%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Monkeyocr Pro 1.2B
モデル概要
モデル特徴
モデル能力
使用事例
🚀 MonkeyOCR: 構造認識関係のトリプレットパラダイムによるドキュメント解析
MonkeyOCRは、構造認識関係(SRR)のトリプレットパラダイムを採用しています。これにより、モジュール方式のマルチツールパイプラインを簡素化し、大規模なマルチモーダルモデルを用いた全ページドキュメント処理の非効率性を回避します。
MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
![]()
![]()


MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
Zhang Li, Yuliang Liu, Qiang Liu, Zhiyin Ma, Ziyang Zhang, Shuo Zhang, Zidun Guo, Jiarui Zhang, Xinyu Wang, Xiang Bai




🚀 クイックスタート
1. MonkeyOCRのインストール
conda create -n MonkeyOCR python=3.10
conda activate MonkeyOCR
git clone https://github.com/Yuliang-Liu/MonkeyOCR.git
cd MonkeyOCR
# Install pytorch, see https://pytorch.org/get-started/previous-versions/ for your cuda version
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
pip install -e .
2. モデルウェイトのダウンロード
Huggingfaceからモデルをダウンロードします。
pip install huggingface_hub
python tools/download_model.py
ModelScopeからもモデルをダウンロードできます。
pip install modelscope
python tools/download_model.py -t modelscope
3. 推論
# Make sure in MonkeyOCR directory
python parse.py path/to/your.pdf
# or with image as input
pyhton parse.py path/to/your/image
# Specify output path and model configs path
python parse.py path/to/your.pdf -o ./output -c config.yaml
出力結果
MonkeyOCRは3種類の出力ファイルを生成します。
- 処理済みMarkdownファイル (
your.md):最終的に解析されたドキュメント内容がMarkdown形式で保存され、テキスト、数式、テーブルなどの構造化要素が含まれます。 - レイアウト結果 (
your_layout.pdf):元のPDFにレイアウト結果が描画されたものです。 - 中間ブロック結果 (
your_middle.json):検出されたすべてのブロックの詳細情報が含まれるJSONファイルで、以下の情報が含まれます。- ブロックの座標と位置
- ブロックの内容とタイプ情報
- ブロック間の関係情報
これらのファイルは、最終的な整形された出力と詳細な中間結果の両方を提供し、さらなる分析や処理に利用できます。
4. Gradioデモ
# Prepare your env for gradio
pip install gradio==5.23.3
pip install pdf2image==1.17.0
# Start demo
python demo/demo_gradio.py
RTX 3090 / 4090 / ... GPUでの共有メモリエラーの修正 (オプション)
当社の3BモデルはNVIDIA RTX 3090で効率的に動作します。ただし、推論バックエンドとしてLMDeployを使用する場合、RTX 3090 / 4090 GPUで互換性の問題が発生することがあります。特に以下のエラーが発生することがあります。
triton.runtime.errors.OutOfResources: out of resource: shared memory
この問題を回避するために、以下のパッチを適用できます。
python tools/lmdeploy_patcher.py patch
⚠️ 注意: このコマンドは、環境内のLMDeployのソースコードを変更します。 変更を元に戻すには、次のコマンドを実行してください。
python tools/lmdeploy_patcher.py restore
@pinekingに解決策を提供していただき、心より感謝いたします!
