🚀 Ziya-LLaMA-13B-v1
Ziya-LLaMA-13B-v1 is a large-scale pre-trained model based on LLaMA with 13 billion parameters, capable of handling various tasks such as translation, programming, and more.
🚀 Quick Start
Due to the licensing restrictions of LLaMA weights, we cannot directly release the complete model weights. Users need to refer to the Usage section for weight merging.
✨ Features
General Capabilities
The Ziya-LLaMA-13B-v1 has the ability to perform tasks such as translation, programming, text classification, information extraction, summarization, copywriting, common sense Q&A, and mathematical calculation. It has undergone three stages of training: large-scale continual pre-training (PT), multi-task supervised fine-tuning (SFT), and human feedback learning (RM, PPO).
Other Models in the Ziya Series
📦 Installation
Software Dependencies
pip install torch==1.12.1 tokenizers==0.13.3 git+https://github.com/huggingface/transformers
📚 Documentation
Model Taxonomy
| Property |
Details |
| Demand |
General |
| Task |
AGI model |
| Series |
Ziya |
| Model |
LLaMA |
| Parameter |
13B |
| Extra |
English&Chinese |
Model Information
Continual Pretraining
The original data contains both English and Chinese, with English data from openwebtext, Books, Wikipedia, and Code, and Chinese data from the cleaned Wudao dataset and self-built Chinese dataset. After deduplication, model scoring, data bucketing, rule filtering, sensitive topic filtering, and data evaluation, we finally obtained 125 billion tokens of valid data.
To address the issue of low efficiency in Chinese encoding and decoding caused by the native word segmentation of LLaMa, we added 8,000 commonly used Chinese characters to the LLaMa vocabulary. By removing duplicates with the original LLaMa vocabulary, we finally obtained a vocabulary of size 39,410. We achieved this by reusing the LlamaTokenizer in Transformers.
During the incremental training process, we used 160 A100s with a total of 40GB memory, using a training dataset with 2.6 million tokens and mixed precision of FP16. The throughput reached 118 TFLOP per GPU per second. As a result, we were able to incrementally train 110 billion tokens of data on top of the native LLaMa-13B model in just 8 days.
Throughout the training process, we encountered various issues such as machine crashes, underlying framework bugs, and loss spikes. However, we ensured the stability of the incremental training by making rapid adjustments. We have also released the loss curve during the training process to help everyone understand the potential issues that may arise.

Supervised Finetuning
During the supervised fine-tuning (SFT) phase of multitask learning, we used a strategy of curriculum learning and incremental training. We used the large model to assist in partitioning the existing data by difficulty and then conducted SFT training in multiple stages using the "easy to hard" approach.
The SFT training data consists of multiple high-quality datasets that have been manually selected and verified, including approximately 2 million samples from datasets such as BELLE, Alpaca, and Alpaca-GPT4, 300,000 samples of internally collected code data including LeetCode and various code tasks, 500,000 samples of internally collected inference/logic-related data such as reasoning, argumentative essays, mathematical application questions, and numerical calculations, 2 million samples of Chinese-English parallel corpora including translation, COT-type translation, and classical Chinese translation, and 500,000 samples of multi-turn dialogue corpora including self-instructed generation, task-oriented multi-turn dialogue, and role-playing multi-turn dialogue.
Human-Feedback Training
To further improve the overall performance of the model, enabling it to fully understand human intentions, reduce "hallucinations" and unsafe outputs, we conducted Human-Feedback Training (HFT) based on the model fine-tuned with instructions. In the training process, we used a variety of methods, including human feedback reinforcement learning (RM, PPO), combined with other methods such as Human-Feedback Fine-tuning (HFFT), Chain-of-Hindsight Fine-tuning (COHFT), AI feedback, and Rule-based Reward System (RBRS), to supplement the shortcomings of the PPO method and accelerate training.
We implemented the HFT training process on an internally developed framework, which can use a minimum of 8 40GB A100 GPUs to complete the full parameter training of Ziya-LLaMA-13B-v1. In the PPO training, we did not limit the length of the generated samples to ensure the accuracy of rewards for long-text tasks. The total experience pool size for each training exceeded 100k samples, ensuring the sufficiency of the training.
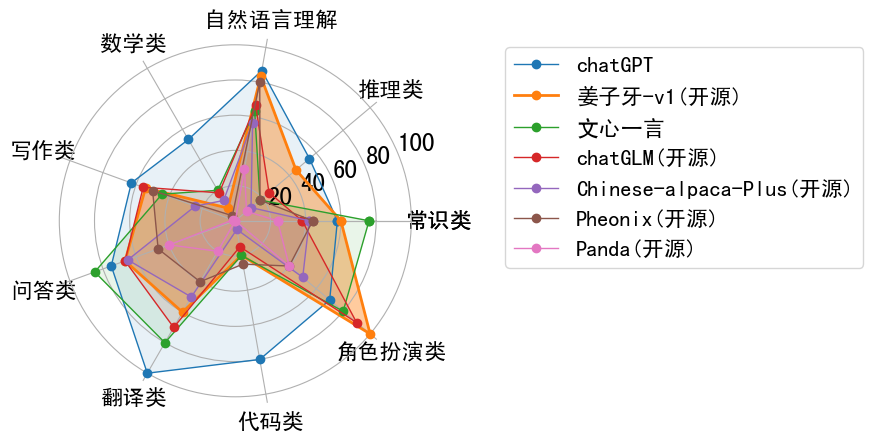
Performance
💻 Usage Examples
Basic Usage
Due to the licensing restrictions of LLaMA weights, the utilization of the model for commercial purposes is precluded. Please strictly respect LLaMA's usage policy. Considering the licensing limitations on LLaMA weights, we are unable to directly release the complete model weights. Therefore, we utilized the open-source FastChat tool and further optimized it to calculate the differences between Ziya-LLaMA-13B-v1 weights and the original LLaMA weights. Users can follow the steps to obtain the complete weights of Ziya-LLaMA-13B-v1. The steps are as follows:
Step 1: Obtain the LLaMA weights and convert them into the Hugging Face Transformers format. You can refer to the script (skip this step if you already have the Hugging Face weights).
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 13B --output_dir /output/path
Step 2: Download the delta weights for Ziya-LLaMA-13B-v1 and the pre-converted original LLaMA weights from step 1. Use the following script for conversion: https://github.com/IDEA-CCNL/Fengshenbang-LM/blob/main/fengshen/utils/apply_delta.py
python3 -m apply_delta --base ~/model_weights/llama-13b --target ~/model_weights/Ziya-LLaMA-13B --delta ~/model_weights/Ziya-LLaMA-13B-v1
Step 3: Load the model obtained in Step 2 for inference.
from transformers import AutoTokenizer
from transformers import LlamaForCausalLM
import torch
device = torch.device("cuda")
ckpt = 'Complete model weights merged based on delta parameters'
query="Help me write a travel plan to Xi'an"
model = LlamaForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(ckpt, use_fast=False)
inputs = '<human>:' + query.strip() + '\n<bot>:'
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=1024,
do_sample = True,
top_p = 0.85,
temperature = 1.0,
repetition_penalty=1.,
eos_token_id=2,
bos_token_id=1,
pad_token_id=0)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
📄 License
The model is licensed under GPL-3.0.
📚 Finetune Example
Refer to ziya_finetune
📚 Inference & Quantization Example
Refer to ziya_inference
📖 Citation
If you are using the resource for your work, please cite the our paper:
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
You can also cite our website:
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)