%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Monkeyocr Pro 1.2B
模型概述
模型特點
模型能力
使用案例
🚀 MonkeyOCR:基於結構-識別-關係三元組範式的文檔解析
MonkeyOCR是一款創新的文檔解析工具,採用結構-識別-關係(SRR)三元組範式,簡化了模塊化方法的多工具流程,避免了使用大型多模態模型處理全頁文檔的低效問題,在中英文文檔解析任務中表現出色。
🚀 快速開始
1. 安裝MonkeyOCR
conda create -n MonkeyOCR python=3.10
conda activate MonkeyOCR
git clone https://github.com/Yuliang-Liu/MonkeyOCR.git
cd MonkeyOCR
# 安裝pytorch,根據你的cuda版本參考https://pytorch.org/get-started/previous-versions/
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124
pip install -e .
2. 下載模型權重
你可以從Huggingface下載我們的模型:
pip install huggingface_hub
python tools/download_model.py
也可以從ModelScope下載:
pip install modelscope
python tools/download_model.py -t modelscope
3. 推理
# 確保在MonkeyOCR目錄下
python parse.py path/to/your.pdf
# 或者以圖像作為輸入
python parse.py path/to/your/image
# 指定輸出路徑和模型配置文件路徑
python parse.py path/to/your.pdf -o ./output -c config.yaml
輸出結果
MonkeyOCR會生成三種類型的輸出文件:
- 處理後的Markdown文件 (
your.md):最終解析的文檔內容,以Markdown格式呈現,包含文本、公式、表格等結構化元素。 - 佈局結果文件 (