推論バックエンドの切り替え (オプション)
以下の手順に従って、推論バックエンドをtransformersに切り替えることができます。
- 必要な依存関係をインストールします(まだインストールされていない場合)。
# install flash attention 2, you can download the corresponding version from https://github.com/Dao-AILab/flash-attention/releases/ pip install flash-attn==2.7.4.post1 --no-build-isolation model_configs.yamlファイルを開きます。chat_config.backendをtransformersに設定します。- GPUのメモリ容量に応じて
batch_sizeを調整し、安定したパフォーマンスを確保します。
設定例:
chat_config:
backend: transformers
batch_size: 10 # Adjust based on your available GPU memory
✨ 主な機能
- MonkeyOCRは、構造認識関係(SRR)のトリプレットパラダイムを採用しています。これにより、モジュール方式のマルチツールパイプラインを簡素化し、大規模なマルチモーダルモデルを用いた全ページドキュメント処理の非効率性を回避します。
- パイプラインベースの手法であるMinerUと比較して、9種類の中国語と英語のドキュメントで平均5.1%の改善が見られ、数式では15.0%、テーブルでは8.6%の改善があります。
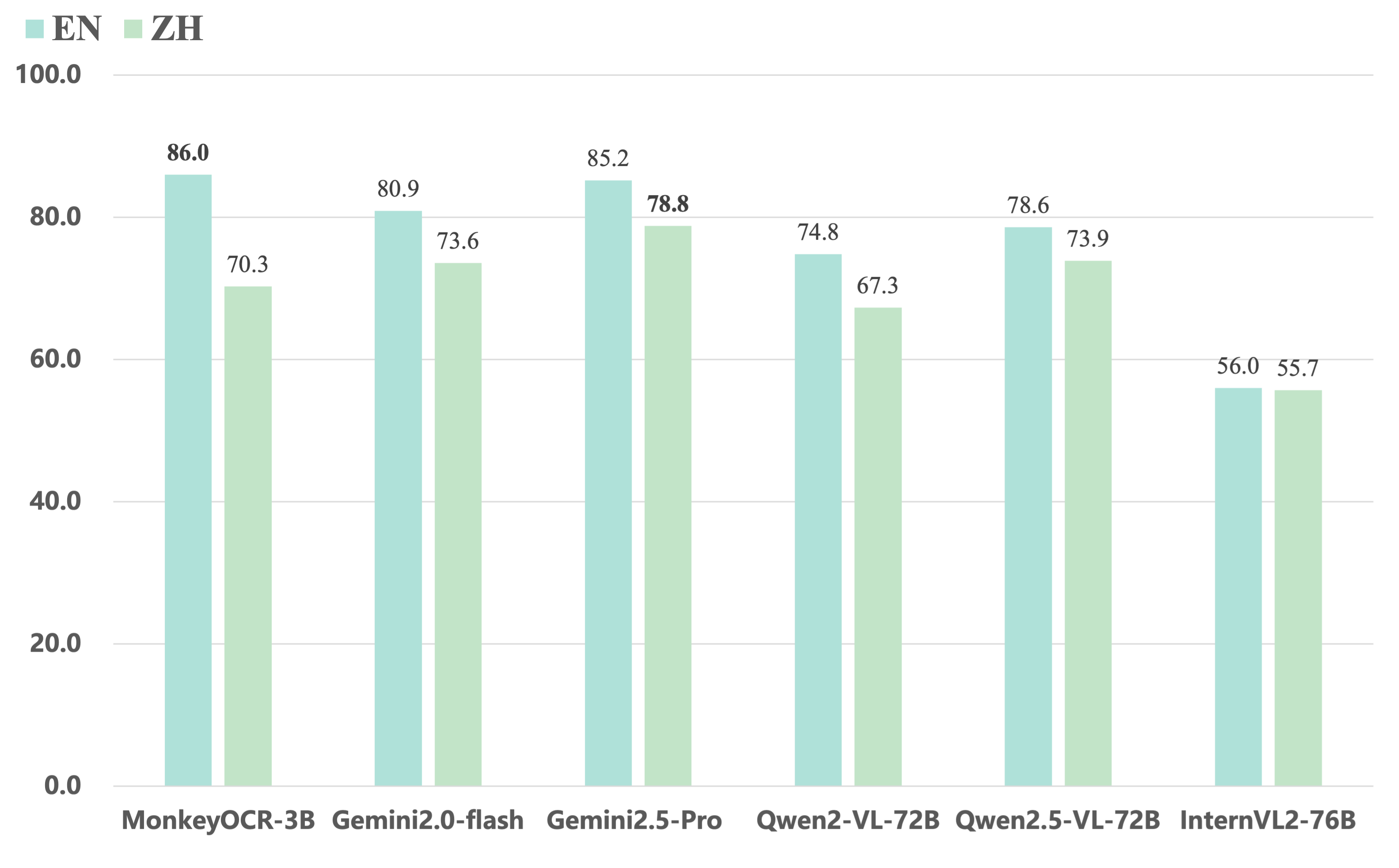
- エンドツーエンドモデルと比較して、30億パラメータのモデルが英語ドキュメントで最高の平均パフォーマンスを達成し、Gemini 2.5 ProやQwen2.5 VL - 72Bなどのモデルを上回ります。
- マルチページドキュメント解析では、毎秒0.84ページの処理速度に達し、MinerU(0.65)やQwen2.5 VL - 7B(0.12)を上回ります。
