%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
ZH
Gemma 2 2B TR Knowledge Graph
Gemma-2-2B-TR-Knowledge-Graph 是基于 gemma-2-2b-it 微调的模型,专注于从文档内容生成结构化知识图谱。
下载量 122
发布时间 : 1/16/2025
模型简介
该模型能够从文档内容中自动生成结构化的知识图谱,可用于构建和填充图数据库,实现数据关系的高效存储、查询和可视化。
模型特点
高质量知识图谱生成
在高质量的知识图谱生成样本上进行了训练,能够从文档内容中自动生成结构化的知识图谱。
图数据库支持
生成的知识图谱可用于构建和填充图数据库,支持数据关系的高效存储、查询和可视化。
高效微调
基于 gemma-2-2b-it 模型进行微调,训练时间短,效果显著。
模型能力
文本生成
知识图谱提取
结构化数据生成
使用案例
知识管理
学术文献分析
从学术文献中提取关键概念和关系,构建知识图谱。
生成的结构化知识图谱可用于学术研究和文献综述。
企业知识库构建
从企业文档中提取实体和关系,构建企业知识库。
支持企业知识的高效存储和查询。
数据可视化
知识图谱可视化
将生成的图谱数据可视化,展示复杂关系网络。
提供直观的数据关系展示,便于理解和分析。
🚀 Gemma-2-2B-TR-Knowledge-Graph
Gemma-2-2B-TR-Knowledge-Graph 是 gemma-2-2b-it 的微调版本。它在高质量的知识图谱生成样本上进行了训练,能够从文档内容中自动生成结构化的知识图谱,可用于构建和填充图数据库,实现数据关系的高效存储、查询和可视化。

🚀 快速开始
安装
首先,你需要安装 vLLM:
pip install vllm
使用示例
在用户提示的末尾添加 \n<knowledge_graph> 以触发知识图谱提取:
from vllm import LLM, SamplingParams
import json
llm = LLM(model="Metin/Gemma-2-2B-TR-Knowledge-Graph")
sampling_params = SamplingParams(temperature=0.1, max_tokens=4096)
content = """Guido van Rossum (d. 31 Ocak 1956), Hollandalı bir bilgisayar programcısıdır.
Python programlama dilinin yazarıdır. Van Rossum 12 Temmuz 2018'de Python yönetiminden istifa ettiğini ve emekliye ayrıldığını duyurdu.[1] 12 Kasım 2020 tarihinde emeklilikten geri dönerek Microsoft'a katıldığını açıklamıştır.[2]"""
conversation = [
{
"role": "user",
"content": content + "\n<knowledge_graph>"
}
]
outputs = llm.chat(
conversation,
sampling_params=sampling_params,
use_tqdm=False
)
result = json.loads(outputs[0].outputs[0].text)
print(result)
✨ 主要特性
- 基于 gemma-2-2b-it 模型进行微调,可从文档内容中自动生成结构化知识图谱。
- 生成的知识图谱可用于构建和填充图数据库,支持数据关系的高效存储、查询和可视化。
📦 安装指南
安装 vLLM:
pip install vllm
💻 使用示例
基础用法
以下是一个使用该模型生成知识图谱的示例:
from vllm import LLM, SamplingParams
import json
llm = LLM(model="Metin/Gemma-2-2B-TR-Knowledge-Graph")
sampling_params = SamplingParams(temperature=0.1, max_tokens=4096)
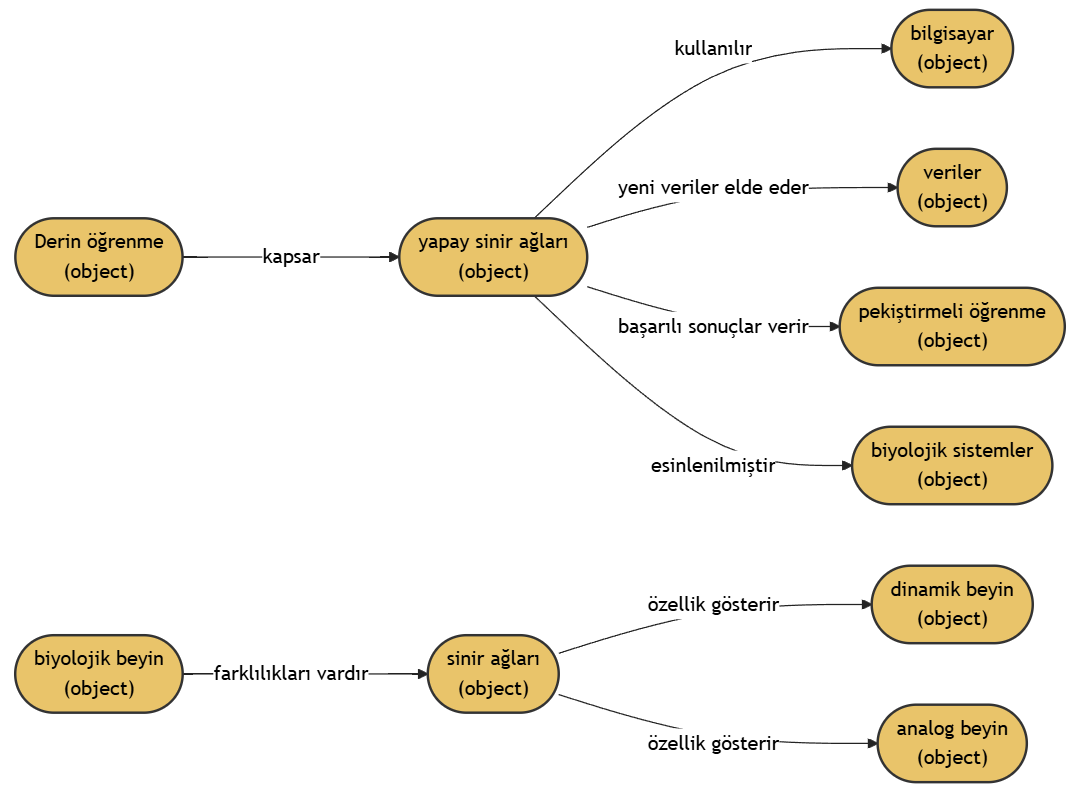
content = """Derin öğrenme (aynı zamanda derin yapılandırılmış öğrenme, hiyerarşik öğrenme ya da derin makine öğrenmesi) bir veya daha fazla gizli katman içeren yapay sinir ağları ve benzeri makine öğrenme algoritmalarını kapsayan çalışma alanıdır.
Yani en az bir adet yapay sinir ağının (YSA) kullanıldığı ve birçok algoritma ile, bilgisayarın eldeki verilerden yeni veriler elde etmesidir.
Derin öğrenme gözetimli, yarı gözetimli veya gözetimsiz olarak gerçekleştirilebilir.[1] Derin yapay sinir ağları pekiştirmeli öğrenme yaklaşımıyla da başarılı sonuçlar vermiştir.[2] Yapay sinir ağları, biyolojik sistemlerdeki bilgi işleme ve dağıtılmış iletişim düğümlerinden esinlenilmiştir. Yapay sinir ağlarının biyolojik beyinlerden çeşitli farklılıkları vardır. Özellikle, sinir ağları statik ve sembolik olma eğilimindeyken, çoğu canlı organizmanın biyolojik beyni dinamik(plastik) ve analogtur.[3][4][5]"""
conversation = [
{
"role": "user",
"content": content + "\n<knowledge_graph>"
}
]
outputs = llm.chat(
conversation,
sampling_params=sampling_params,
use_tqdm=False
)
result = json.loads(outputs[0].outputs[0].text)
print(result)
输出示例
示例 1
文档内容:
Derin öğrenme (aynı zamanda derin yapılandırılmış öğrenme, hiyerarşik öğrenme ya da derin makine öğrenmesi) bir veya daha fazla gizli katman içeren yapay sinir ağları ve benzeri makine öğrenme algoritmalarını kapsayan çalışma alanıdır.
Yani en az bir adet yapay sinir ağının (YSA) kullanıldığı ve birçok algoritma ile, bilgisayarın eldeki verilerden yeni veriler elde etmesidir.