your_layout.pdf):在原始PDF上繪製的佈局結果。 - 中間塊結果文件 (
your_middle.json):一個JSON文件,包含所有檢測到的塊的詳細信息,包括:- 塊的座標和位置
- 塊的內容和類型信息
- 塊之間的關係信息
這些文件既提供了最終格式化的輸出,也提供了詳細的中間結果,便於進一步分析或處理。
4. Gradio演示
# 為Gradio準備環境
pip install gradio==5.23.3
pip install pdf2image==1.17.0
# 啟動演示
python demo/demo_gradio.py
修復RTX 3090 / 4090等GPU上的共享內存錯誤(可選)
我們的3B模型在NVIDIA RTX 3090上運行高效。但是,當使用LMDeploy作為推理後端時,在RTX 3090 / 4090 GPU上可能會遇到兼容性問題,特別是以下錯誤:
triton.runtime.errors.OutOfResources: out of resource: shared memory
要解決此問題,可以應用以下補丁:
python tools/lmdeploy_patcher.py patch
⚠️ 注意:此命令將修改你環境中LMDeploy的源代碼。 要恢復更改,只需運行:
python tools/lmdeploy_patcher.py restore
特別感謝@pineking提供的解決方案!
切換推理後端(可選)
你可以按照以下步驟將推理後端切換為transformers:
- 安裝所需的依賴項(如果尚未安裝):
# 安裝flash attention 2,你可以從https://github.com/Dao-AILab/flash-attention/releases/下載相應版本
pip install flash-attn==2.7.4.post1 --no-build-isolation
- 打開
model_configs.yaml文件 - 將
chat_config.backend設置為transformers - 根據你的GPU內存容量調整
batch_size,以確保性能穩定
示例配置:
chat_config:
backend: transformers