📚 ドキュメント
導入
MonkeyOCRは、構造認識関係(SRR)のトリプレットパラダイムを採用しています。これにより、モジュール方式のマルチツールパイプラインを簡素化し、大規模なマルチモーダルモデルを用いた全ページドキュメント処理の非効率性を回避します。
- パイプラインベースの手法であるMinerUと比較して、9種類の中国語と英語のドキュメントで平均5.1%の改善が見られ、数式では15.0%、テーブルでは8.6%の改善があります。
- エンドツーエンドモデルと比較して、30億パラメータのモデルが英語ドキュメントで最高の平均パフォーマンスを達成し、Gemini 2.5 ProやQwen2.5 VL - 72Bなどのモデルを上回ります。
- マルチページドキュメント解析では、毎秒0.84ページの処理速度に達し、MinerU(0.65)やQwen2.5 VL - 7B(0.12)を上回ります。
MonkeyOCRは現在、写真ドキュメントをサポートしていませんが、将来的なアップデートで改善を続けていきます。ぜひ期待してください! 現在、当社のモデルは単一のGPUで展開されているため、同時に多くのユーザーがファイルをアップロードすると、「このアプリケーションは現在ビジーです」などの問題が発生する場合があります。当社は、Ollamaや他の展開ソリューションのサポートに積極的に取り組んでおり、より多くのユーザーにスムーズな体験を提供するよう努めています。また、デモページに表示される処理時間は、計算時間だけでなく、結果のアップロードやその他のオーバーヘッドも含まれています。トラフィックが多い時期には、この時間が長くなる場合があります。MonkeyOCR、MinerU、およびQwen2.5 VL - 7Bの推論速度は、H800 GPUで測定されました。
🚀🚀🚀 中国語のビデオチュートリアル ( leo009 の共有に感謝!)
https://youtu.be/T9oaqp-IaZ0
https://www.bilibili.com/video/BV1sxKhztEx1/
