🚀 SMILES-based State-Space Encoder-Decoder (SMI-SSED) - MoLMamba
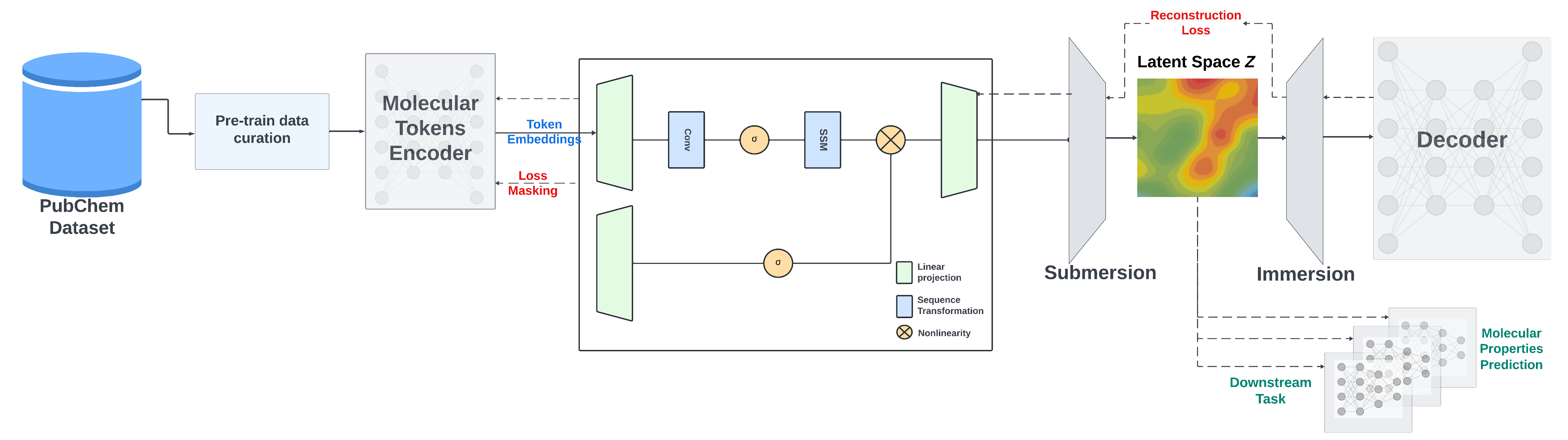
This repository offers PyTorch source code related to our publication, "A Mamba-Based Foundation Model for Chemistry". It presents a Mamba - based encoder - decoder chemical foundation model, which can handle various complex chemical tasks, providing model weights in different formats and detailed instructions for getting started, pretraining, finetuning, and feature extraction.
Paper NeurIPS AI4Mat 2024: Arxiv Link
For more information, contact: eduardo.soares@ibm.com or evital@br.ibm.com.
✨ Features
- Powerful Model: A Mamba - based encoder - decoder chemical foundation model, pre - trained on a large dataset of 91 million SMILES samples.
- Task Support: Supports various complex tasks, including quantum property prediction, with two main variants ($336$ and $8 \times 336M$).
- Multiple Model Formats: Model weights are provided in PyTorch (
.pt) and safetensors (.bin) formats.
- Comprehensive Documentation: Detailed instructions for getting started, pretraining, finetuning, and feature extraction are provided.
🚀 Quick Start
This code and environment have been tested on Nvidia V100s and Nvidia A100s
📦 Installation
Pretrained Models and Training Logs
We offer checkpoints of the SMI - SSED model pre - trained on a dataset of ~91M molecules from PubChem. The pre - trained model shows good performance on classification and regression benchmarks from MoleculeNet.
Add the SMI - SSED pre - trained weights.pt to the inference/ or finetune/ directory as needed. The directory structure should be as follows:
inference/
├── smi_ssed
│ ├── smi_ssed.pt
│ ├── bert_vocab_curated.txt
│ └── load.py
and/or:
finetune/
├── smi_ssed
│ ├── smi_ssed.pt
│ ├── bert_vocab_curated.txt
│ └── load.py
Replicating Conda Environment
Follow these steps to replicate our Conda environment and install the necessary libraries:
Create and Activate Conda Environment
conda create --name smi - ssed - env python = 3.10
conda activate smi - ssed - env
Install Packages with Conda
conda install pytorch = 2.1.0 pytorch - cuda = 11.8 - c pytorch - c nvidia
Install Packages with Pip
pip install - r requirements.txt
📚 Documentation
Pretraining
For pretraining, we use two strategies: the masked language model method to train the encoder part and an encoder - decoder strategy to refine SMILES reconstruction and improve the generated latent space.
SMI - SSED is pre - trained on canonicalized and curated 91M SMILES from PubChem with the following constraints:
- Compounds are filtered to a maximum length of 202 tokens during preprocessing.
- A 95/5/0 split is used for encoder training, with 5% of the data for decoder pretraining.
- A 100/0/0 split is also used to train the encoder and decoder directly, enhancing model performance.
The pretraining code provides examples of data processing and model training on a smaller dataset, requiring 8 A100 GPUs.
To pre - train the SMI - SSED model, run:
bash training/run_model_training.sh
Use train_model_D.py to train only the decoder or train_model_ED.py to train both the encoder and decoder.
Finetuning
The finetuning datasets and environment can be found in the finetune directory. After setting up the environment, you can run a finetuning task with:
bash finetune/smi_ssed/esol/run_finetune_esol.sh
Finetuning training/checkpointing resources will be available in directories named checkpoint_<measure_name>.
Feature Extraction
The example notebook smi_ssed_encoder_decoder_example.ipynb contains code to load checkpoint files and use the pre - trained model for encoder and decoder tasks. It also includes examples of classification and regression tasks. For model weights: [HuggingFace Link](https://huggingface.co/ibm/materials.smi - ted)
💻 Usage Examples
Basic Usage
To load smi - ssed, you can simply use:
model = load_smi_ssed(
folder='../inference/smi_ssed',
ckpt_filename='smi_ssed.pt'
)
Advanced Usage
To encode SMILES into embeddings, you can use:
with torch.no_grad():
encoded_embeddings = model.encode(df['SMILES'], return_torch=True)
For decoder, you can use the function to return from embeddings to SMILES strings:
with torch.no_grad():
decoded_smiles = model.decode(encoded_embeddings)
📄 License
This project is licensed under the Apache - 2.0 license.
| Property |
Details |
| Model Type |
SMILES - based State - Space Encoder - Decoder (SMI - SSED) |
| Training Data |
91 million SMILES samples from PubChem |
| Library Name |
transformers |
| Metrics |
accuracy |
| Pipeline Tag |
feature - extraction |
| Tags |
chemistry, foundation models, AI4Science, materials, molecules, safetensors, pytorch, transformer, diffusers |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors PyTorch
PyTorch