🚀 WizardLM-2-7B-abliterated
這是基於 @failspy 實現的、具有正交化bfloat16 safetensor權重的 WizardLM-2-7B 模型。更多信息如下:
📦 GGUF文件
我將在此處上傳一些GGUF文件:https://huggingface.co/fearlessdots/WizardLM-2-7B-abliterated-GGUF
💬 提示模板
此模型使用 Vicuna 的提示格式,並支持 多輪 對話。
原始模型卡片:
🏠 WizardLM-2發佈博客
🤗 HF倉庫 •🐱 Github倉庫 • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 加入我們的 Discord
🗞️ 新聞 🔥🔥🔥 [2024/04/15]
我們推出並開源了下一代最先進的大語言模型WizardLM-2,它在複雜對話、多語言、推理和智能體等方面的性能有所提升。新系列包括三款前沿模型:WizardLM-2 8x22B、WizardLM-2 70B和WizardLM-2 7B。
- WizardLM-2 8x22B是我們最先進的模型,與領先的專有模型相比表現出極具競爭力的性能,並且始終優於所有現有的最先進開源模型。
- WizardLM-2 70B達到了頂級推理能力,是相同規模下的首選。
- WizardLM-2 7B是最快的模型,並且與現有規模大10倍的開源領先模型取得了相當的性能。
有關WizardLM-2的更多詳細信息,請閱讀我們的 發佈博客文章 和即將發表的論文。
📋 模型詳情
💪 模型能力
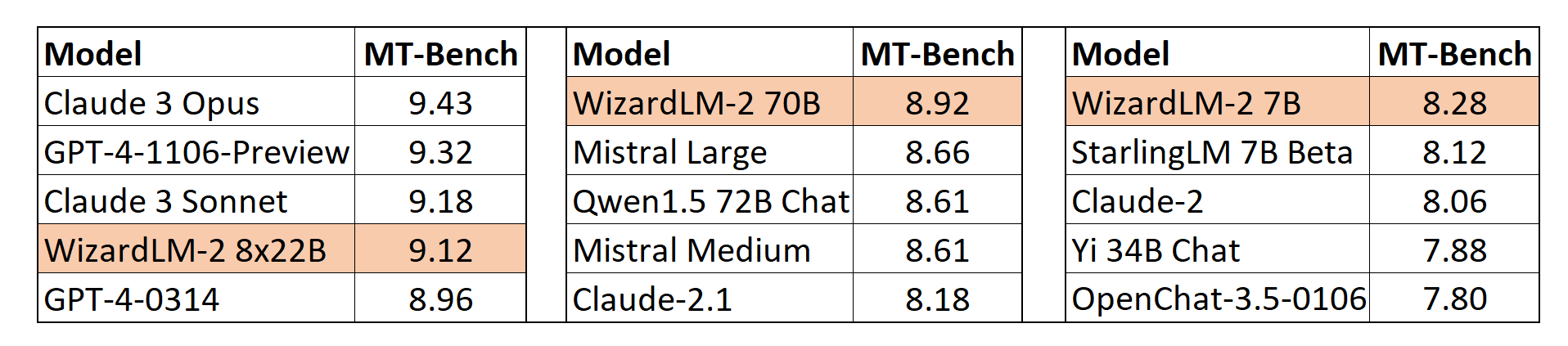
MT-Bench