Derin öğrenme gözetimli, yarı gözetimli veya gözetimsiz olarak gerçekleştirilebilir.[1] Derin yapay sinir ağları pekiştirmeli öğrenme yaklaşımıyla da başarılı sonuçlar vermiştir.[2] Yapay sinir ağları, biyolojik sistemlerdeki bilgi işleme ve dağıtılmış iletişim düğümlerinden esinlenilmiştir. Yapay sinir ağlarının biyolojik beyinlerden çeşitli farklılıkları vardır. Özellikle, sinir ağları statik ve sembolik olma eğilimindeyken, çoğu canlı organizmanın biyolojik beyni dinamik(plastik) ve analogtur.[3][4][5]
输出结果:
{
"nodes": [
{
"type": "object",
"name": "Derin öğrenme"
},
{
"type": "object",
"name": "yapay sinir ağları"
},
{
"type": "object",
"name": "bilgisayar"
},
{
"type": "object",
"name": "veriler"
},
{
"type": "object",
"name": "pekiştirmeli öğrenme"
},
{
"type": "object",
"name": "biyolojik sistemler"
},
{
"type": "object",
"name": "biyolojik beyin"
},
{
"type": "object",
"name": "sinir ağları"
},
{
"type": "object",
"name": "dinamik beyin"
},
{
"type": "object",
"name": "analog beyin"
}
],
"relationships": [
{
"source": "Derin öğrenme",
"target": "yapay sinir ağları",
"relationship": "kapsar"
},
{
"source": "yapay sinir ağları",
"target": "bilgisayar",
"relationship": "kullanılır"
},
{
"source": "yapay sinir ağları",
"target": "veriler",
"relationship": "yeni veriler elde eder"
},
{
"source": "yapay sinir ağları",
"target": "pekiştirmeli öğrenme",
"relationship": "başarılı sonuçlar verir"
},
{
"source": "yapay sinir ağları",
"target": "biyolojik sistemler",
"relationship": "esinlenilmiştir"
},
{
"source": "biyolojik beyin",
"target": "sinir ağları",
"relationship": "farklılıkları vardır"
},
{
"source": "sinir ağları",
"target": "dinamik beyin",
"relationship": "özellik gösterir"
},
{
"source": "sinir ağları",
"target": "analog beyin",
"relationship": "özellik gösterir"
}
]
}
知识图谱可视化:
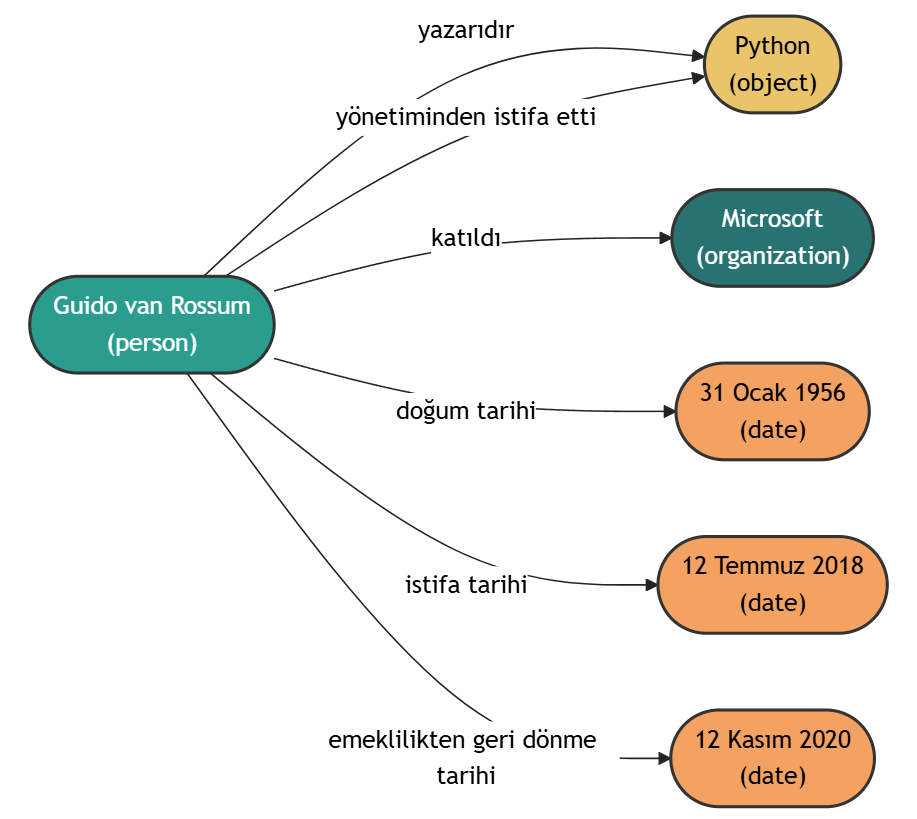
示例 2
文档内容:
Guido van Rossum (d. 31 Ocak 1956), Hollandalı bir bilgisayar programcısıdır.
