%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
JA
Gemma 2 2B TR Knowledge Graph
Gemma-2-2B-TR-Knowledge-Graphはgemma-2-2b-itをベースに微調整されたモデルで、文書内容から構造化知識グラフを生成することに特化しています。
ダウンロード数 122
リリース時間 : 1/16/2025
モデル概要
このモデルは文書内容から自動的に構造化知識グラフを生成でき、グラフデータベースの構築とデータ充填に利用でき、データ関係の効率的な保存、クエリ、可視化を実現します。
モデル特徴
高品質知識グラフ生成
高品質の知識グラフ生成サンプルで訓練されており、文書内容から自動的に構造化知識グラフを生成できます。
グラフデータベースサポート
生成された知識グラフはグラフデータベースの構築とデータ充填に利用でき、データ関係の効率的な保存、クエリ、可視化をサポートします。
効率的な微調整
gemma-2-2b-itモデルをベースに微調整されており、訓練時間が短く、効果が顕著です。
モデル能力
テキスト生成
知識グラフ抽出
構造化データ生成
使用事例
知識管理
学術文献分析
学術文献からキー概念と関係を抽出し、知識グラフを構築します。
生成された構造化知識グラフは学術研究や文献レビューに利用できます。
企業知識ベース構築
企業文書からエンティティと関係を抽出し、企業知識ベースを構築します。
企業知識の効率的な保存とクエリをサポートします。
データ可視化
知識グラフ可視化
生成されたグラフデータを可視化し、複雑な関係ネットワークを表示します。
直感的なデータ関係の表示を提供し、理解と分析を容易にします。
🚀 Gemma-2-2B-TR-Knowledge-Graph
Gemma-2-2B-TR-Knowledge-Graphはgemma-2-2b-itの微調整バージョンです。高品質な知識グラフ生成サンプルで訓練されており、文書内容から自動的に構造化された知識グラフを生成することができます。これはグラフデータベースの構築とデータの充填に利用でき、データ関係の効率的な保存、クエリ、可視化を実現します。

🚀 クイックスタート
インストール
まず、vLLMをインストールする必要があります。
pip install vllm
使用例
ユーザーのプロンプトの末尾に \n<knowledge_graph> を追加して、知識グラフの抽出をトリガーします。
from vllm import LLM, SamplingParams
import json
llm = LLM(model="Metin/Gemma-2-2B-TR-Knowledge-Graph")
sampling_params = SamplingParams(temperature=0.1, max_tokens=4096)
content = """Guido van Rossum (d. 31 Ocak 1956), Hollandalı bir bilgisayar programcısıdır.
Python programlama dilinin yazarıdır. Van Rossum 12 Temmuz 2018'de Python yönetiminden istifa ettiğini ve emekliliğe ayrıldığını duyurdu.[1] 12 Kasım 2020 tarihinde emekliliğinden geri dönerek Microsoft'a katıldığını açıklamıştır.[2]"""
conversation = [
{
"role": "user",
"content": content + "\n<knowledge_graph>"
}
]
outputs = llm.chat(
conversation,
sampling_params=sampling_params,
use_tqdm=False
)
result = json.loads(outputs[0].outputs[0].text)
print(result)
✨ 主な機能
- gemma-2-2b-itモデルをベースに微調整されており、文書内容から自動的に構造化された知識グラフを生成できます。
- 生成された知識グラフはグラフデータベースの構築と充填に利用でき、データ関係の効率的な保存、クエリ、可視化をサポートします。
📦 インストール
vLLMをインストールします。
pip install vllm
💻 使用例
基本的な使用法
以下は、このモデルを使用して知識グラフを生成する例です。
from vllm import LLM, SamplingParams
import json
llm = LLM(model="Metin/Gemma-2-2B-TR-Knowledge-Graph")
sampling_params = SamplingParams(temperature=0.1, max_tokens=4096)
content = """Derin öğrenme (aynı zamanda derin yapılandırılmış öğrenme, hiyerarşik öğrenme ya da derin makine öğrenmesi) bir veya daha fazla gizli katman içeren yapay sinir ağları ve benzeri makine öğrenme algoritmalarını kapsayan çalışma alanıdır.