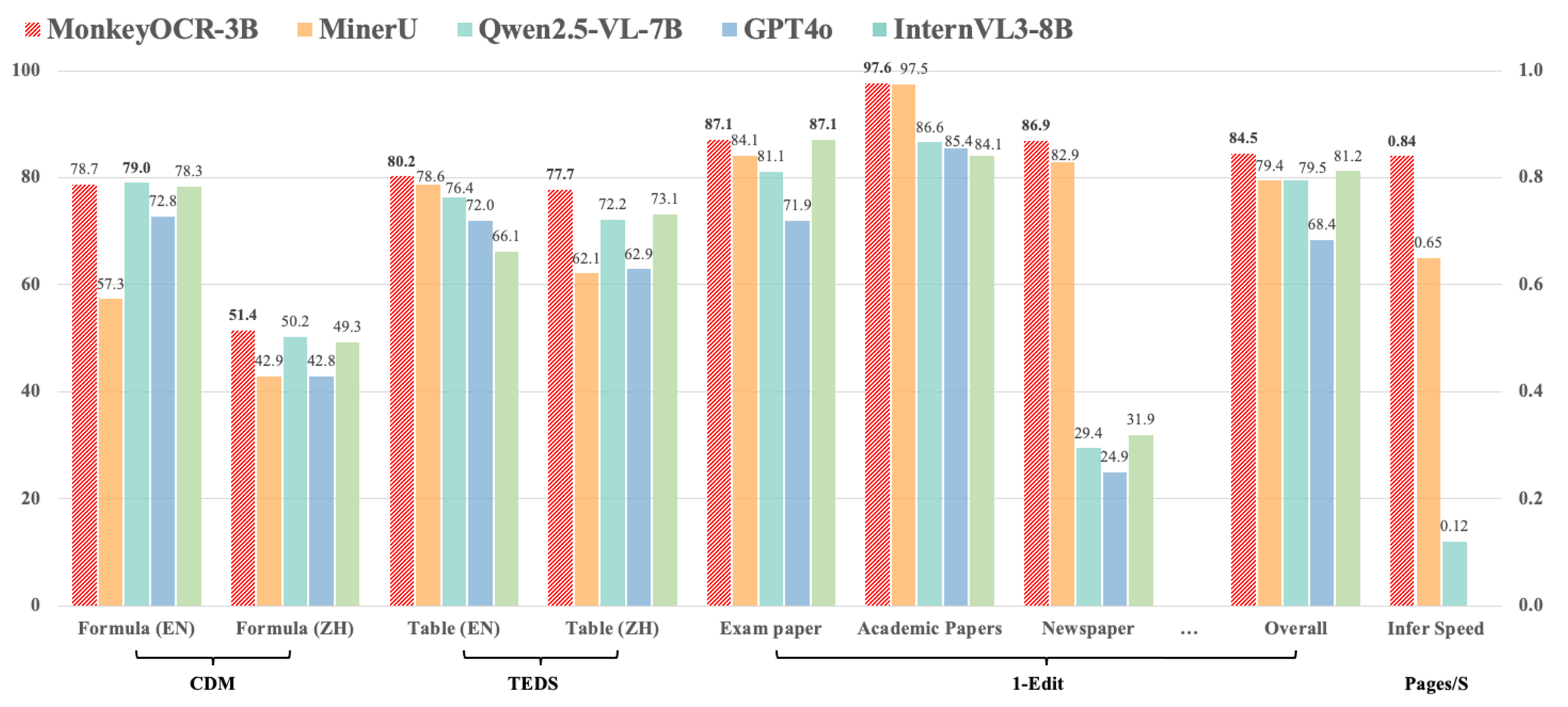
ベンチマーク結果
ここでは、OmniDocBenchでの当社モデルの評価結果を示します。MonkeyOCR - 3BはDocLayoutYOLOを構造検出モデルとして使用していますが、MonkeyOCR - 3B*は中国語のパフォーマンスを向上させた独自の構造検出モデルを使用しています。
1. 異なるタスクのエンドツーエンド評価結果
| モデルタイプ | 手法 | 全体編集距離 (英語)↓ | 全体編集距離 (中国語)↓ | テキスト編集距離 (英語)↓ | テキスト編集距離 (中国語)↓ | 数式編集距離 (英語)↓ | 数式編集距離 (中国語)↓ | 数式CDM (英語)↑ | 数式CDM (中国語)↑ | テーブルTEDS (英語)↑ | テーブルTEDS (中国語)↑ | テーブル編集距離 (英語)↓ | テーブル編集距離 (中国語)↓ | 読み順編集距離 (英語)↓ | 読み順編集距離 (中国語)↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| パイプラインツール | MinerU | 0.150 | 0.357 | 0.061 | 0.215 | 0.278 | 0.577 | 57.3 | 42.9 | 78.6 | 62.1 | 0.180 | 0.344 | 0.079 | 0.292 |
| パイプラインツール | Marker | 0.336 | 0.556 | 0.080 | 0.315 | 0.530 | 0.883 | 17.6 | 11.7 | 67.6 | 49.2 | 0.619 | 0.685 | 0.114 | 0.340 |
| パイプラインツール | Mathpix | 0.191 | 0.365 | 0.105 | 0.384 | 0.306 | 0.454 | 62.7 | 62.1 | 77.0 | 67.1 | 0.243 | 0.320 | 0.108 | 0.304 |