Python programlama dilinin yazarıdır. Van Rossum 12 Temmuz 2018'de Python yönetiminden istifa ettiğini ve emekliye ayrıldığını duyurdu.[1] 12 Kasım 2020 tarihinde emeklilikten geri dönerek Microsoft'a katıldığını açıklamıştır.[2]
输出结果:
{
"nodes": [
{
"type": "person",
"name": "Guido van Rossum"
},
{
"type": "object",
"name": "Python"
},
{
"type": "organization",
"name": "Microsoft"
},
{
"type": "date",
"name": "31 Ocak 1956"
},
{
"type": "date",
"name": "12 Temmuz 2018"
},
{
"type": "date",
"name": "12 Kasım 2020"
}
],
"relationships": [
{
"source": "Guido van Rossum",
"target": "Python",
"relationship": "yazarıdır"
},
{
"source": "Guido van Rossum",
"target": "Python",
"relationship": "yönetiminden istifa etti"
},
{
"source": "Guido van Rossum",
"target": "Microsoft",
"relationship": "katıldı"
},
{
"source": "Guido van Rossum",
"target": "31 Ocak 1956",
"relationship": "doğum tarihi"
},
{
"source": "Guido van Rossum",
"target": "12 Temmuz 2018",
"relationship": "istifa tarihi"
},
{
"source": "Guido van Rossum",
"target": "12 Kasım 2020",
"relationship": "emeklilikten geri dönme tarihi"
}
]
}
知识图谱可视化:
🔧 技术细节
模型信息
| 属性 | 详情 |
|---|---|
| 模型类型 | Gemma-2-2B-TR-Knowledge-Graph |
| 基础模型 | gemma-2-2b-it |
| 训练数据 | 使用了一个由 30K 个样本组成的合成生成知识图谱数据集,不包含专有数据。 |
| 训练时间 | 在单个 RTX 6000 ADA 上训练 3 小时。 |
| LoRA 配置 | lora_r: 64 lora_alpha: 32 lora_dropout: 0.05 lora_target_linear: true |
注意事项
该模型仍可能会生成错误或无意义的输出,请在使用输出结果之前进行验证。
📄 许可证
Gemma
📚 引用
@article{Metin,
title={Metin/Gemma-2-2B-TR-Knowledge-Graph},
author={Metin Usta},
year={2024},
url={https://huggingface.co/Metin/Gemma-2-2B-TR-Knowledge-Graph}
}
Rebel Large
REBEL是一种基于BART的序列到序列模型,用于端到端关系抽取,支持200多种不同关系类型。
知识图谱 Transformers 英语
Transformers 英语
R
Babelscape
37.57k
219
Nel Mgenre Multilingual
基于mGENRE的多语言生成式实体检索模型,针对历史文本优化,支持100+种语言,特别适配法语、德语和英语的历史文档实体链接。
知识图谱 Transformers 支持多种语言
N
impresso-project
17.13k
2
Biomednlp KRISSBERT PubMed UMLS EL
MIT
KRISSBERT是一个基于知识增强自监督学习的生物医学实体链接模型,通过利用无标注文本和领域知识训练上下文编码器,有效解决实体名称多样性变异和歧义性问题。
知识图谱 Transformers 英语
B
microsoft
4,643
29
Coder Eng
Apache-2.0
CODER是一种知识增强型跨语言医学术语嵌入模型,专注于医学术语规范化任务。
知识图谱 Transformers 英语
C
GanjinZero
4,298
4
Umlsbert ENG
Apache-2.0
CODER是一个基于知识注入的跨语言医学术语嵌入模型,专注于医学术语标准化任务。
知识图谱 Transformers 英语
U
GanjinZero
3,400
13
Text2cypher Gemma 2 9b It Finetuned 2024v1
Apache-2.0
该模型是基于google/gemma-2-9b-it微调的Text2Cypher模型,能够将自然语言问题转换为Neo4j图数据库的Cypher查询语句。
知识图谱 Safetensors 英语
Safetensors 英语
Safetensors 英语T
neo4j
2,093
22
Triplex
Triplex是SciPhi.AI基于Phi3-3.8B微调的模型,专为从非结构化数据构建知识图谱设计,可将知识图谱创建成本降低98%。
知识图谱
T
SciPhi
1,808
278
Genre Linking Blink
GENRE是一种基于序列到序列方法的实体检索系统,采用微调后的BART架构,通过受约束的束搜索技术生成唯一实体名称。
知识图谱 英语
G
facebook
671
10
Text To Cypher Gemma 3 4B Instruct 2025.04.0
Gemma 3.4B IT 是一个基于文本到文本生成的大语言模型,专门用于将自然语言转换为Cypher查询语言。
知识图谱 Safetensors
SafetensorsT
neo4j
596
2
Mrebel Large
REDFM是REBEL的多语言版本,用于多语言关系抽取任务,支持18种语言的关系三元组提取。
知识图谱 Transformers 支持多种语言
M
Babelscape
573
71
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98