batch_size: 10 # 根據你可用的GPU內存進行調整
✨ 主要特性
- 創新的三元組範式:MonkeyOCR採用結構-識別-關係(SRR)三元組範式,簡化了多工具流程,避免了使用大型多模態模型處理全頁文檔的低效問題。
- 優異的性能表現:
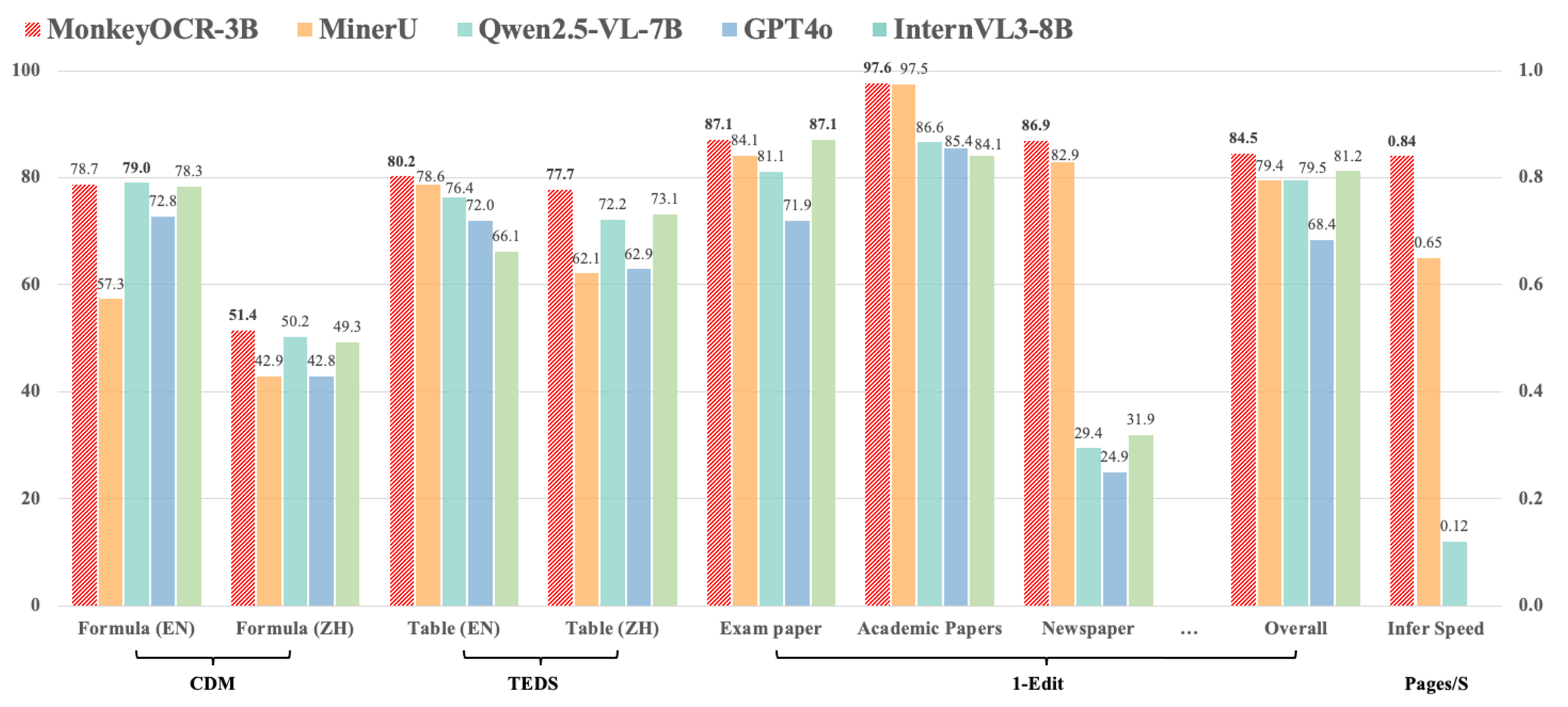
- 與基於管道的方法MinerU相比,在九種中英文文檔類型上平均提高了5.1%,其中公式提高了15.0%,表格提高了8.6%。
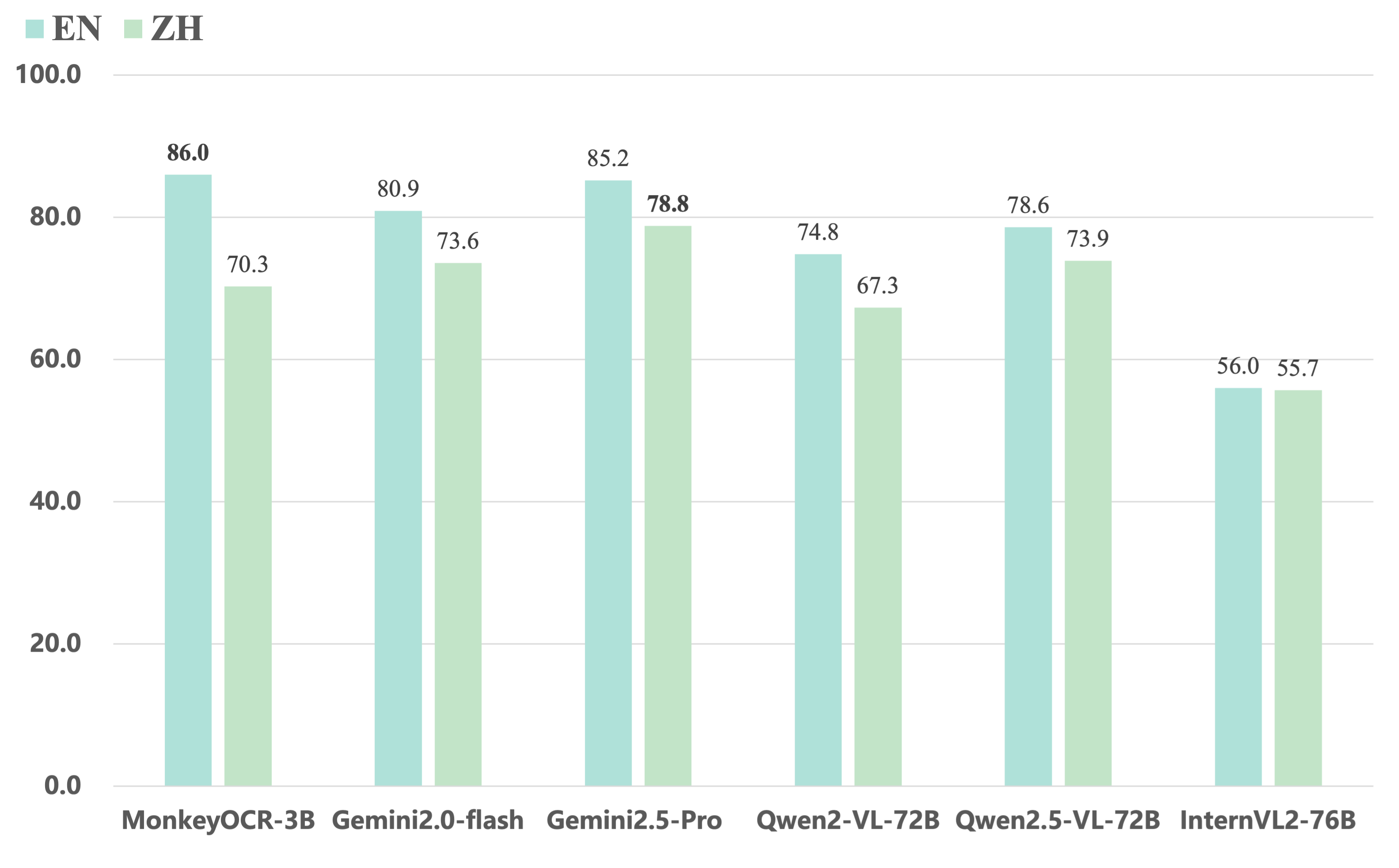
- 與端到端模型相比,我們的3B參數模型在英文文檔上取得了最佳平均性能,優於Gemini 2.5 Pro和Qwen2.5 VL - 72B等模型。
- 高效的多頁處理:對於多頁文檔解析,我們的方法達到了每秒0.84頁的處理速度,超過了MinerU(0.65)和Qwen2.5 VL - 7B(0.12)。
📚 詳細文檔
介紹
MonkeyOCR採用結構-識別-關係(SRR)三元組範式,簡化了模塊化方法的多工具流程,避免了使用大型多模態模型處理全頁文檔的低效問題。
- 與基於管道的方法MinerU相比,我們的方法在九種中英文文檔類型上平均提高了5.1%,其中公式提高了15.0%,表格提高了8.6%。
- 與端到端模型相比,我們的3B參數模型在英文文檔上取得了最佳平均性能,優於Gemini 2.5 Pro和Qwen2.5 VL - 72B等模型。
- 對於多頁文檔解析,我們的方法達到了每秒0.84頁的處理速度,超過了MinerU(0.65)和Qwen2.5 VL - 7B(0.12)。
MonkeyOCR目前不支持拍攝的文檔,但我們將在未來的更新中繼續改進。請保持關注! 目前,我們的模型部署在單個GPU上,因此如果太多用戶同時上傳文件,可能會出現“此應用程序當前繁忙”等問題。我們正在積極支持Ollama和其他部署解決方案,以確保更多用戶獲得更流暢的體驗。此外,請注意,演示頁面上顯示的處理時間不僅反映了計算時間,還包括結果上傳和其他開銷。在高流量期間,此時間可能會更長。MonkeyOCR、MinerU和Qwen2.5 VL - 7B的推理速度是在H800 GPU上測量的。
🚀🚀🚀 中文視頻教程(感謝leo009分享!)