我們還採用了lmsys提出的基於GPT-4的自動MT-Bench評估框架來評估模型性能。WizardLM-2 8x22B與最先進的專有模型相比,甚至表現出極具競爭力的性能。同時,WizardLM-2 7B和WizardLM-2 70B在7B到70B模型規模的其他領先基線模型中均為表現最佳的模型。
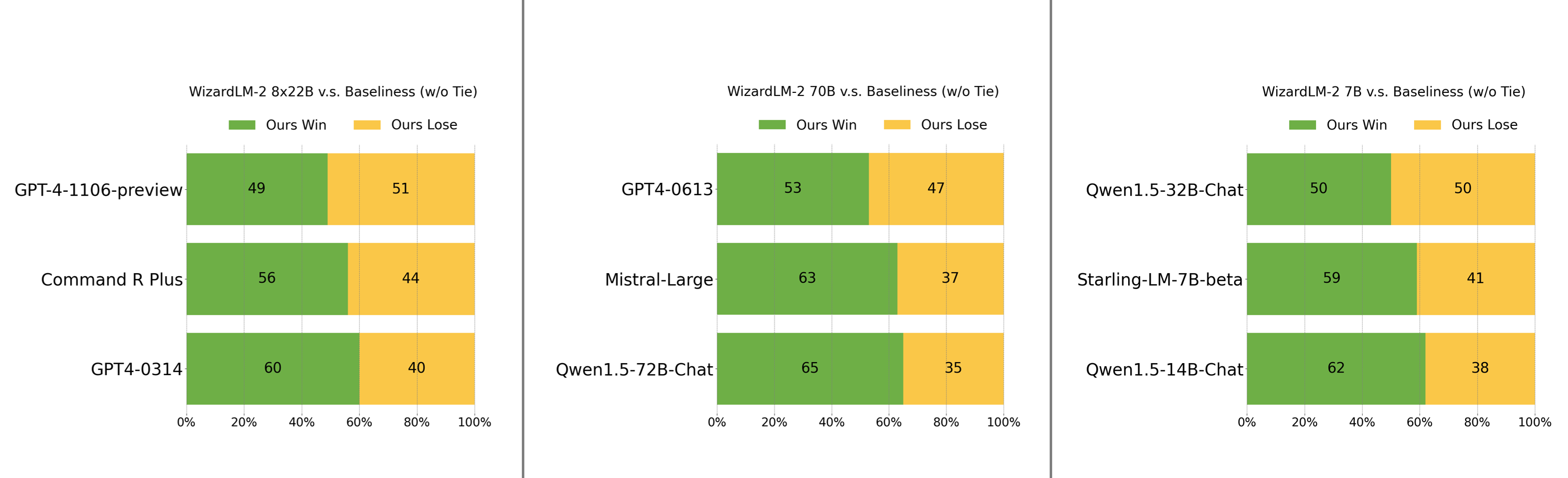
人工偏好評估
我們精心收集了一組複雜且具有挑戰性的真實世界指令集,其中包括人類的主要需求,如寫作、編碼、數學、推理、智能體和多語言。我們報告了無平局的勝負率:
- WizardLM-2 8x22B僅略遜於GPT-4-1106-preview,並且明顯強於Command R Plus和GPT4-0314。
- WizardLM-2 70B優於GPT4-0613、Mistral-Large和Qwen1.5-72B-Chat。
- WizardLM-2 7B與Qwen1.5-32B-Chat相當,並且超越了Qwen1.5-14B-Chat和Starling-LM-7B-beta。
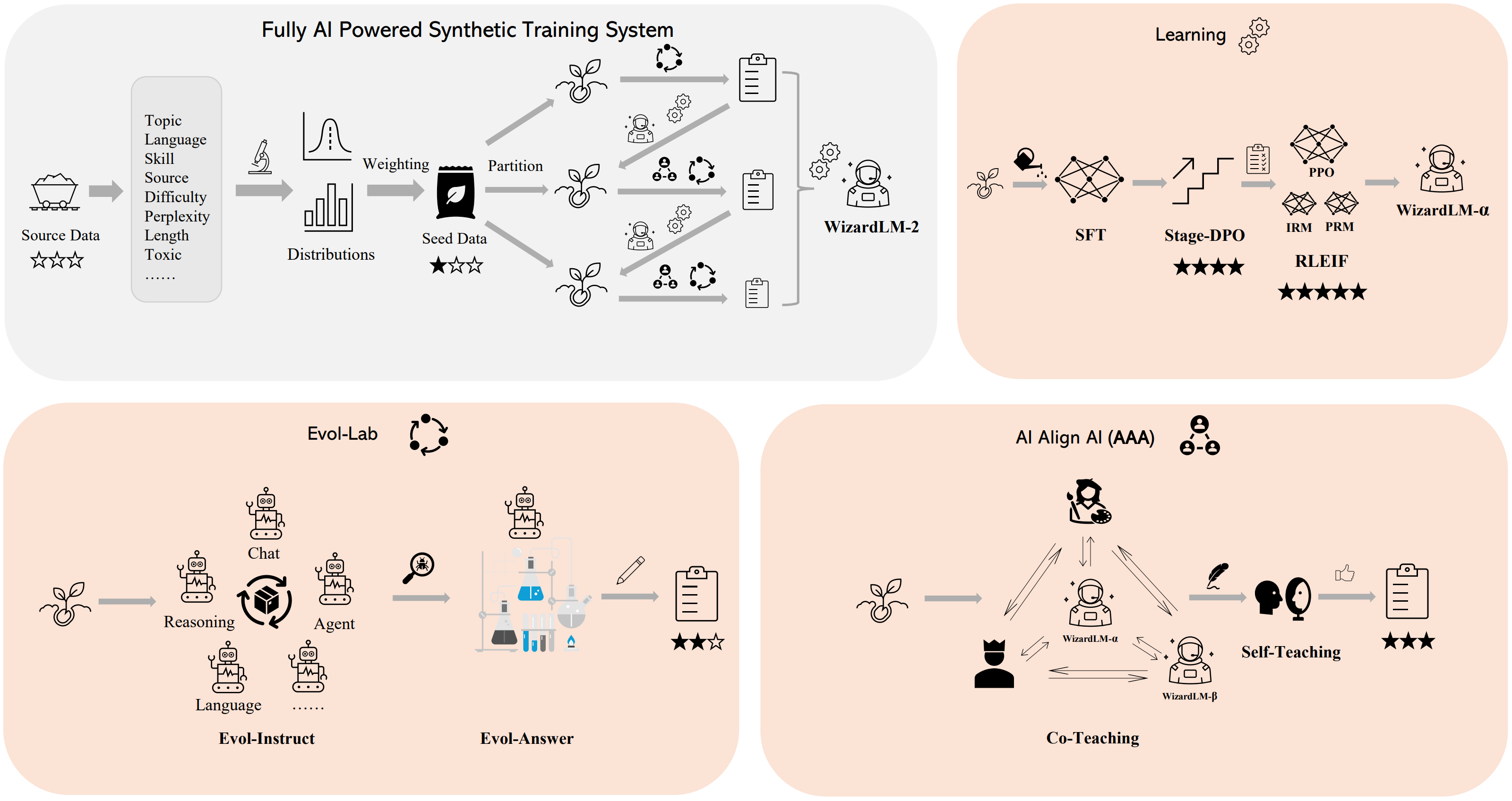
🛠️ 方法概述
我們構建了一個 全AI驅動的合成訓練系統 來訓練WizardLM-2模型,有關該系統的更多詳細信息,請參考我們的 博客。
💻 使用方法
⚠️ 重要提示
WizardLM-2 採用 Vicuna 的提示格式,並支持 多輪 對話。提示應如下所示:
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......
推理WizardLM-2演示腳本
我們在github上提供了一個WizardLM-2推理演示 代碼。
📄 許可證
本項目採用Apache-2.0許可證。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言