Yani en az bir adet yapay sinir ağının (YSA) kullanıldığı ve birçok algoritma ile, bilgisayarın eldeki verilerden yeni veriler elde etmesidir.
Derin öğrenme gözetimli, yarı gözetimli veya gözetimsiz olarak gerçekleştirilebilir.[1] Derin yapay sinir ağları pekiştirmeli öğrenme yaklaşımıyla da başarılı sonuçlar vermiştir.[2] Yapay sinir ağları, biyolojik sistemlerdeki bilgi işleme ve dağıtılmış iletişim düğümlerinden esinlenilmiştir. Yapay sinir ağlarının biyolojik beyinlerden çeşitli farklılıkları vardır. Özellikle, sinir ağları statik ve sembolik olma eğilimindeyken, çoğu canlı organizmanın biyolojik beyni dinamik(plastik) ve analogtur.[3][4][5]"""
conversation = [
{
"role": "user",
"content": content + "\n<knowledge_graph>"
}
]
outputs = llm.chat(
conversation,
sampling_params=sampling_params,
use_tqdm=False
)
result = json.loads(outputs[0].outputs[0].text)
print(result)
出力例
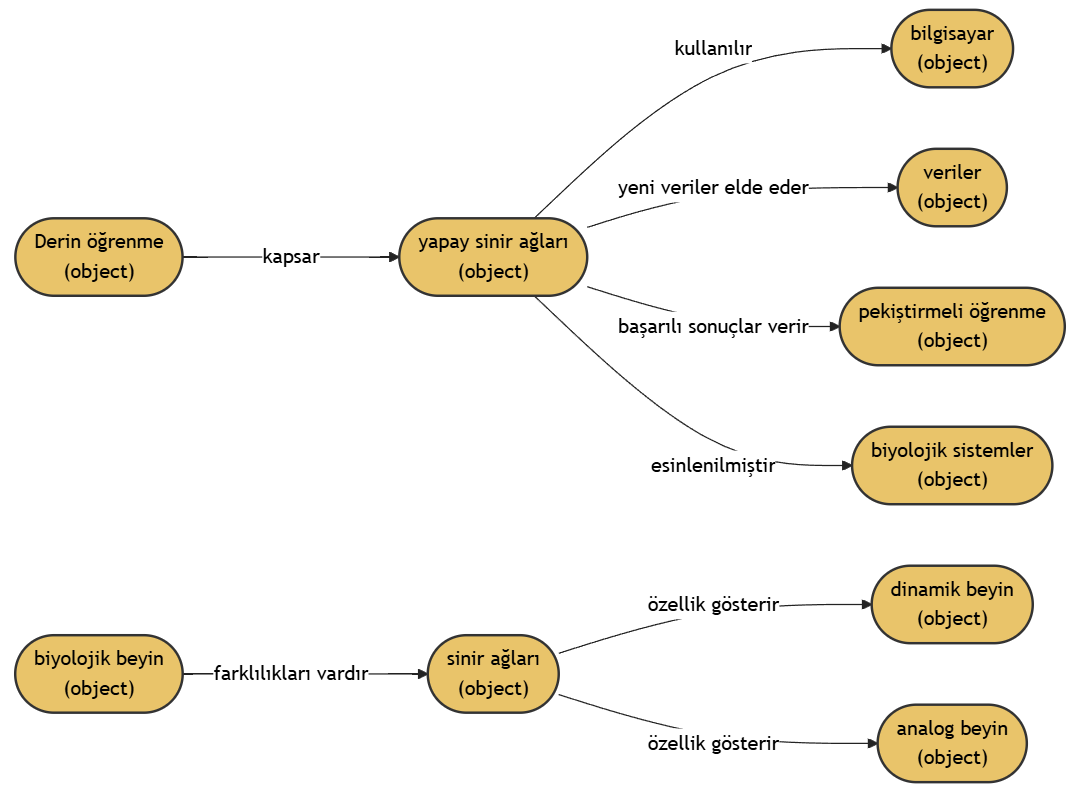
例1
文書内容:
Derin öğrenme (aynı zamanda derin yapılandırılmış öğrenme, hiyerarşik öğrenme ya da derin makine öğrenmesi) bir veya daha fazla gizli katman içeren yapay sinir ağları ve benzeri makine öğrenme algoritmalarını kapsayan çalışma alanıdır.