🔧 技術細節
基準測試結果
以下是我們的模型在OmniDocBench上的評估結果。MonkeyOCR - 3B使用DocLayoutYOLO作為結構檢測模型,而MonkeyOCR - 3B*使用我們訓練的結構檢測模型,在中文性能上有所提升。
1. 不同任務的端到端評估結果
| 模型類型 | 方法 | 總體編輯距離(英文)↓ | 總體編輯距離(中文)↓ | 文本編輯距離(英文)↓ | 文本編輯距離(中文)↓ | 公式編輯距離(英文)↓ | 公式編輯距離(中文)↓ | 公式CDM(英文)↑ | 公式CDM(中文)↑ | 表格TEDS(英文)↑ | 表格TEDS(中文)↑ | 表格編輯距離(英文)↓ | 表格編輯距離(中文)↓ | 閱讀順序編輯距離(英文)↓ | 閱讀順序編輯距離(中文)↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 管道工具 | MinerU | 0.150 | 0.357 | 0.061 | 0.215 | 0.278 | 0.577 | 57.3 | 42.9 | 78.6 | 62.1 | 0.180 | 0.344 | 0.079 | 0.292 |
| 管道工具 | Marker | 0.336 | 0.556 | 0.080 | 0.315 | 0.530 | 0.883 | 17.6 | 11.7 | 67.6 | 49.2 | 0.619 | 0.685 | 0.114 | 0.340 |
| 管道工具 | Mathpix | 0.191 | 0.365 | 0.105 | 0.384 | 0.306 | 0.454 | 62.7 | 62.1 | 77.0 | 67.1 | 0.243 | 0.320 | 0.108 | 0.304 |
| 管道工具 | Docling | 0.589 | 0.909 | 0.416 | 0.987 | 0.999 | 1 | - | - | 61.3 | 25.0 | 0.627 | 0.810 | 0.313 | 0.837 |
