🚀 WizardLM-2-7B-abliterated
このモデルは、@failspyによる実装に基づいた、直交化されたbfloat16 safetensorの重みを持つWizardLM-2-7Bモデルです。詳細については以下を参照してください。
📦 GGUFファイル
GGUFファイルをここにアップロードします: https://huggingface.co/fearlessdots/WizardLM-2-7B-abliterated-GGUF
📝 プロンプトテンプレート
このモデルはVicunaのプロンプト形式を使用し、マルチターン会話をサポートしています。
オリジナルのモデルカード:
🏠 WizardLM-2リリースブログ
🤗 HFリポジトリ •🐱 GitHubリポジトリ • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Discordに参加しましょう
🗞️ ニュース 🔥🔥🔥 [2024/04/15]
我々は、次世代の最先端大規模言語モデルであるWizardLM-2を導入し、オープンソース化しました。このモデルは、複雑なチャット、多言語、推論、エージェントなどの性能が向上しています。新しいモデルファミリーには、3つの最先端モデルが含まれています。
- WizardLM-2 8x22B: 我々の最も高度なモデルで、主要なプロプライエタリモデルと比較しても非常に競争力のある性能を示し、既存の最先端オープンソースモデルを一貫して上回ります。
- WizardLM-2 70B: トップレベルの推論能力を持ち、同サイズのモデルの中では第一選択です。
- WizardLM-2 7B: 最も高速で、既存の10倍大きいオープンソースの主要モデルと同等の性能を達成します。
WizardLM-2の詳細については、リリースブログ記事と今後公開される論文をご覧ください。
📚 モデル詳細
💪 モデルの能力
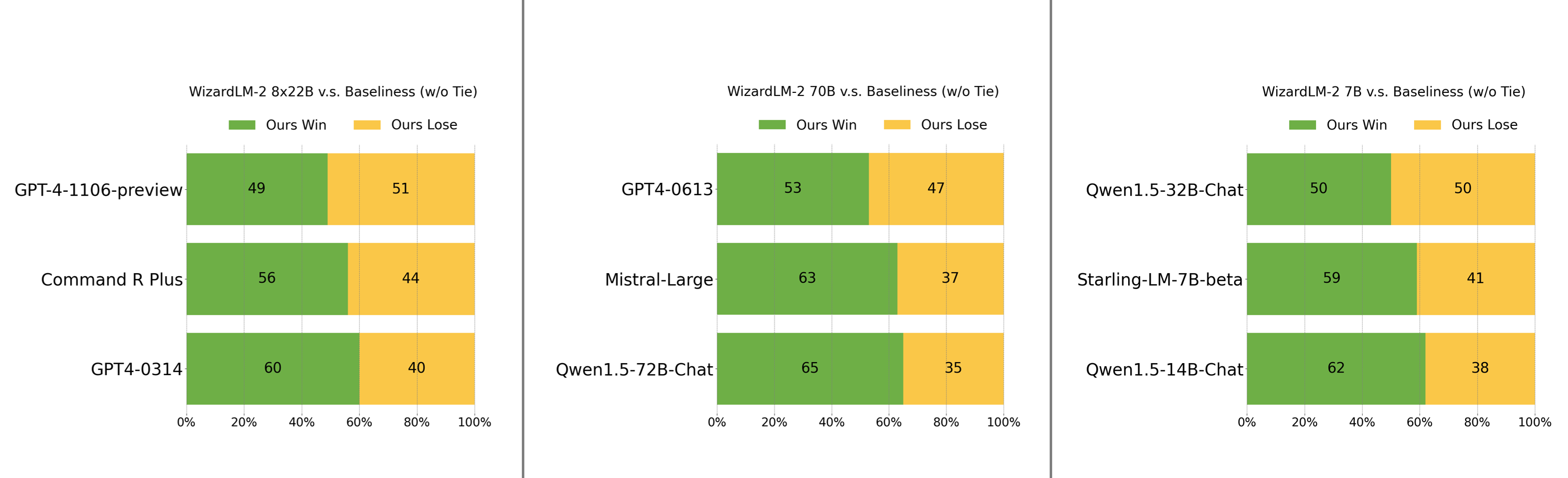
MT-Bench
我々は、lmsysによって提案されたGPT-4ベースの自動MT-Bench評価フレームワークを採用して、モデルの性能を評価しています。WizardLM-2 8x22Bは、最も高度なプロプライエタリモデルと比較しても非常に競争力のある性能を示します。また、WizardLM-2 7BとWizardLM-2 70Bは、7Bから70Bのモデル規模の他の主要ベースラインの中でもトップクラスの性能を発揮しています。
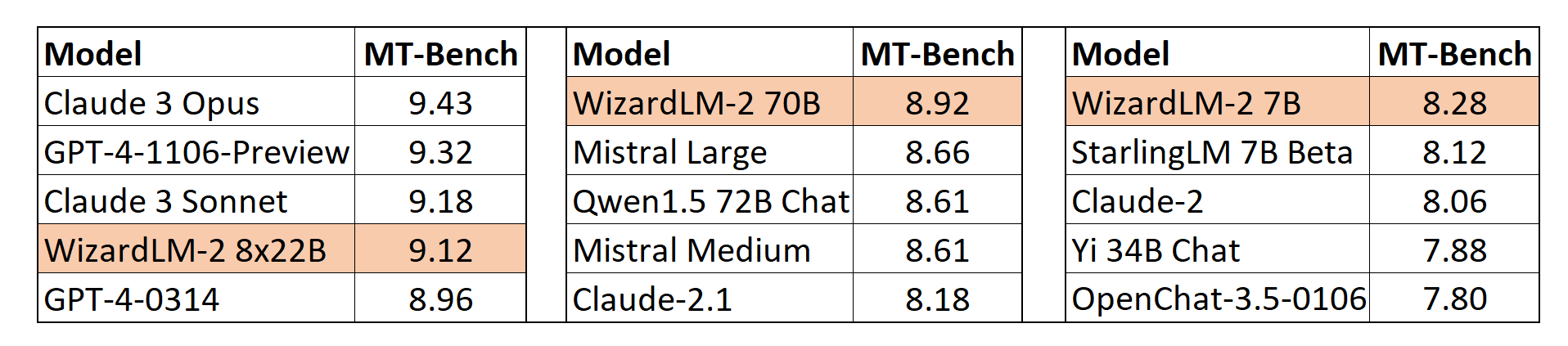
人間の嗜好評価
我々は、実世界の命令から構成される複雑で挑戦的なセットを慎重に収集しました。これには、文章作成、コーディング、数学、推論、エージェント、多言語など、人間の主要な要求が含まれています。勝敗率(引き分けを除く)を報告します。