Yani en az bir adet yapay sinir ağının (YSA) kullanıldığı ve birçok algoritma ile, bilgisayarın eldeki verilerden yeni veriler elde etmesidir.
Derin öğrenme gözetimli, yarı gözetimli veya gözetimsiz olarak gerçekleştirilebilir.[1] Derin yapay sinir ağları pekiştirmeli öğrenme yaklaşımıyla da başarılı sonuçlar vermiştir.[2] Yapay sinir ağları, biyolojik sistemlerdeki bilgi işleme ve dağıtılmış iletişim düğümlerinden esinlenilmiştir. Yapay sinir ağlarının biyolojik beyinlerden çeşitli farklılıkları vardır. Özellikle, sinir ağları statik ve sembolik olma eğilimindeyken, çoğu canlı organizmanın biyolojik beyni dinamik(plastik) ve analogtur.[3][4][5]
出力結果:
{
"nodes": [
{
"type": "object",
"name": "Derin öğrenme"
},
{
"type": "object",
"name": "yapay sinir ağları"
},
{
"type": "object",
"name": "bilgisayar"
},
{
"type": "object",
"name": "veriler"
},
{
"type": "object",
"name": "pekiştirmeli öğrenme"
},
{
"type": "object",
"name": "biyolojik sistemler"
},
{
"type": "object",
"name": "biyolojik beyin"
},
{
"type": "object",
"name": "sinir ağları"
},
{
"type": "object",
"name": "dinamik beyin"
},
{
"type": "object",
"name": "analog beyin"
}
],
"relationships": [
{
"source": "Derin öğrenme",
"target": "yapay sinir ağları",
"relationship": "kapsar"
},
{
"source": "yapay sinir ağları",
"target": "bilgisayar",
"relationship": "kullanılır"
},
{
"source": "yapay sinir ağları",
"target": "veriler",
"relationship": "yeni veriler elde eder"
},
{
"source": "yapay sinir ağları",
"target": "pekiştirmeli öğrenme",
"relationship": "başarılı sonuçlar verir"
},
{
"source": "yapay sinir ağları",
"target": "biyolojik sistemler",
"relationship": "esinlenilmiştir"
},
{
"source": "biyolojik beyin",
"target": "sinir ağları",
"relationship": "farklılıkları vardır"
},
{
"source": "sinir ağları",
"target": "dinamik beyin",
"relationship": "özellik gösterir"
},
{
"source": "sinir ağları",
"target": "analog beyin",