| 管道工具 | Pix2Text | 0.320 | 0.528 | 0.138 | 0.356 | 0.276 | 0.611 | 78.4 | 39.6 | 73.6 | 66.2 | 0.584 | 0.645 | 0.281 | 0.499 |
| 管道工具 | Unstructured | 0.586 | 0.716 | 0.198 | 0.481 | 0.999 | 1 | - | - | 0 | 0.06 | 1 | 0.998 | 0.145 | 0.387 |
| 管道工具 | OpenParse | 0.646 | 0.814 | 0.681 | 0.974 | 0.996 | 1 | 0.11 | 0 | 64.8 | 27.5 | 0.284 | 0.639 | 0.595 | 0.641 |
| 專家VLM模型 | GOT - OCR | 0.287 | 0.411 | 0.189 | 0.315 | 0.360 | 0.528 | 74.3 | 45.3 | 53.2 | 47.2 | 0.459 | 0.520 | 0.141 | 0.280 |
| 專家VLM模型 | Nougat | 0.452 | 0.973 | 0.365 | 0.998 | 0.488 | 0.941 | 15.1 | 16.8 | 39.9 | 0 | 0.572 | 1.000 | 0.382 | 0.954 |
| 專家VLM模型 | Mistral OCR | 0.268 | 0.439 | 0.072 | 0.325 | 0.318 | 0.495 | 64.6 | 45.9 | 75.8 | 63.6 | 0.600 | 0.650 | 0.083 | 0.284 |