| パイプラインツール | Docling | 0.589 | 0.909 | 0.416 | 0.987 | 0.999 | 1 | - | - | 61.3 | 25.0 | 0.627 | 0.810 | 0.313 | 0.837 |
| パイプラインツール | Pix2Text | 0.320 | 0.528 | 0.138 | 0.356 | 0.276 | 0.611 | 78.4 | 39.6 | 73.6 | 66.2 | 0.584 | 0.645 | 0.281 | 0.499 |
| パイプラインツール | Unstructured | 0.586 | 0.716 | 0.198 | 0.481 | 0.999 | 1 | - | - | 0 | 0.06 | 1 | 0.998 | 0.145 | 0.387 |
| パイプラインツール | OpenParse | 0.646 | 0.814 | 0.681 | 0.974 | 0.996 | 1 | 0.11 | 0 | 64.8 | 27.5 | 0.284 | 0.639 | 0.595 | 0.641 |
| 専用VLM | GOT - OCR | 0.287 | 0.411 | 0.189 | 0.315 | 0.360 | 0.528 | 74.3 | 45.3 | 53.2 | 47.2 | 0.459 | 0.520 | 0.141 | 0.280 |
| 専用VLM | Nougat | 0.452 | 0.973 | 0.365 | 0.998 | 0.488 | 0.941 | 15.1 | 16.8 | 39.9 | 0 | 0.572 | 1.000 | 0.382 | 0.954 |
| 専用VLM | Mistral OCR | 0.268 | 0.439 | 0.072 | 0.325 | 0.318 | 0.495 | 64.6 | 45.9 | 75.8 | 63.6 | 0.600 | 0.650 | 0.083 | 0.284 |
