and classical Chinese translation, and 500,000 samples of multi-turn dialogue corpora including self-instructed generation, task-oriented multi-turn dialogue, and role-playing multi-turn dialogue.
人間フィードバック学習
モデルの総合的な性能をさらに向上させ、人間の意図を十分に理解し、「幻覚」や不安全な出力を減らすために、命令に基づく微調整後のモデルを基に、人間フィードバック学習(Human-Feedback Training、HFT)を行いました。学習では、人間フィードバック強化学習(RM、PPO)を中心に、人間フィードバック微調整(Human-Feedback Fine-tuning、HFFT)、事後見通しチェーン微調整(Chain-of-Hindsight Fine-tuning、COHFT)、AIフィードバック、ルールベースの報酬システム(Rule-based Reward System、RBRS)などのさまざまな手段を組み合わせた学習方法を採用し、PPO方法の短所を補い、学習を加速させました。
HFT学習プロセスは、自社で開発したフレームワーク上で実装されており、最低8枚の40GBのA100 GPUを使用してZiya-LLaMA-13B-v1の全パラメータ学習を完了することができます。PPO学習では、生成サンプルの長さを制限せず、長文タスクの報酬の正確性を保証しました。各学習の総経験プールサイズは10万サンプルを超えており、学習の十分性を保証しています。
To further improve the overall performance of the model, enabling it to fully understand human intentions, reduce "hallucinations" and unsafe outputs, we conducted Human-Feedback Training (HFT) based on the model fine-tuned with instructions. In the training process, we used a variety of methods, including human feedback reinforcement learning (RM, PPO), combined with other methods such as Human-Feedback Fine-tuning (HFFT), Chain-of-Hindsight Fine-tuning (COHFT), AI feedback, and Rule-based Reward System (RBRS), to supplement the shortcomings of the PPO method and accelerate training.
We implemented the HFT training process on an internally developed framework, which can use a minimum of 8 40GB A100 GPUs to complete the full parameter training of Ziya-LLaMA-13B-v1. In the PPO training, we did not limit the length of the generated samples to ensure the accuracy of rewards for long-text tasks. The total experience pool size for each training exceeded 100k samples, ensuring the sufficiency of the training.
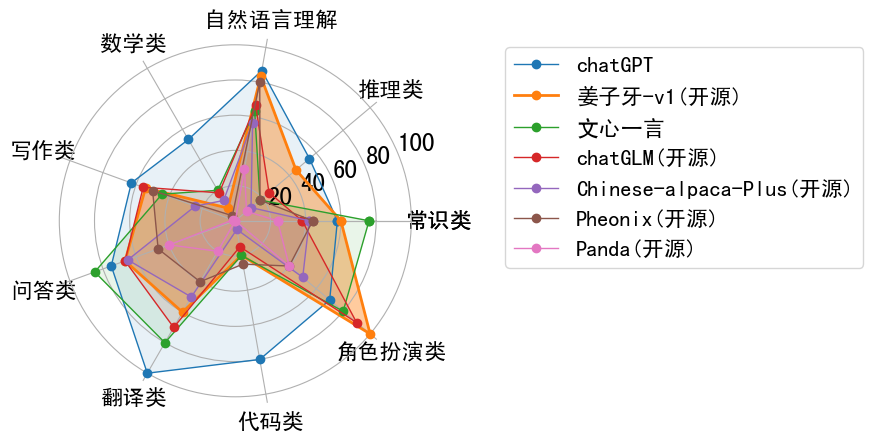
性能評価
💻 使用例
基本的な使用法
LLaMAのウェイトに関するライセンス制限のため、このモデルは商用目的に使用することはできません。LLaMAの使用ポリシーを厳格に遵守してください。LLaMAのウェイトに関するライセンス制限を考慮して、完全なモデルウェイトを直接公開することはできません。そのため、FastChatオープンソースツールをベースにさらに最適化しました。Ziya-LLaMA-13B-v1のウェイトと元のLLaMAのウェイトの差を計算して公開しています。ユーザーは以下の手順に従って、Ziya-LLaMA-13B-v1の完全なウェイトを取得することができます。
Step 1: LLaMAのウェイトを取得し、Hugging Face Transformersモデル形式に変換します。変換スクリプトを参照できます(すでにhuggingfaceのウェイトがある場合はこの手順をスキップしてください)
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 13B --output_dir /output/path
Step 2: Ziya-LLaMA-13B-v1のdeltaウェイトとStep 1で変換した元のLLaMAのウェイトをダウンロードし、以下のスクリプトを使用して変換します。https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/utils/apply_delta.py
python3 -m apply_delta --base ~/model_weights/llama-13b --target ~/model_weights/Ziya-LLaMA-13B --delta ~/model_weights/Ziya-LLaMA-13B-v1
Step 3: Step 2で得られたモデルをロードして推論を行います。
from transformers import AutoTokenizer
from transformers import LlamaForCausalLM
import torch
device = torch.device("cuda")
ckpt = '基于delta参数合并后的完整模型权重'
query="帮我写一份去西安的旅游计划"
model = LlamaForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(ckpt, use_fast=False)
inputs = '<human>:' + query.strip() + '\n<bot>:'
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=1024,
do_sample = True,
top_p = 0.85,
temperature = 1.0,
repetition_penalty=1.,
eos_token_id=2,
bos_token_id=1,
pad_token_id=0)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
NOTE: Due to the licensing restrictions of LLaMA weights, the utilization of the model for commercial purposes is precluded. Please strictly respect LLaMA's usage policy. Considering the licensing limitations on LLaMA weights, we are unable to directly release the complete model weights. Therefore, we utilized the open-source FastChat tool and further optimized it to calculate the differences between Ziya-LLaMA-13B-v1 weights and the original LLaMA weights. Users can follow the steps to obtain the complete weights of Ziya-LLaMA-13B-v1. The steps are as follows:
Step 1: Obtain the LLaMA weights and convert them into the Hugging Face Transformers format. You can refer to the script (skip this step if you already have the Hugging Face weights).
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 13B --output_dir /output/path
Step 2: Download the delta weights for Ziya-LLaMA-13B-v1 and the pre-converted original LLaMA weights from step 1. Use the following script for conversion: https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/utils/apply_delta.py
python3 -m apply_delta --base ~/model_weights/llama-13b --target ~/model_weights/Ziya-LLaMA-13B --delta ~/model_weights/Ziya-LLaMA-13B-v1(huggingface下载)
Step 3: Load the model obtained in Step 2 for inference.
from transformers import AutoTokenizer
from transformers import LlamaForCausalLM
import torch
device = torch.device("cuda")
ckpt = '基于delta合并后完整模型权重'
query="帮我写一份去西安的旅游计划"
model = LlamaForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(ckpt, use_fast=False)
inputs = '<human>:' + query.strip() + '\n<bot>:'
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=1024,
do_sample = True,
top_p = 0.85,
temperature = 1.0,
repetition_penalty=1.,
eos_token_id=2,
bos_token_id=1,
pad_token_id=0)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
高度な使用法
微調整例
ziya_finetuneを参照してください。
推論と量子化例
ziya_inferenceを参照してください。
📄 ライセンス
このモデルはGPL-3.0ライセンスの下で提供されています。
🔧 技術詳細
引用
あなたの研究や開発でこのモデルを使用する場合は、以下の論文を引用してください。
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
また、ウェブサイトも引用することができます。
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}