| 專家VLM模型 | OLMOCR - sglang | 0.326 | 0.469 | 0.097 | 0.293 | 0.455 | 0.655 | 74.3 | 43.2 | 68.1 | 61.3 | 0.608 | 0.652 | 0.145 | 0.277 |
| 專家VLM模型 | SmolDocling - 256M | 0.493 | 0.816 | 0.262 | 0.838 | 0.753 | 0.997 | 32.1 | 0.55 | 44.9 | 16.5 | 0.729 | 0.907 | 0.227 | 0.522 |
| 通用VLM模型 | GPT4o | 0.233 | 0.399 | 0.144 | 0.409 | 0.425 | 0.606 | 72.8 | 42.8 | 72.0 | 62.9 | 0.234 | 0.329 | 0.128 | 0.251 |
| 通用VLM模型 | Qwen2.5 - VL - 7B | 0.312 | 0.406 | 0.157 | 0.228 | 0.351 | 0.574 | 79.0 | 50.2 | 76.4 | 72.2 | 0.588 | 0.619 | 0.149 | 0.203 |
| 通用VLM模型 | InternVL3 - 8B | 0.314 | 0.383 | 0.134 | 0.218 | 0.417 | 0.563 | 78.3 | 49.3 | 66.1 | 73.1 | 0.586 | 0.564 | 0.118 | 0.186 |
| 混合模型 | MonkeyOCR - 3B 權重 | 0.140 | 0.297 | 0.058 | 0.185 | 0.238 | 0.506 | 78.7 | 51.4 | 80.2 | 77.7 | 0.170 | 0.253 | 0.093 | 0.244 |
| 混合模型 | MonkeyOCR - 3B* 權重 | 0.154 | 0.277 | 0.073 | 0.134 | 0.255 | 0.529 | 78.5 | 50.8 | 78.2 | 76.2 | 0.182 | 0.262 | 0.105 | 0.183 |