"relationship": "özellik gösterir"
}
]
}
知識グラフの可視化:
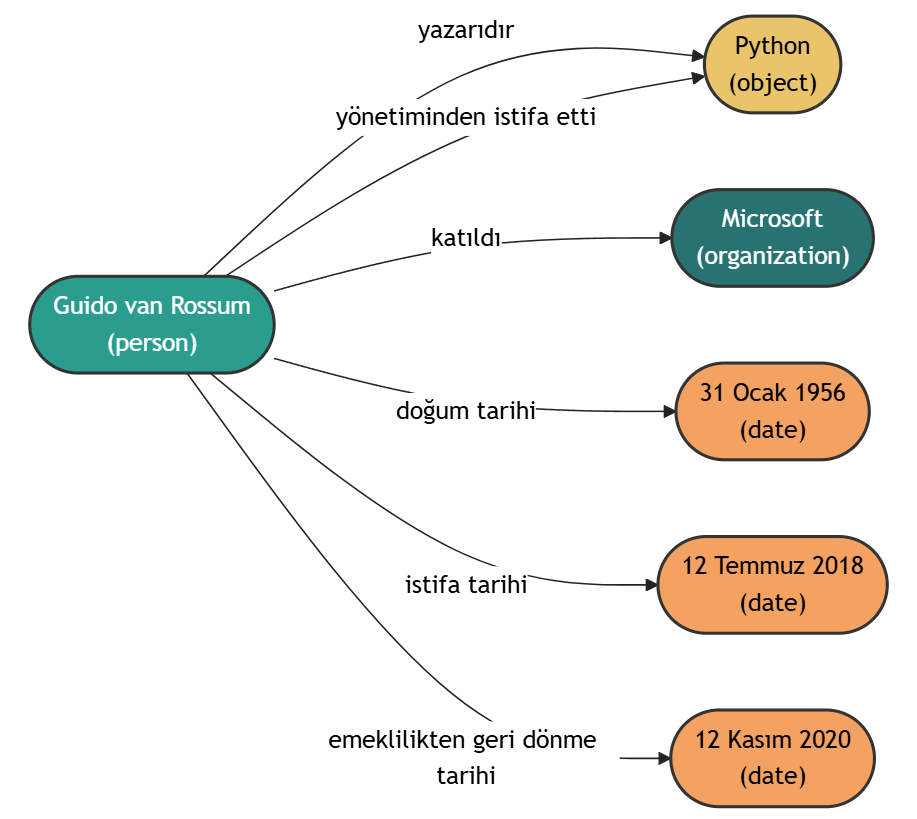
例2
文書内容:
Guido van Rossum (d. 31 Ocak 1956), Hollandalı bir bilgisayar programcısıdır.
Python programlama dilinin yazarıdır. Van Rossum 12 Temmuz 2018'de Python yönetiminden istifa ettiğini ve emekliye ayrıldığını duyurdu.[1] 12 Kasım 2020 tarihinde emeklilikten geri dönerek Microsoft'a katıldığını açıklamıştır.[2]
出力結果:
{
"nodes": [
{
"type": "person",
"name": "Guido van Rossum"
},
{
"type": "object",
"name": "Python"
},
{
"type": "organization",
"name": "Microsoft"
},
{
"type": "date",
"name": "31 Ocak 1956"
},
{
"type": "date",
"name": "12 Temmuz 2018"
},
{
"type": "date",
"name": "12 Kasım 2020"
}
],
"relationships": [
{
"source": "Guido van Rossum",
"target": "Python",
"relationship": "yazarıdır"
},
{
"source": "Guido van Rossum",
"target": "Python",
"relationship": "yönetiminden istifa etti"
},
{
"source": "Guido van Rossum",
"target": "Microsoft",
"relationship": "katıldı"
},
{
"source": "Guido van Rossum",
"target": "31 Ocak 1956",
"relationship": "doğum tarihi"
},
{
"source": "Guido van Rossum",
"target": "12 Temmuz 2018",
"relationship": "istifa tarihi"
},
{
"source": "Guido van Rossum",
"target": "12 Kasım 2020",
"relationship": "emeklilikten geri dönme tarihi"
}
]
}
知識グラフの可視化:
🔧 技術詳細
モデル情報
| 属性 | 詳細 |
|---|---|
| モデルタイプ | Gemma-2-2B-TR-Knowledge-Graph |
| ベースモデル | gemma-2-2b-it |
| 訓練データ | 30Kのサンプルから構成される合成生成知識グラフデータセットを使用し、専有データは含まれていません。 |
| 訓練時間 | 単一のRTX 6000 ADAで3時間訓練しました。 |
| LoRA設定 | lora_r: 64 lora_alpha: 32 lora_dropout: 0.05 lora_target_linear: true |
注意事項
このモデルは依然として誤ったまたは意味のない出力を生成する可能性があります。出力結果を使用する前に検証してください。
📄 ライセンス
Gemma
📚 引用
@article{Metin,
title={Metin/Gemma-2-2B-TR-Knowledge-Graph},
author={Metin Usta},
year={2024},
url={https://huggingface.co/Metin/Gemma-2-2B-TR-Knowledge-Graph}
}
Rebel Large
REBELは、BARTベースのシーケンス-to-シーケンスモデルで、エンドツーエンドの関係抽出に使用され、200種類以上の異なる関係タイプをサポートします。