| 専用VLM | OLMOCR - sglang | 0.326 | 0.469 | 0.097 | 0.293 | 0.455 | 0.655 | 74.3 | 43.2 | 68.1 | 61.3 | 0.608 | 0.652 | 0.145 | 0.277 |
| 専用VLM | SmolDocling - 256M | 0.493 | 0.816 | 0.262 | 0.838 | 0.753 | 0.997 | 32.1 | 0.55 | 44.9 | 16.5 | 0.729 | 0.907 | 0.227 | 0.522 |
| 汎用VLM | GPT4o | 0.233 | 0.399 | 0.144 | 0.409 | 0.425 | 0.606 | 72.8 | 42.8 | 72.0 | 62.9 | 0.234 | 0.329 | 0.128 | 0.251 |
| 汎用VLM | Qwen2.5 - VL - 7B | 0.312 | 0.406 | 0.157 | 0.228 | 0.351 | 0.574 | 79.0 | 50.2 | 76.4 | 72.2 | 0.588 | 0.619 | 0.149 | 0.203 |
| 汎用VLM | InternVL3 - 8B | 0.314 | 0.383 | 0.134 | 0.218 | 0.417 | 0.563 | 78.3 | 49.3 | 66.1 | 73.1 | 0.586 | 0.564 | 0.118 | 0.186 |
| 混合 | MonkeyOCR - 3B [Weight] | 0.140 | 0.297 | 0.058 | 0.185 | 0.238 | 0.506 | 78.7 | 51.4 | 80.2 | 77.7 | 0.170 | 0.253 | 0.093 | 0.244 |
| 混合 | MonkeyOCR - 3B* [Weight] | 0.154 | 0.277 | 0.073 | 0.134 | 0.255 | 0.529 | 78.5 | 50.8 | 78.2 | 76.2 | 0.182 | 0.262 | 0.105 | 0.183 |