2. 9種PDF頁面類型的端到端文本識別性能
| 模型類型 | 模型 | 書籍 | 幻燈片 | 財務報告 | 教科書 | 試卷 | 雜誌 | 學術論文 | 筆記 | 報紙 | 總體 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 管道工具 | MinerU | 0.055 | 0.124 | 0.033 | 0.102 | 0.159 | 0.072 | 0.025 | 0.984 | 0.171 | 0.206 |
| 管道工具 | Marker | 0.074 | 0.340 | 0.089 | 0.319 | 0.452 | 0.153 | 0.059 | 0.651 | 0.192 | 0.274 |
| 管道工具 | Mathpix | 0.131 | 0.220 | 0.202 | 0.216 | 0.278 | 0.147 | 0.091 | 0.634 | 0.690 | 0.300 |
| 專家VLM模型 | GOT - OCR | 0.111 | 0.222 | 0.067 | 0.132 | 0.204 | 0.198 | 0.179 | 0.388 | 0.771 | 0.267 |
| 專家VLM模型 | Nougat | 0.734 | 0.958 | 1.000 | 0.820 | 0.930 | 0.830 | 0.214 | 0.991 | 0.871 | 0.806 |
| 通用VLM模型 | GPT4o | 0.157 | 0.163 | 0.348 | 0.187 | 0.281 | 0.173 | 0.146 | 0.607 | 0.751 | 0.316 |
| 通用VLM模型 | Qwen2.5 - VL - 7B | 0.148 | 0.053 | 0.111 | 0.137 | 0.189 | 0.117 | 0.134 | 0.204 | 0.706 | 0.205 |
