🚀 WizardLM-2-7B-abliterated
这是基于 @failspy 实现的、具有正交化bfloat16 safetensor权重的 WizardLM-2-7B 模型。更多信息如下:
📦 GGUF文件
我将在此处上传一些GGUF文件:https://huggingface.co/fearlessdots/WizardLM-2-7B-abliterated-GGUF
💬 提示模板
此模型使用 Vicuna 的提示格式,并支持 多轮 对话。
原始模型卡片:
🏠 WizardLM-2发布博客
🤗 HF仓库 •🐱 Github仓库 • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 加入我们的 Discord
🗞️ 新闻 🔥🔥🔥 [2024/04/15]
我们推出并开源了下一代最先进的大语言模型WizardLM-2,它在复杂对话、多语言、推理和智能体等方面的性能有所提升。新系列包括三款前沿模型:WizardLM-2 8x22B、WizardLM-2 70B和WizardLM-2 7B。
- WizardLM-2 8x22B是我们最先进的模型,与领先的专有模型相比表现出极具竞争力的性能,并且始终优于所有现有的最先进开源模型。
- WizardLM-2 70B达到了顶级推理能力,是相同规模下的首选。
- WizardLM-2 7B是最快的模型,并且与现有规模大10倍的开源领先模型取得了相当的性能。
有关WizardLM-2的更多详细信息,请阅读我们的 发布博客文章 和即将发表的论文。
📋 模型详情
💪 模型能力
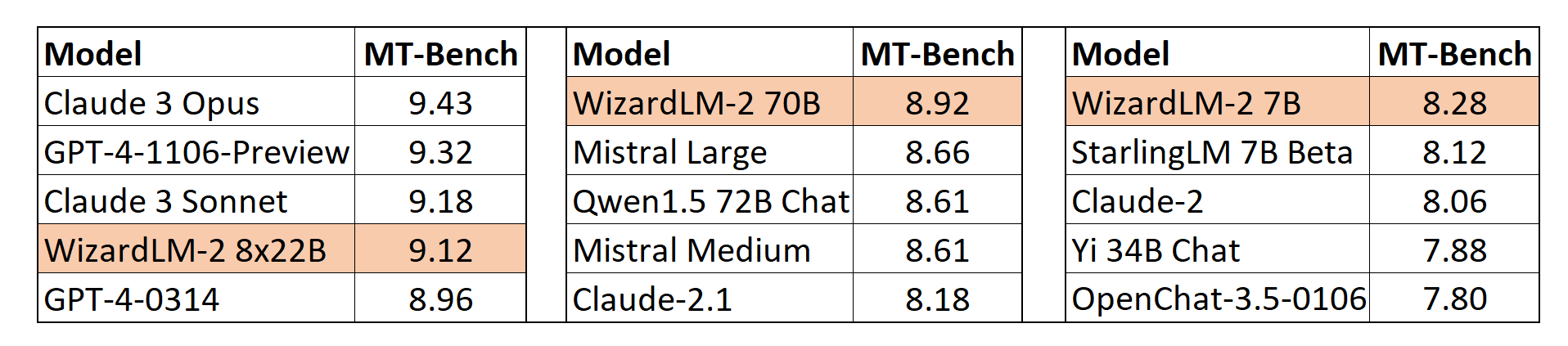
MT-Bench