- WizardLM-2 8x22Bは、GPT-4-1106-previewに僅かに劣り、Command R PlusやGPT4-0314よりも大幅に強力です。
- WizardLM-2 70Bは、GPT4-0613、Mistral-Large、Qwen1.5-72B-Chatよりも優れています。
- WizardLM-2 7Bは、Qwen1.5-32B-Chatと同等で、Qwen1.5-14B-ChatやStarling-LM-7B-betaを上回っています。
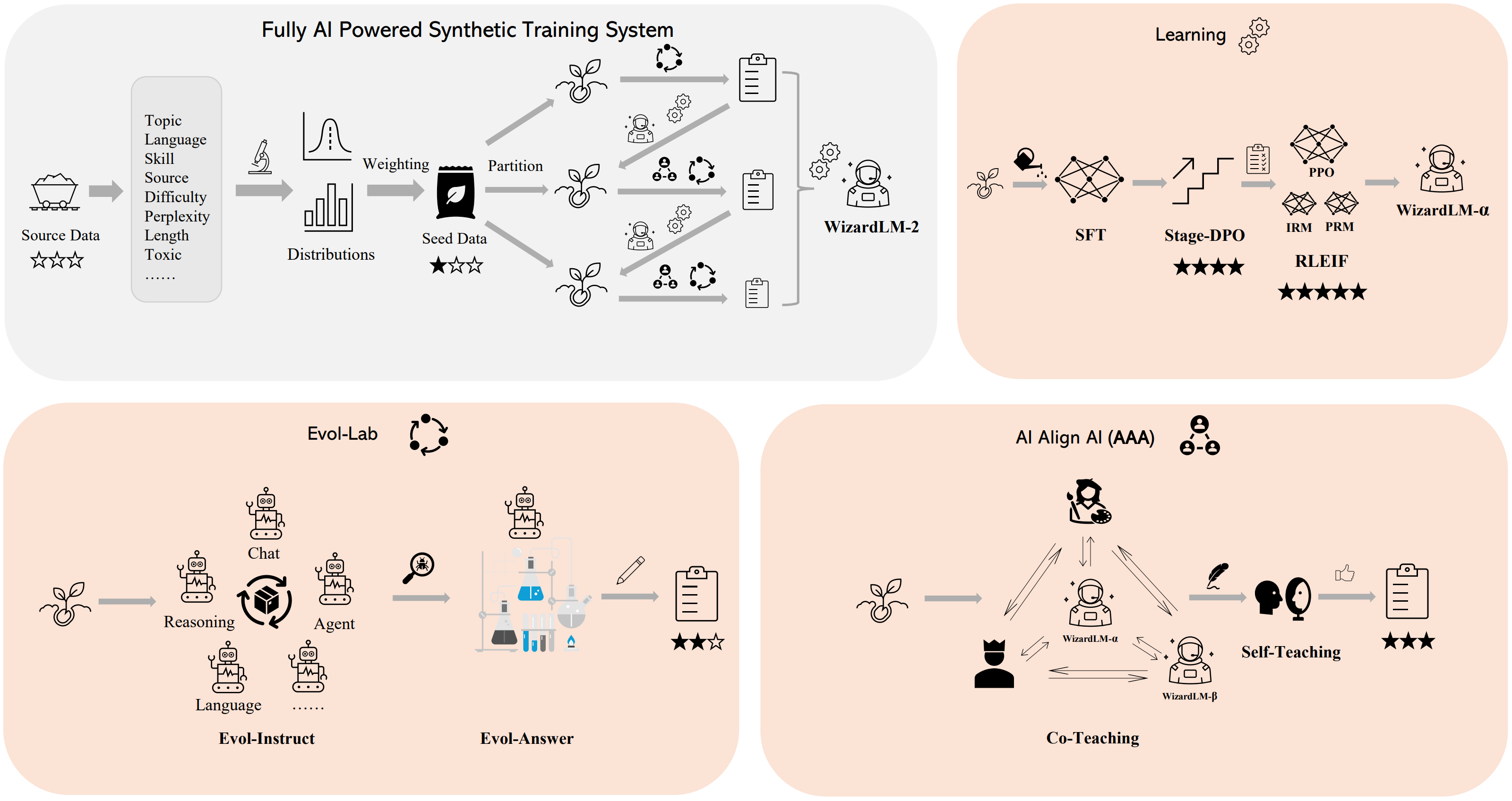
🛠️ 方法論の概要
我々は、WizardLM-2モデルを訓練するために、完全にAI駆動の合成訓練システムを構築しました。このシステムの詳細については、ブログを参照してください。
💻 使用例
基本的な使用法
⚠️ 重要提示
このモデルのシステムプロンプトの使用に関する注意事項です。
WizardLM-2はVicunaのプロンプト形式を採用し、マルチターン会話をサポートしています。プロンプトは以下のようにする必要があります。
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......
高度な使用法
我々は、GitHub上にWizardLM-2の推論デモコードを提供しています。
📄 ライセンス
このモデルはApache2.0ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応