2. 9種類のPDFページタイプにおけるエンドツーエンドのテキスト認識パフォーマンス
| モデルタイプ | モデル | 書籍 | スライド | 財務報告 | 教科書 | 試験用紙 | 雑誌 | 学術論文 | ノート | 新聞 | 全体 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| パイプラインツール | MinerU | 0.055 | 0.124 | 0.033 | 0.102 | 0.159 | 0.072 | 0.025 | 0.984 | 0.171 | 0.206 |
| パイプラインツール | Marker | 0.074 | 0.340 | 0.089 | 0.319 | 0.452 | 0.153 | 0.059 | 0.651 | 0.192 | 0.274 |
| パイプラインツール | Mathpix | 0.131 | 0.220 | 0.202 | 0.216 | 0.278 | 0.147 | 0.091 | 0.634 | 0.690 | 0.300 |
| 専用VLM | GOT - OCR | 0.111 | 0.222 | 0.067 | 0.132 | 0.204 | 0.198 | 0.179 | 0.388 | 0.771 | 0.267 |
| 専用VLM | Nougat | 0.734 | 0.958 | 1.000 | 0.820 | 0.930 | 0.830 | 0.214 | 0.991 | 0.871 | 0.806 |
| 汎用VLM | GPT4o | 0.157 | 0.163 | 0.348 | 0.187 | 0.281 | 0.173 | 0.146 | 0.607 | 0.751 | 0.316 |
| 汎用VLM | Qwen2.5 - VL - 7B | 0.148 | 0.053 | 0.111 | 0.137 | 0.189 | 0.117 | 0.134 | 0.204 | 0.706 | 0.205 |