我们还采用了lmsys提出的基于GPT-4的自动MT-Bench评估框架来评估模型性能。WizardLM-2 8x22B与最先进的专有模型相比,甚至表现出极具竞争力的性能。同时,WizardLM-2 7B和WizardLM-2 70B在7B到70B模型规模的其他领先基线模型中均为表现最佳的模型。
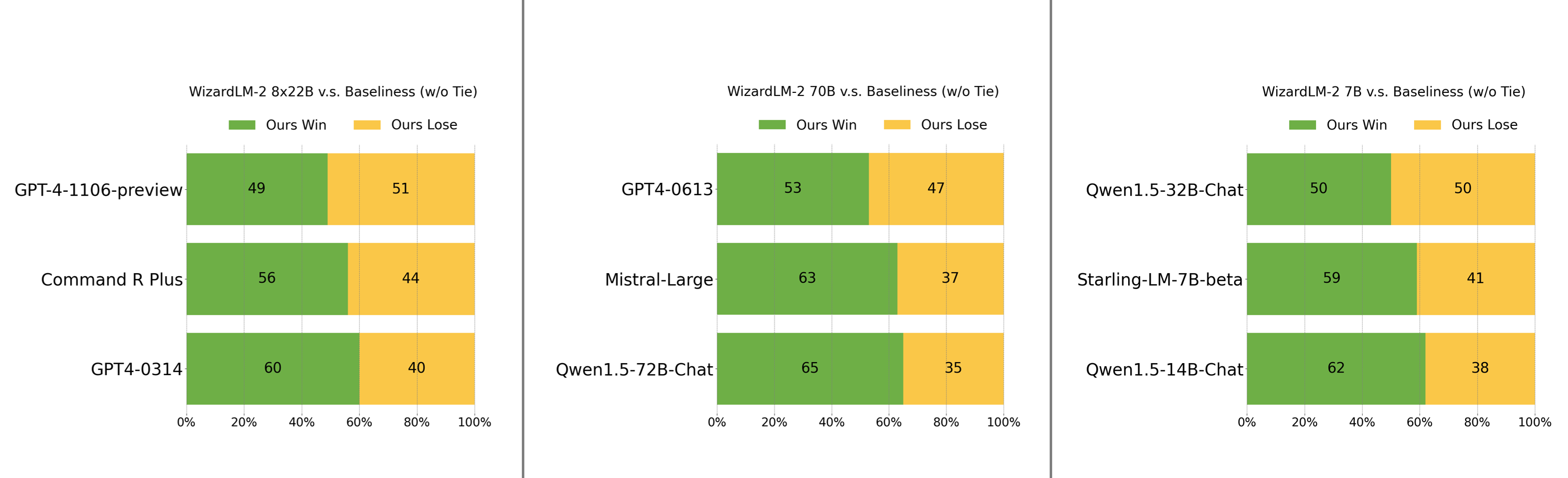
人工偏好评估
我们精心收集了一组复杂且具有挑战性的真实世界指令集,其中包括人类的主要需求,如写作、编码、数学、推理、智能体和多语言。我们报告了无平局的胜负率:
- WizardLM-2 8x22B仅略逊于GPT-4-1106-preview,并且明显强于Command R Plus和GPT4-0314。
- WizardLM-2 70B优于GPT4-0613、Mistral-Large和Qwen1.5-72B-Chat。
- WizardLM-2 7B与Qwen1.5-32B-Chat相当,并且超越了Qwen1.5-14B-Chat和Starling-LM-7B-beta。
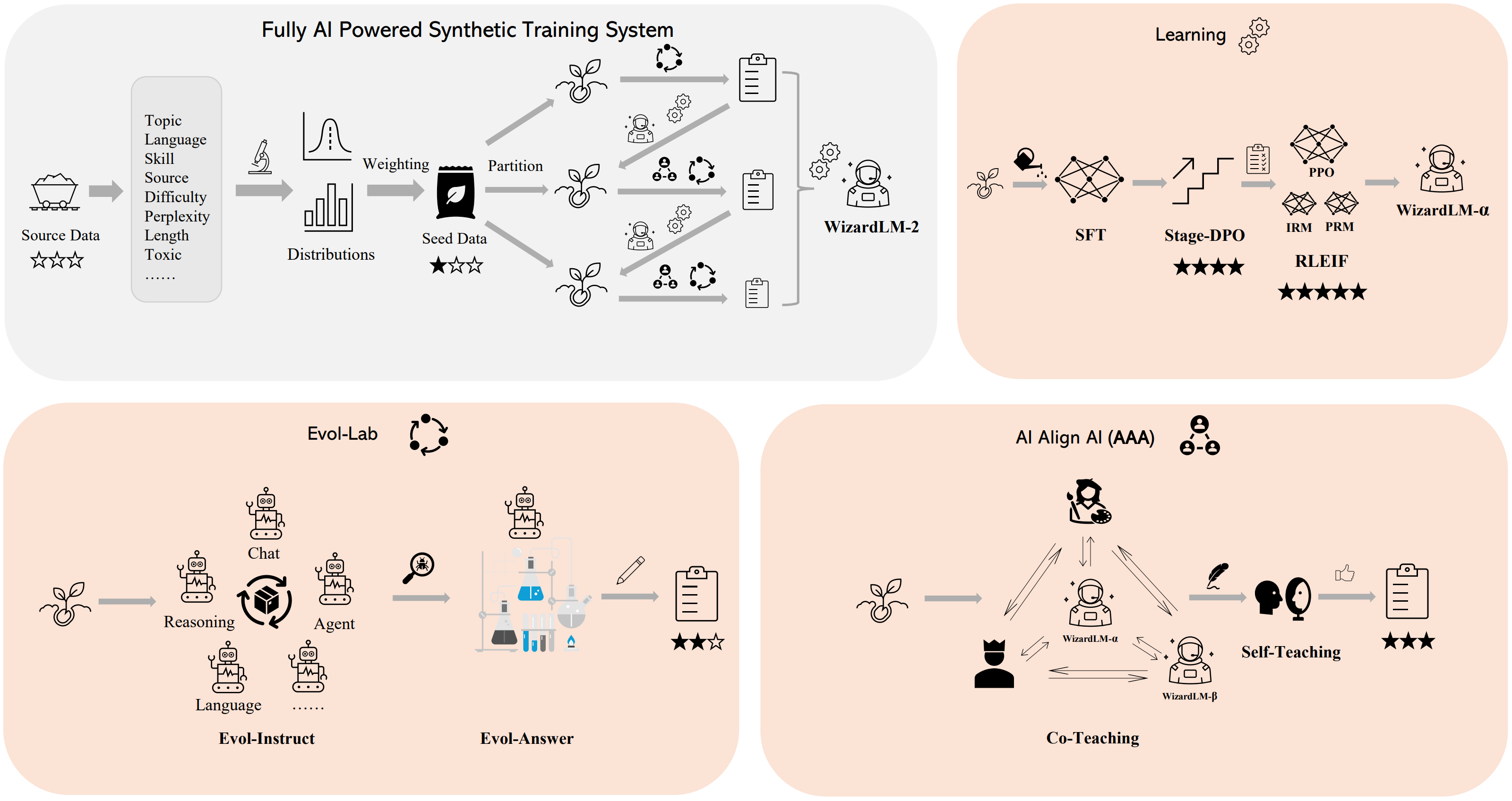
🛠️ 方法概述
我们构建了一个 全AI驱动的合成训练系统 来训练WizardLM-2模型,有关该系统的更多详细信息,请参考我们的 博客。
💻 使用方法
⚠️ 重要提示
WizardLM-2 采用 Vicuna 的提示格式,并支持 多轮 对话。提示应如下所示:
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......
推理WizardLM-2演示脚本
我们在github上提供了一个WizardLM-2推理演示 代码。
📄 许可证
本项目采用Apache-2.0许可证。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言