| 通用VLM模型 | InternVL3 - 8B | 0.163 | 0.056 | 0.107 | 0.109 | 0.129 | 0.100 | 0.159 | 0.150 | 0.681 | 0.188 |
| 混合模型 | MonkeyOCR - 3B 權重 | 0.046 | 0.120 | 0.024 | 0.100 | 0.129 | 0.086 | 0.024 | 0.643 | 0.131 | 0.155 |
| 混合模型 | MonkeyOCR - 3B* 權重 | 0.054 | 0.203 | 0.038 | 0.112 | 0.138 | 0.111 | 0.032 | 0.194 | 0.136 | 0.120 |
3. MonkeyOCR與閉源和超大型開源VLM模型的比較
📄 許可證
文檔中未提及相關內容,故跳過該章節。
💻 使用示例
可視化演示
立即體驗我們的演示:點擊進入
我們的演示簡單易用:
- 上傳一個PDF或圖像。
- 點擊“解析 (解析)”,讓模型對輸入文檔進行結構檢測、內容識別和關係預測。最終輸出將是一個Markdown格式的文檔。
- 選擇一個提示並點擊“按提示測試”,讓模型根據所選提示對圖像進行內容識別。
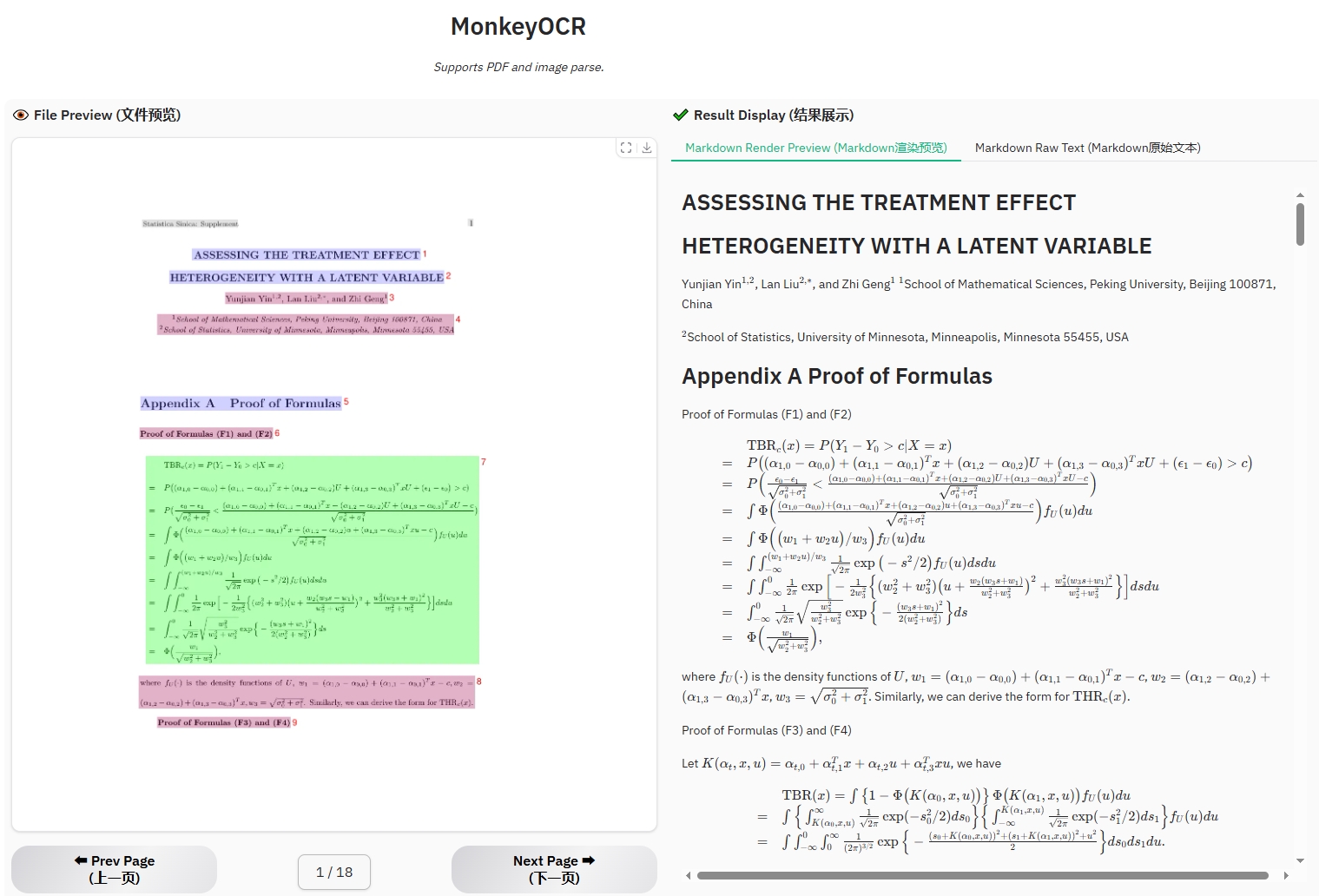
公式文檔示例
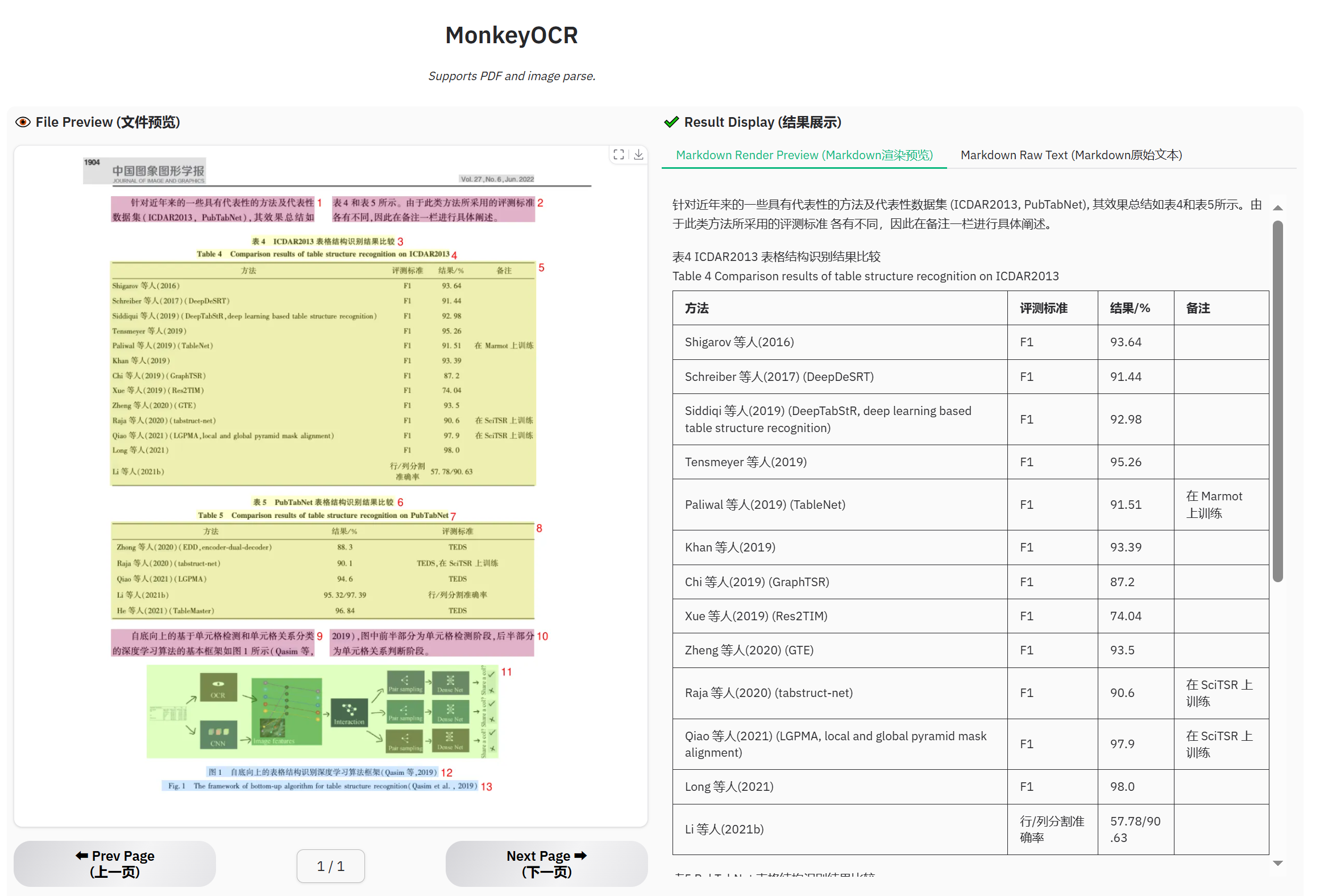
表格文檔示例
報紙示例

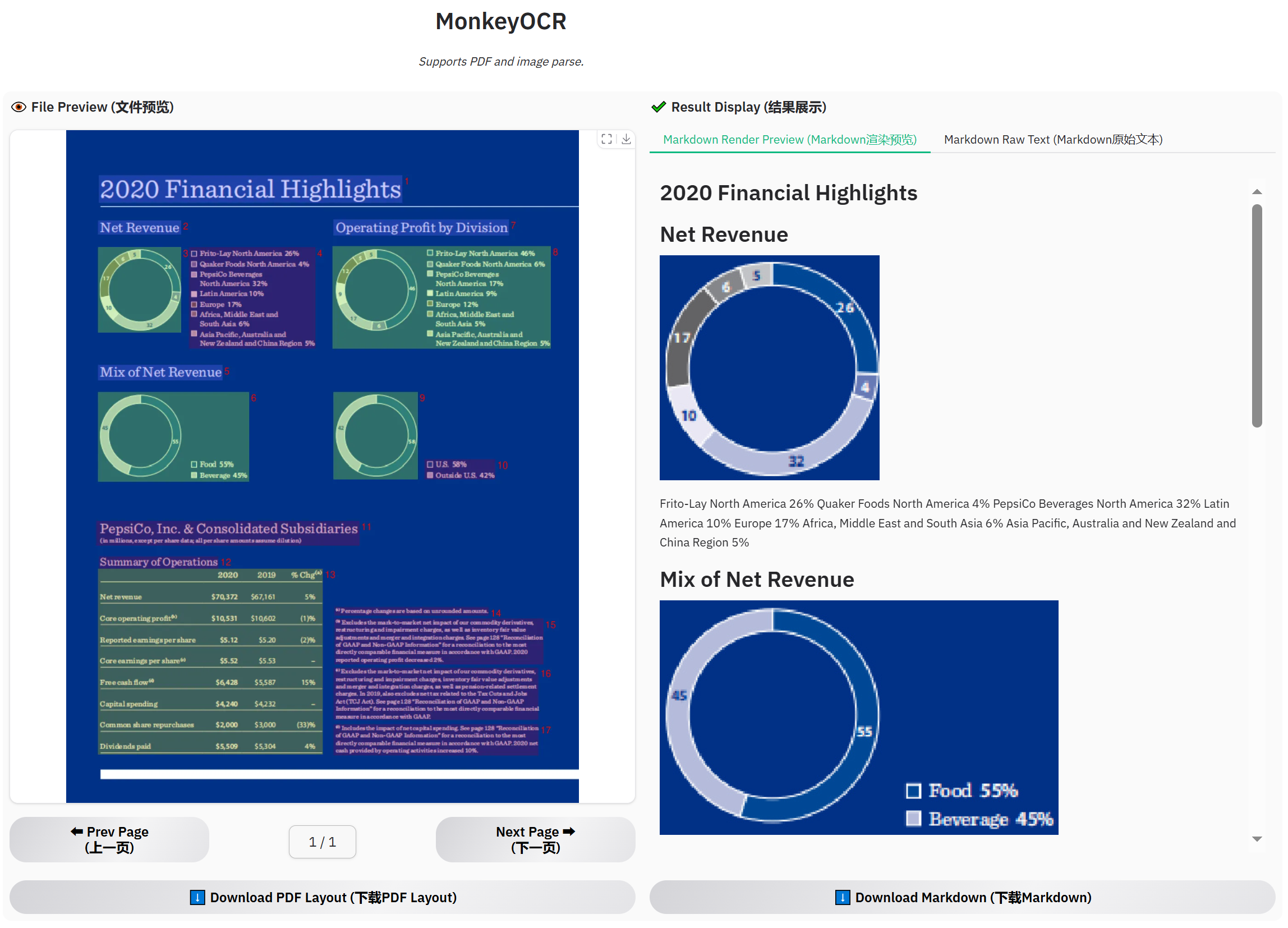
財務報告示例

📚 引用
如果你想引用此處發佈的基線結果,請使用以下BibTeX條目:
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}
 Safetensors
Safetensors