%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 Whisper-Large-V3-French-Distil-Dec16
Whisper-Large-V3-French-Distil是Whisper-Large-V3-French的一系列蒸餾版本。通過將解碼器層數從32層減少到16層、8層、4層或2層,並使用大規模數據集進行蒸餾,具體可參考這篇論文。
這些蒸餾變體在保持性能(取決於保留的層數)的同時,減少了內存使用和推理時間,並降低了幻覺風險,特別是在長文本轉錄中。此外,它們可以與原始的Whisper-Large-V3-French模型無縫結合進行推測性解碼,與單獨使用該模型相比,可提高推理速度並保證輸出的一致性。
該模型已被轉換為多種格式,便於在不同的庫中使用,包括transformers、openai-whisper、fasterwhisper、whisper.cpp、candle、mlx等。
🚀 快速開始
本模型可用於自動語音識別任務,支持多種使用方式和庫,下面將詳細介紹其性能、使用方法、訓練細節等內容。
✨ 主要特性
- 蒸餾優化:減少解碼器層數,降低內存使用和推理時間,同時保持性能並減少幻覺風險。
- 多格式支持:轉換為多種格式,可在transformers、openai-whisper等多個庫中使用。
- 推測性解碼:可與原始模型結合進行推測性解碼,提高推理速度。
📦 安裝指南
根據不同的使用庫,安裝方法有所不同,以下是部分庫的安裝示例:
OpenAI Whisper
pip install -U openai-whisper
Faster Whisper
pip install faster-whisper
Whisper.cpp
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
make
💻 使用示例
Hugging Face Pipeline
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec16"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Init pipeline
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
# chunk_length_s=30, # for long-form transcription
max_new_tokens=128,
)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Run pipeline
result = pipe(sample)
print(result["text"])
Hugging Face Low-level APIs
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec16"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Extract feautres
input_features = processor(
sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt"
