🚀 SMILES 基狀態空間編解碼器 (SMI - SSED) - MoLMamba
本項目提供了與我們的論文 “A Mamba - Based Foundation Model for Chemistry” 相關的 PyTorch 源代碼。該項目基於 Mamba 架構構建了一個化學基礎模型,可用於解決化學領域的多種複雜任務,具有重要的科研和應用價值。
🚀 快速開始
預訓練模型和訓練日誌
我們提供了在從 PubChem 精心挑選的約 9100 萬個分子數據集上預訓練的 SMI - SSED 模型的檢查點。該預訓練模型在 MoleculeNet 的分類和迴歸基準測試中表現出色。
根據需求,將 SMI - SSED 的 預訓練權重.pt 文件添加到 inference/ 或 finetune/ 目錄中。目錄結構應如下所示:
inference/
├── smi_ssed
│ ├── smi_ssed.pt
│ ├── bert_vocab_curated.txt
│ └── load.py
和/或:
finetune/
├── smi_ssed
│ ├── smi_ssed.pt
│ ├── bert_vocab_curated.txt
│ └── load.py
複製 Conda 環境
按照以下步驟複製我們的 Conda 環境並安裝必要的庫:
創建並激活 Conda 環境
conda create --name smi-ssed-env python=3.10
conda activate smi-ssed-env
使用 Conda 安裝包
conda install pytorch=2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidia
使用 Pip 安裝包
pip install -r requirements.txt
✨ 主要特性
- 多任務支持:支持量子屬性預測等多種複雜任務。
- 雙格式模型權重:提供 PyTorch (
.pt) 和 safetensors (.bin) 兩種格式的模型權重。
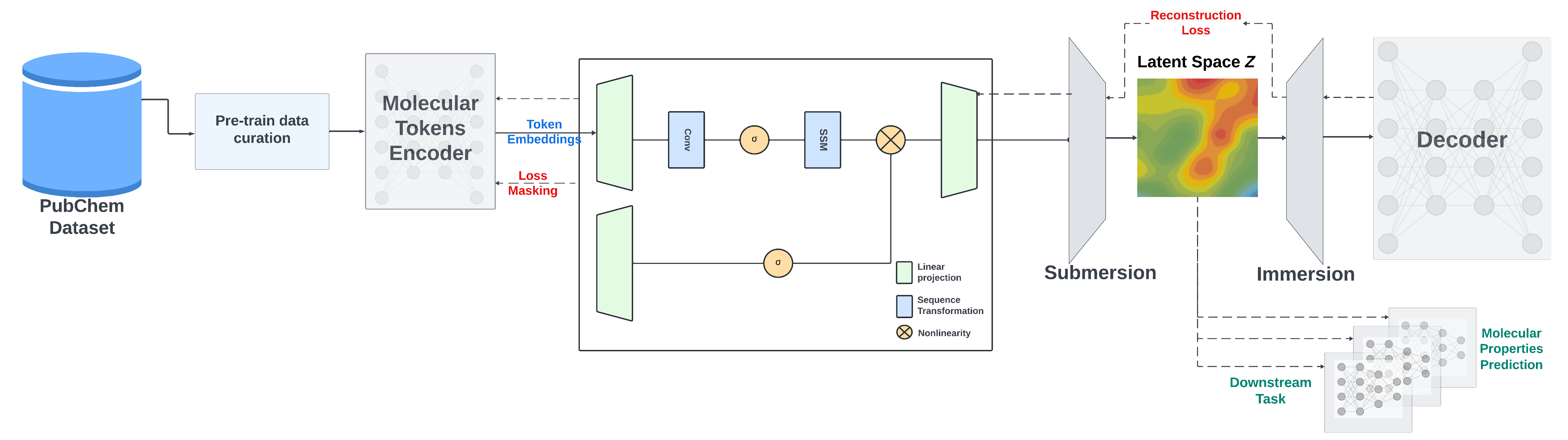
- 預訓練策略多樣:採用掩碼語言模型方法訓練編碼器部分,以及編碼器 - 解碼器策略優化 SMILES 重建和改善生成的潛在空間。
📦 安裝指南
預訓練
對於預訓練,我們採用兩種策略:使用掩碼語言模型方法訓練編碼器部分,以及使用編碼器 - 解碼器策略優化 SMILES 重建並改善生成的潛在空間。
SMI - SSED 在來自 PubChem 的 9100 萬個經過規範化和精心挑選的 SMILES 上進行預訓練,並遵循以下約束條件:
- 預處理期間,化合物過濾為最大長度 202 個標記。
- 編碼器訓練使用 95/5/0 分割,其中 5% 的數據用於解碼器預訓練。
- 還使用 100/0/0 分割直接訓練編碼器和解碼器,以提高模型性能。
預訓練代碼提供了在較小數據集上進行數據處理和模型訓練的示例,需要 8 個 A100 GPU。
要預訓練 SMI - SSED 模型,請運行:
bash training/run_model_training.sh
使用 train_model_D.py 僅訓練解碼器,或使用 train_model_ED.py 訓練編碼器和解碼器。
微調
微調數據集和環境可在 finetune 目錄中找到。設置好環境後,可以運行以下命令進行微調任務:
bash finetune/smi_ssed/esol/run_finetune_esol.sh
微調訓練/檢查點資源將在名為 checkpoint_<measure_name> 的目錄中可用。
💻 使用示例
基礎用法
model = load_smi_ssed(
folder='../inference/smi_ssed',
ckpt_filename='smi_ssed.pt'
)
高級用法
編碼 SMILES 為嵌入向量
with torch.no_grad():
encoded_embeddings = model.encode(df['SMILES'], return_torch=True)
解碼嵌入向量為 SMILES 字符串
with torch.no_grad():
decoded_smiles = model.decode(encoded_embeddings)
📚 詳細文檔
特徵提取
示例筆記本 smi_ssed_encoder_decoder_example.ipynb 包含加載檢查點文件並使用預訓練模型進行編碼器和解碼器任務的代碼。它還包括分類和迴歸任務的示例。模型權重可在 HuggingFace 鏈接 獲取。
📄 許可證
本項目採用 Apache - 2.0 許可證。
其他信息
論文鏈接
論文 NeurIPS AI4Mat 2024:Arxiv 鏈接
聯繫方式
如需更多信息,請聯繫:eduardo.soares@ibm.com 或 evital@br.ibm.com。
模型圖示
模型信息表格
| 屬性 |
詳情 |
| 模型類型 |
基於 Mamba 的編碼器 - 解碼器化學基礎模型 |
| 訓練數據 |
來自 PubChem 的 9100 萬個經過規範化和精心挑選的 SMILES |
| 評估指標 |
準確率 |
| 任務類型 |
特徵提取 |
| 標籤 |
化學、基礎模型、AI4Science、材料、分子、safetensors、pytorch、transformer、diffusers |
| 庫名稱 |
transformers |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors PyTorch
PyTorch Transformers 支持多種語言
Transformers 支持多種語言