| 汎用VLM | InternVL3 - 8B | 0.163 | 0.056 | 0.107 | 0.109 | 0.129 | 0.100 | 0.159 | 0.150 | 0.681 | 0.188 |
| 混合 | MonkeyOCR - 3B [Weight] | 0.046 | 0.120 | 0.024 | 0.100 | 0.129 | 0.086 | 0.024 | 0.643 | 0.131 | 0.155 |
| 混合 | MonkeyOCR - 3B* [Weight] | 0.054 | 0.203 | 0.038 | 0.112 | 0.138 | 0.111 | 0.032 | 0.194 | 0.136 | 0.120 |
3. MonkeyOCRとクローズドソースおよび超大規模オープンソースVLMの比較
可視化デモ
デモを使ってすぐに体験してみましょう: http://vlrlabmonkey.xyz:7685
当社のデモはシンプルで使いやすいです。
- PDFまたは画像をアップロードします。
- 「Parse (解析)」をクリックすると、モデルが入力ドキュメントに対して構造検出、内容認識、関係予測を行います。最終的な出力はMarkdown形式のドキュメントになります。
- プロンプトを選択し、「Test by prompt」をクリックすると、モデルが選択したプロンプトに基づいて画像の内容認識を行います。
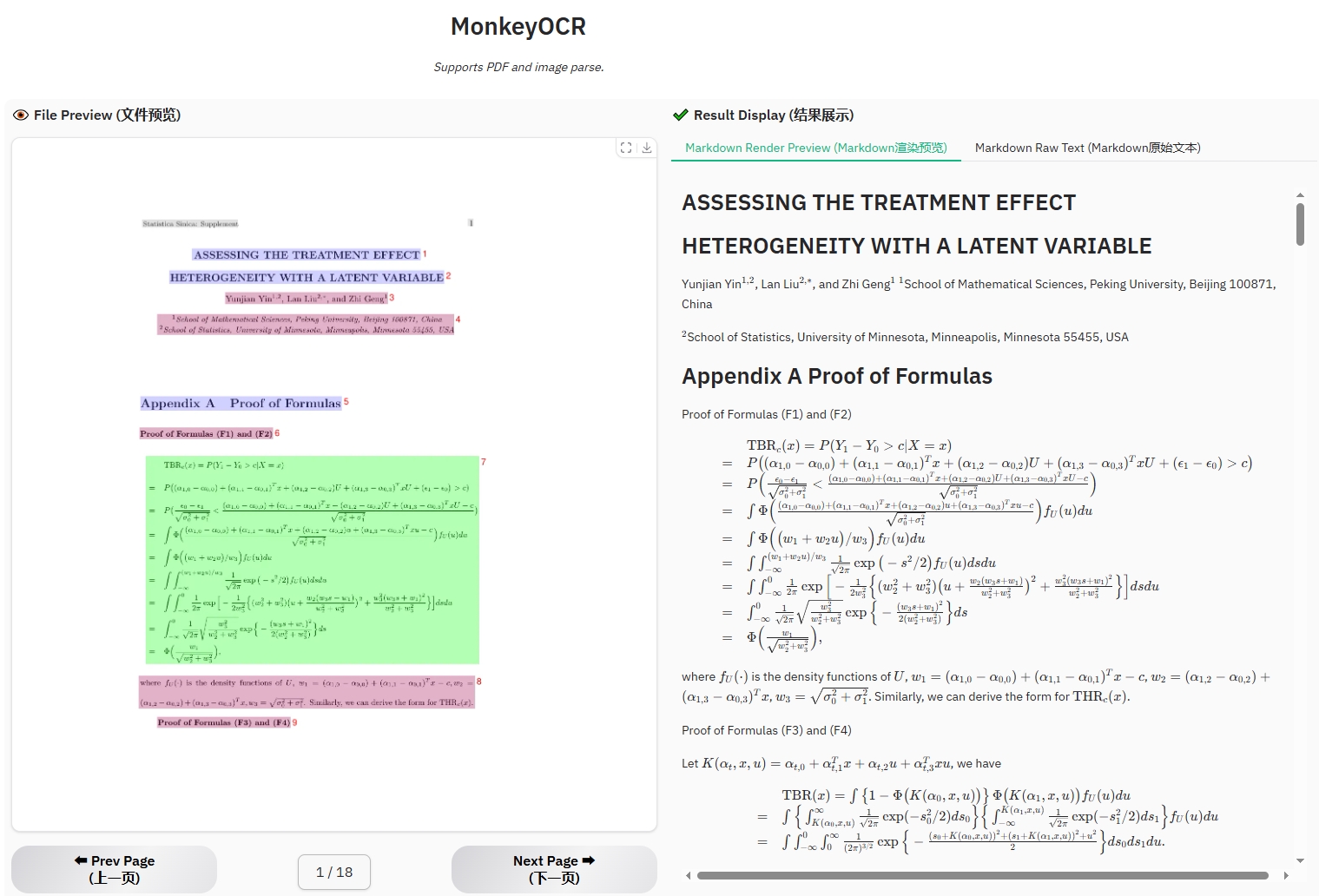
数式ドキュメントの例
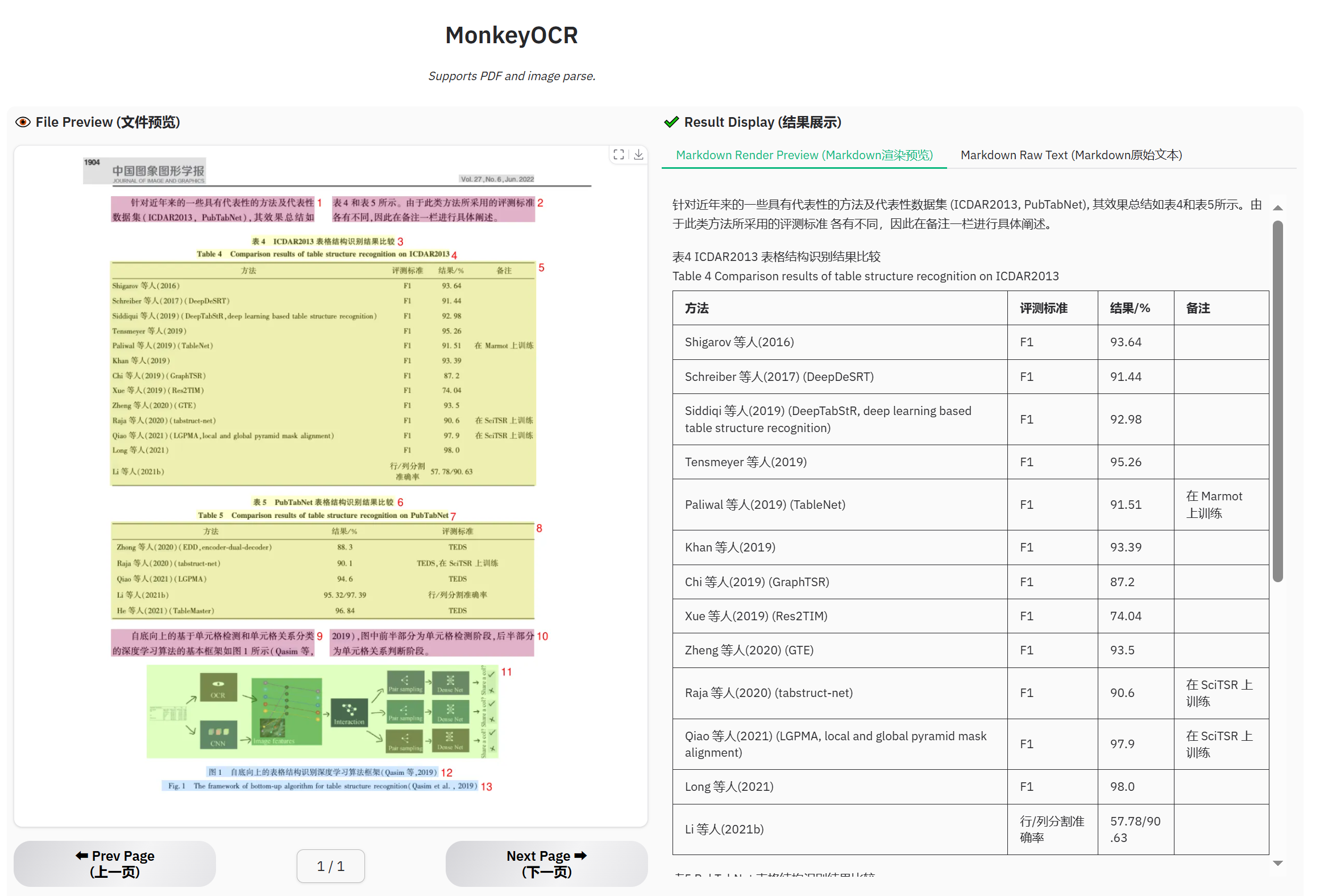
テーブルドキュメントの例
新聞の例

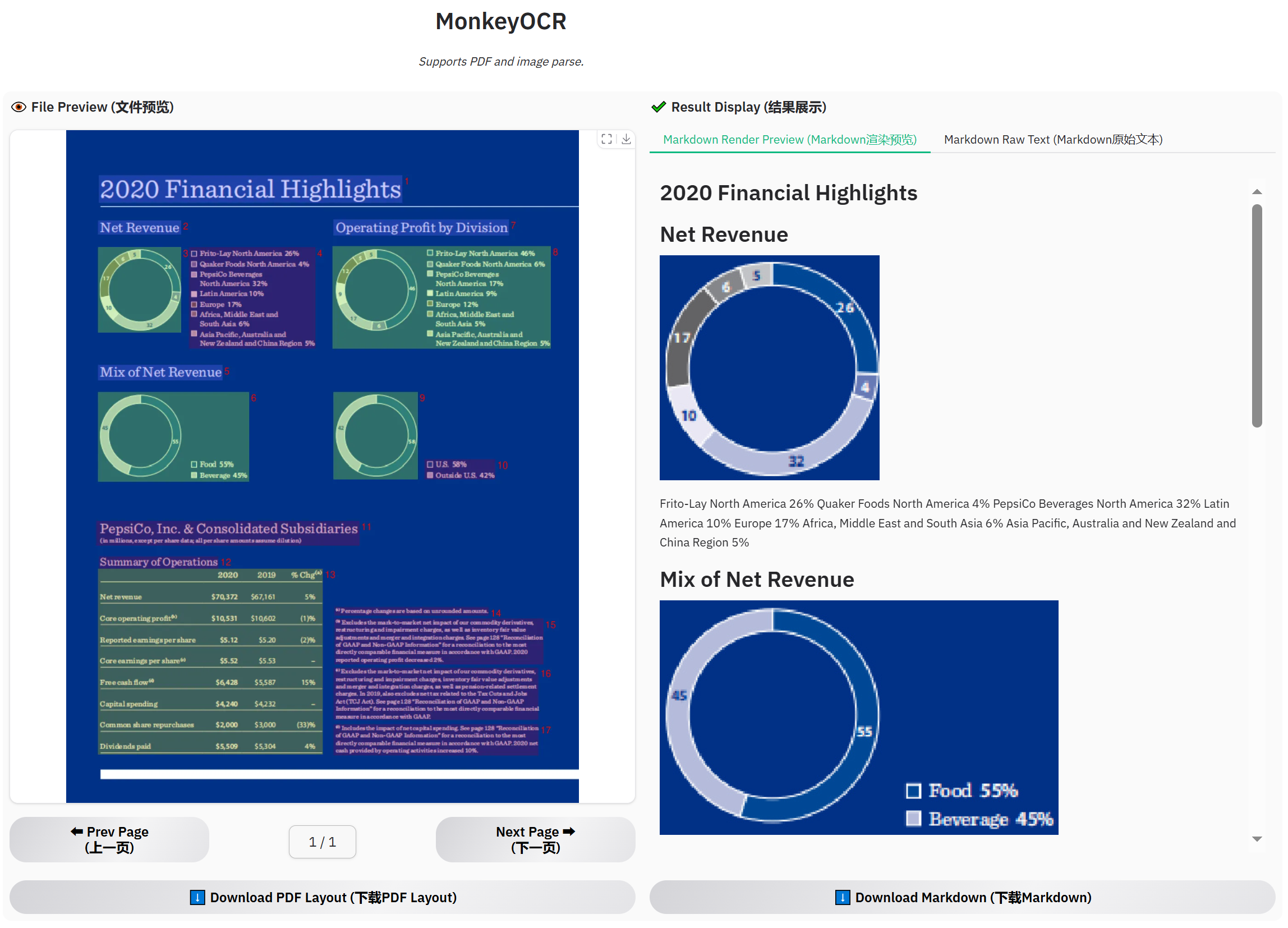
財務報告の例

📄 ライセンス
BibTeX形式での引用方法を以下に示します。
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}
謝辞
[MinerU](https:/ などに感謝いたします。
 Safetensors
Safetensors