).input_features
# Generate tokens
predicted_ids = model.generate(
input_features.to(dtype=torch_dtype).to(device), max_new_tokens=128
)
# Detokenize to text
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
print(transcription)
📚 詳細文檔
性能表現
我們在短文本和長文本轉錄上對模型進行了評估,並在分佈內和分佈外數據集上進行了測試,以全面分析其準確性、泛化性和魯棒性。
請注意,報告的WER是在將數字轉換為文本、去除標點符號(除了撇號和連字符)並將所有字符轉換為小寫後的結果。
所有公共數據集的評估結果可在此處找到。
短文本轉錄
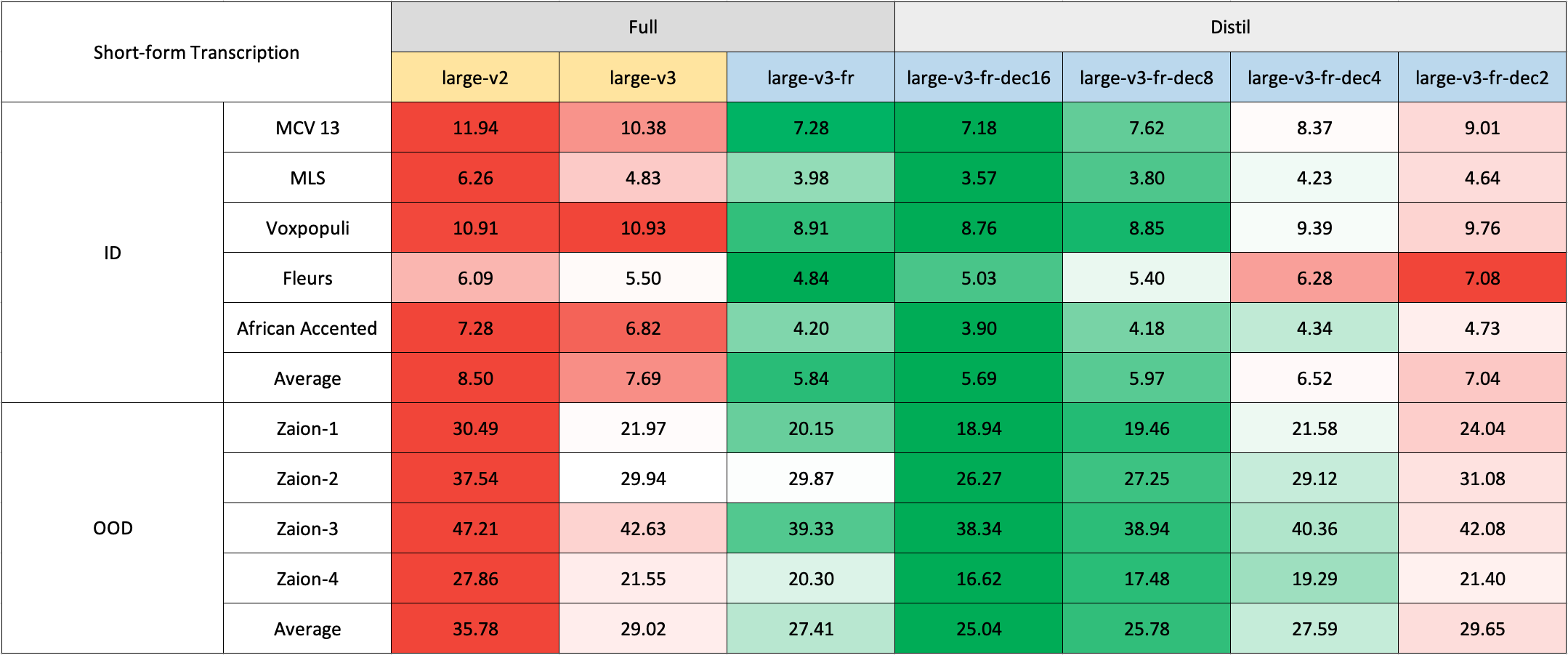
由於缺乏現成的法語域外(OOD)和長文本測試集,我們使用了Zaion Lab的內部測試集進行評估。這些測試集包含了來自呼叫中心對話的人工標註音頻轉錄對,其背景噪音明顯且包含特定領域的術語。
長文本轉錄
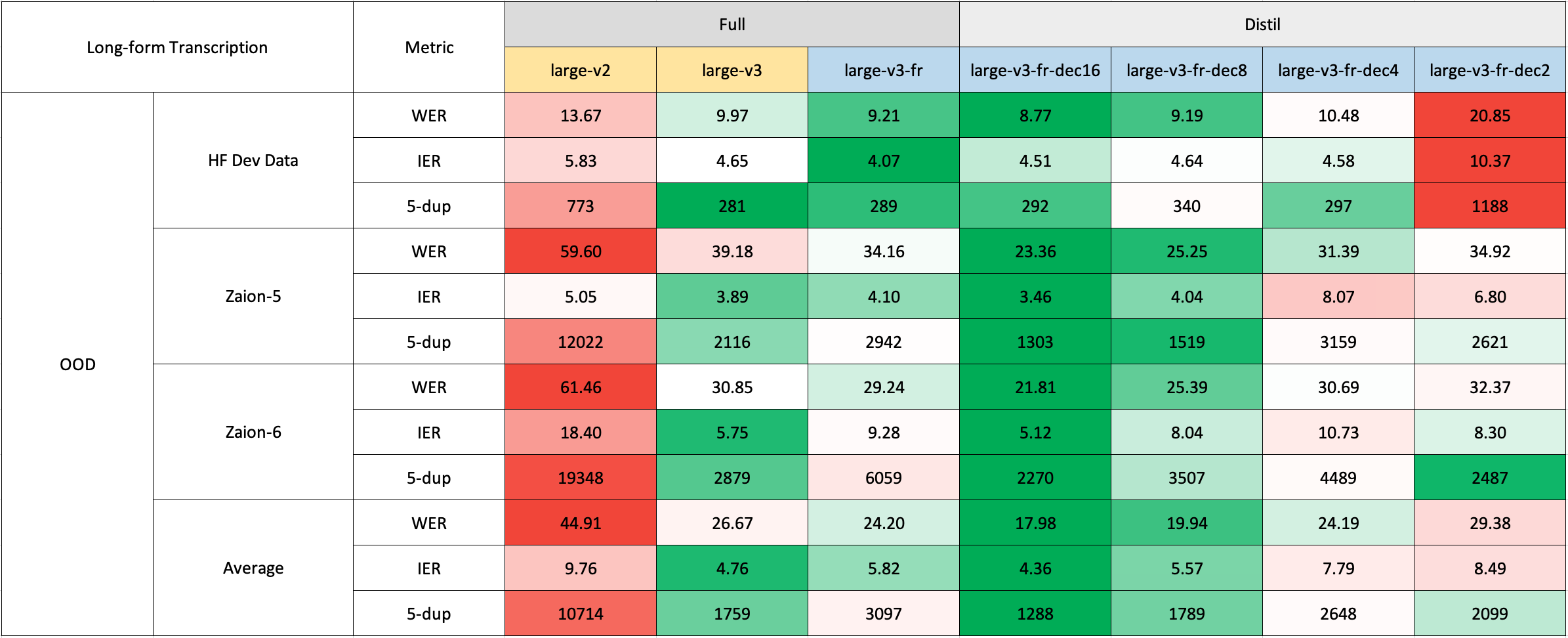
長文本轉錄使用了🤗 Hugging Face管道進行快速評估。音頻文件被分割成30秒的片段並並行處理。
使用方法
Hugging Face Pipeline
該模型可以輕鬆地與🤗 Hugging Face的pipeline類一起用於音頻轉錄。
對於長文本轉錄(超過30秒),可以通過傳遞chunk_length_s參數來激活該過程。這種方法將音頻分割成較小的片段,並行處理,然後通過找到最長公共序列在步幅處連接它們。雖然這種分塊長文本方法與OpenAI的順序算法相比可能會在性能上略有妥協,但它提供了9倍的推理速度。
Hugging Face Low-level APIs
也可以使用🤗 Hugging Face的低級API進行轉錄,這樣可以對過程進行更多控制,示例如下:
推測性解碼
推測性解碼可以使用一個草稿模型來實現,該模型本質上是Whisper的蒸餾版本。這種方法保證了與單獨使用主Whisper模型相同的輸出,提供了2倍的推理速度,並且只增加了少量的內存開銷。
由於蒸餾後的Whisper與原始模型具有相同的編碼器,因此在推理過程中只需要加載其解碼器,並且編碼器輸出在主模型和草稿模型之間共享。
使用Hugging Face管道進行推測性解碼很簡單 - 只需在生成配置中指定assistant_model即可。
OpenAI Whisper
還可以採用OpenAI在其原始論文中概述的帶有滑動窗口和溫度回退的順序長文本解碼算法。
首先,安裝openai-whisper包:
然後,下載轉換後的模型:
現在,可以按照倉庫中提供的使用說明轉錄音頻文件:
Faster Whisper
Faster Whisper是OpenAI的Whisper模型和順序長文本解碼算法在CTranslate2格式下的重新實現。
與openai-whisper相比,它提供了高達4倍的推理速度,同時消耗更少的內存。此外,模型可以量化為int8,進一步提高其在CPU和GPU上的效率。
