🚀 SMILESベースの状態空間エンコーダーデコーダー (SMI - SSED) - MoLMamba
このリポジトリは、我々の論文「A Mamba - Based Foundation Model for Chemistry」に関連するPyTorchのソースコードを提供しています。
論文NeurIPS AI4Mat 2024: Arxivリンク
詳細については、eduardo.soares@ibm.com または evital@br.ibm.com までご連絡ください。
✨ 主な機能
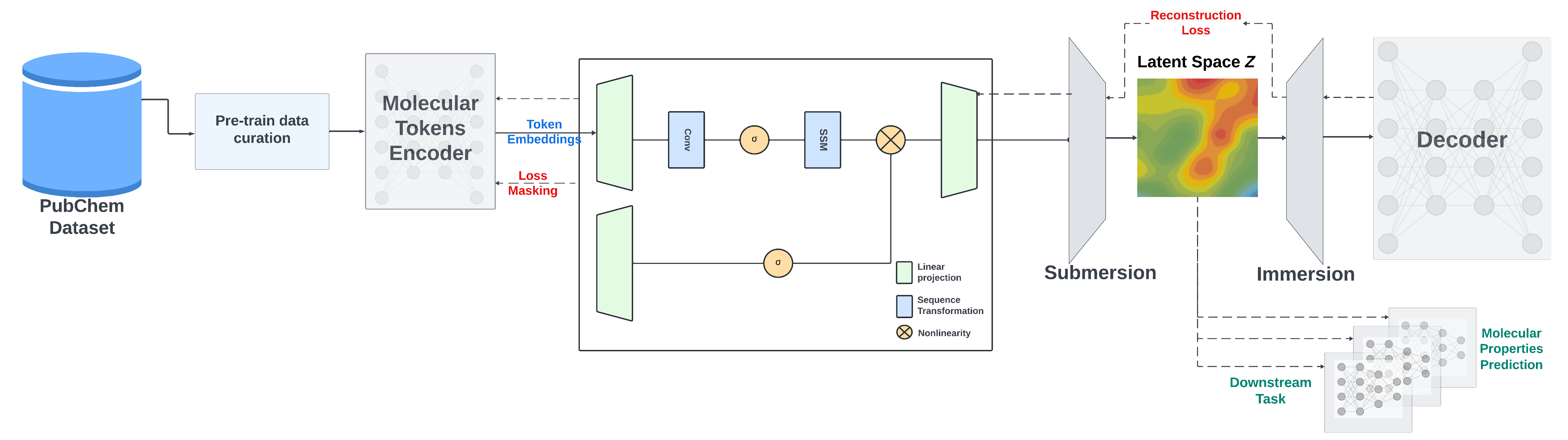
我々は、Mambaベースのエンコーダーデコーダー化学基礎モデルである、SMILESベースの状態空間エンコーダーデコーダー (SMI - SSED) を提案します。このモデルは、PubChemから収集された9100万のSMILESサンプル(約40億の分子トークンに相当)の精選データセットで事前学習されています。SMI - SSEDは、量子特性予測を含むさまざまな複雑なタスクをサポートし、主に2つのバリエーション($336$ と $8 \times 336M$)があります。複数のベンチマークデータセットでの実験により、さまざまなタスクにおいて最先端の性能が実証されています。
モデルの重みは2つの形式で提供されます:
詳細については、eduardo.soares@ibm.com または evital@br.ibm.com までご連絡ください。
🚀 クイックスタート
このコードと環境は、Nvidia V100およびNvidia A100でテストされています
📦 事前学習済みモデルとトレーニングログ
我々は、PubChemから精選された約9100万の分子のデータセットで事前学習されたSMI - SSEDモデルのチェックポイントを提供しています。事前学習済みモデルは、MoleculeNetの分類および回帰ベンチマークで競争力のある性能を示します。
必要に応じて、SMI - SSEDの 事前学習済み重み.pt を inference/ または finetune/ ディレクトリに追加してください。ディレクトリ構造は次のようになります。
inference/
├── smi_ssed
│ ├── smi_ssed.pt
│ ├── bert_vocab_curated.txt
│ └── load.py
および/または:
finetune/
├── smi_ssed
│ ├── smi_ssed.pt
│ ├── bert_vocab_curated.txt
│ └── load.py
📦 コンダ環境の複製
以下の手順に従って、我々のコンダ環境を複製し、必要なライブラリをインストールしてください。
コンダ環境の作成とアクティブ化
conda create --name smi-ssed-env python=3.10
conda activate smi-ssed-env
コンダでのパッケージのインストール
conda install pytorch=2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidia
Pipでのパッケージのインストール
pip install -r requirements.txt
🔧 事前学習
事前学習には、2つの戦略を使用しています。エンコーダー部分をトレーニングするためのマスク付き言語モデル手法と、SMILESの再構築を改善し、生成された潜在空間を向上させるためのエンコーダーデコーダー戦略です。
SMI - SSEDは、PubChemからの正規化され精選された9100万のSMILESで、以下の制約条件で事前学習されています。
- 前処理中に化合物は最大202トークンの長さにフィルタリングされます。
- エンコーダーのトレーニングには95/5/0の分割が使用され、デコーダーの事前学習には5%のデータが使用されます。
- エンコーダーとデコーダーを直接トレーニングするために100/0/0の分割も使用され、モデルの性能が向上します。
事前学習コードは、小さなデータセットでのデータ処理とモデルトレーニングの例を提供しており、8台のA100 GPUが必要です。
SMI - SSEDモデルを事前学習するには、次のコマンドを実行します。
bash training/run_model_training.sh
train_model_D.py を使用してデコーダーのみをトレーニングするか、train_model_ED.py を使用してエンコーダーとデコーダーの両方をトレーニングします。
🔧 ファインチューニング
ファインチューニングのデータセットと環境は、finetune ディレクトリにあります。環境をセットアップした後、次のコマンドでファインチューニングタスクを実行できます。
bash finetune/smi_ssed/esol/run_finetune_esol.sh
ファインチューニングのトレーニング/チェックポイントリソースは、checkpoint_<measure_name> という名前のディレクトリに保存されます。
💻 使用例
基本的な使用法
特徴抽出の例のノートブック smi_ssed_encoder_decoder_example.ipynb には、チェックポイントファイルを読み込み、事前学習済みモデルをエンコーダーとデコーダーのタスクに使用するコードが含まれています。また、分類および回帰タスクの例も含まれています。モデルの重みについては、HuggingFaceリンク を参照してください。
smi - ssedを読み込むには、次のようにします。
model = load_smi_ssed(
folder='../inference/smi_ssed',
ckpt_filename='smi_ssed.pt'
)
SMILESを埋め込みにエンコードするには、次のようにします。
with torch.no_grad():
encoded_embeddings = model.encode(df['SMILES'], return_torch=True)
デコーダーについては、次の関数を使用して、埋め込みからSMILES文字列に戻すことができます。
with torch.no_grad():
decoded_smiles = model.decode(encoded_embeddings)
📄 ライセンス
このプロジェクトは、Apache - 2.0ライセンスの下でライセンスされています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors PyTorch
PyTorch Transformers 複数言語対応
Transformers 複数言語対応