知識グラフ Transformers 英語
Transformers 英語
R
Babelscape
37.57k
219
Nel Mgenre Multilingual
mGENREに基づく多言語生成型エンティティ検索モデルで、歴史テキストに最適化され、100種以上の言語をサポートし、特にフランス語、ドイツ語、英語の歴史文書のエンティティリンクに適しています。
知識グラフ Transformers 複数言語対応
N
impresso-project
17.13k
2
Biomednlp KRISSBERT PubMed UMLS EL
MIT
KRISSBERTは知識強化型自己教師あり学習に基づく生物医学エンティティリンキングモデルで、アノテーションのないテキストとドメイン知識を活用してコンテキストエンコーダーを訓練し、エンティティ名の多様なバリエーションと曖昧性の問題を効果的に解決します。
知識グラフ Transformers 英語
B
microsoft
4,643
29
Coder Eng
Apache-2.0
CODERは、知識強化型の多言語医学用語埋め込みモデルで、医学用語の規範化タスクに特化しています。
知識グラフ Transformers 英語
C
GanjinZero
4,298
4
Umlsbert ENG
Apache-2.0
CODERは知識注入に基づく多言語医療用語埋め込みモデルで、医療用語の標準化タスクに特化しています。
知識グラフ Transformers 英語
U
GanjinZero
3,400
13
Text2cypher Gemma 2 9b It Finetuned 2024v1
Apache-2.0
このモデルはgoogle/gemma-2-9b-itをファインチューニングしたText2Cypherモデルで、自然言語の質問をNeo4jグラフデータベースのCypherクエリ文に変換できます。
知識グラフ Safetensors 英語
Safetensors 英語
Safetensors 英語T
neo4j
2,093
22
Triplex
TriplexはSciPhi.AIがPhi3-3.8Bをファインチューニングしたモデルで、非構造化データからの知識グラフ構築のために設計されており、知識グラフ作成コストを98%削減できます。
知識グラフ
T
SciPhi
1,808
278
Genre Linking Blink
GENREはシーケンス・ツー・シーケンス手法に基づくエンティティ検索システムで、ファインチューニングされたBARTアーキテクチャを使用し、制約付きビームサーチ技術によって一意のエンティティ名を生成します。
知識グラフ 英語
G
facebook
671
10
Text To Cypher Gemma 3 4B Instruct 2025.04.0
Gemma 3.4B IT はテキスト生成型の大規模言語モデルで、自然言語をCypherクエリ言語に変換するために特別に設計されています。
知識グラフ Safetensors
SafetensorsT
neo4j
596
2
Mrebel Large
REDFMはREBELの多言語バージョンで、18言語の関係トリプル抽出をサポートしています。
知識グラフ Transformers 複数言語対応
M
Babelscape
573
71
おすすめAIモデル
Llama 3 Typhoon V1.5x 8b Instruct
タイ語専用に設計された80億パラメータの命令モデルで、GPT-3.5-turboに匹敵する性能を持ち、アプリケーションシナリオ、検索拡張生成、制限付き生成、推論タスクを最適化
大規模言語モデル Transformers 複数言語対応
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-TinyはSODAデータセットでトレーニングされた超小型対話モデルで、エッジデバイス推論向けに設計されており、体積はCosmo-3Bモデルの約2%です。
対話システム Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
RoBERTaアーキテクチャに基づく中国語抽出型QAモデルで、与えられたテキストから回答を抽出するタスクに適しています。
質問応答システム 中国語
R
uer
2,694
98