首先,安裝faster-whisper包:
然後,下載轉換為CTranslate2格式的模型:
現在,可以按照倉庫中提供的使用說明轉錄音頻文件:
Whisper.cpp
Whisper.cpp是OpenAI的Whisper模型的重新實現,用純C/C++編寫,沒有任何依賴。它與各種後端和平臺兼容。
此外,模型可以量化為4位或5位整數,進一步提高其效率。
首先,克隆並構建whisper.cpp倉庫:
接下來,從Hugging Face Hub下載轉換後的ggml權重:
現在,可以使用以下命令轉錄音頻文件:
Candle
Candle-whisper是OpenAI的Whisper模型在candle格式下的重新實現 - 這是一個用Rust構建的輕量級ML框架。
首先,克隆candle倉庫:
使用以下命令轉錄音頻文件:
為了使用CUDA,在示例命令行中添加--features cuda:
MLX
MLX-Whisper是OpenAI的Whisper模型在MLX格式下的重新實現 - 這是一個基於Apple硅的ML框架。它支持諸如惰性計算、統一內存管理等功能。
首先,克隆MLX Examples倉庫:
接下來,安裝依賴項:
下載原始OpenAI格式的pytorch檢查點並將其轉換為MLX格式(由於倉庫已經很大且轉換非常快,我們這裡沒有包含轉換後的版本):
現在,可以使用以下命令轉錄音頻:
訓練細節
我們收集了一個包含超過2500小時法語語音識別數據的複合數據集,其中包括Common Voice 13.0、Multilingual LibriSpeech、Voxpopuli、Fleurs、Multilingual TEDx、MediaSpeech、African Accented French等數據集。
由於一些數據集(如MLS)只提供沒有大小寫和標點的文本,我們使用了🤗 Speechbox的自定義版本,使用bofenghuang/whisper-large-v2-cv11-french模型從有限的符號集中恢復大小寫和標點。
然而,即使在這些數據集中,我們也觀察到了一些質量問題。這些問題包括音頻和轉錄在語言或內容上的不匹配、分割不佳的話語、腳本化語音中缺失單詞等。我們構建了一個管道來過濾掉許多這些有問題的話語,旨在提高數據集的質量。因此,我們排除了超過10%的數據,並且在重新訓練模型時,我們注意到幻覺現象顯著減少。
在訓練方面,我們使用了🤗 Distil-Whisper倉庫中提供的腳本。模型訓練在GENCI的Jean-Zay超級計算機上進行,我們感謝IDRIS團隊在整個項目中提供的及時支持。
致謝
- OpenAI創建並開源了Whisper模型。
- 🤗 Hugging Face集成了Whisper模型,並在Transformers和Distil-Whisper倉庫中提供了訓練代碼庫。
- Genci為該項目慷慨提供了GPU計算時長。
📄 許可證
本項目採用MIT許可證。
信息表格
| 屬性 | 詳情 |
|---|---|
| 模型類型 | 自動語音識別模型 |
| 訓練數據 | 包含Common Voice 13.0、Multilingual LibriSpeech、Voxpopuli、Fleurs、Multilingual TEDx、MediaSpeech、African Accented French等超過2500小時的法語語音識別數據 |