%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
TW
Gemma 2 2B TR Knowledge Graph
Gemma-2-2B-TR-Knowledge-Graph 是基於 gemma-2-2b-it 微調的模型,專注於從文檔內容生成結構化知識圖譜。
下載量 122
發布時間 : 1/16/2025
模型概述
該模型能夠從文檔內容中自動生成結構化的知識圖譜,可用於構建和填充圖數據庫,實現數據關係的高效存儲、查詢和可視化。
模型特點
高質量知識圖譜生成
在高質量的知識圖譜生成樣本上進行了訓練,能夠從文檔內容中自動生成結構化的知識圖譜。
圖數據庫支持
生成的知識圖譜可用於構建和填充圖數據庫,支持數據關係的高效存儲、查詢和可視化。
高效微調
基於 gemma-2-2b-it 模型進行微調,訓練時間短,效果顯著。
模型能力
文本生成
知識圖譜提取
結構化數據生成
使用案例
知識管理
學術文獻分析
從學術文獻中提取關鍵概念和關係,構建知識圖譜。
生成的結構化知識圖譜可用於學術研究和文獻綜述。
企業知識庫構建
從企業文檔中提取實體和關係,構建企業知識庫。
支持企業知識的高效存儲和查詢。
數據可視化
知識圖譜可視化
將生成的圖譜數據可視化,展示覆雜關係網絡。
提供直觀的數據關係展示,便於理解和分析。
🚀 Gemma-2-2B-TR-Knowledge-Graph
Gemma-2-2B-TR-Knowledge-Graph 是 gemma-2-2b-it 的微調版本。它在高質量的知識圖譜生成樣本上進行了訓練,能夠從文檔內容中自動生成結構化的知識圖譜,可用於構建和填充圖數據庫,實現數據關係的高效存儲、查詢和可視化。

🚀 快速開始
安裝
首先,你需要安裝 vLLM:
pip install vllm
使用示例
在用戶提示的末尾添加 \n<knowledge_graph> 以觸發知識圖譜提取:
from vllm import LLM, SamplingParams
import json
llm = LLM(model="Metin/Gemma-2-2B-TR-Knowledge-Graph")
sampling_params = SamplingParams(temperature=0.1, max_tokens=4096)
content = """Guido van Rossum (d. 31 Ocak 1956), Hollandalı bir bilgisayar programcısıdır.
Python programlama dilinin yazarıdır. Van Rossum 12 Temmuz 2018'de Python yönetiminden istifa ettiğini ve emekliye ayrıldığını duyurdu.[1] 12 Kasım 2020 tarihinde emeklilikten geri dönerek Microsoft'a katıldığını açıklamıştır.[2]"""
conversation = [
{
"role": "user",
"content": content + "\n<knowledge_graph>"
}
]
outputs = llm.chat(
conversation,
sampling_params=sampling_params,
use_tqdm=False
)
result = json.loads(outputs[0].outputs[0].text)
print(result)
✨ 主要特性
- 基於 gemma-2-2b-it 模型進行微調,可從文檔內容中自動生成結構化知識圖譜。
- 生成的知識圖譜可用於構建和填充圖數據庫,支持數據關係的高效存儲、查詢和可視化。
📦 安裝指南
安裝 vLLM:
pip install vllm
💻 使用示例
基礎用法
以下是一個使用該模型生成知識圖譜的示例:
from vllm import LLM, SamplingParams
import json
llm = LLM(model="Metin/Gemma-2-2B-TR-Knowledge-Graph")
sampling_params = SamplingParams(temperature=0.1, max_tokens=4096)
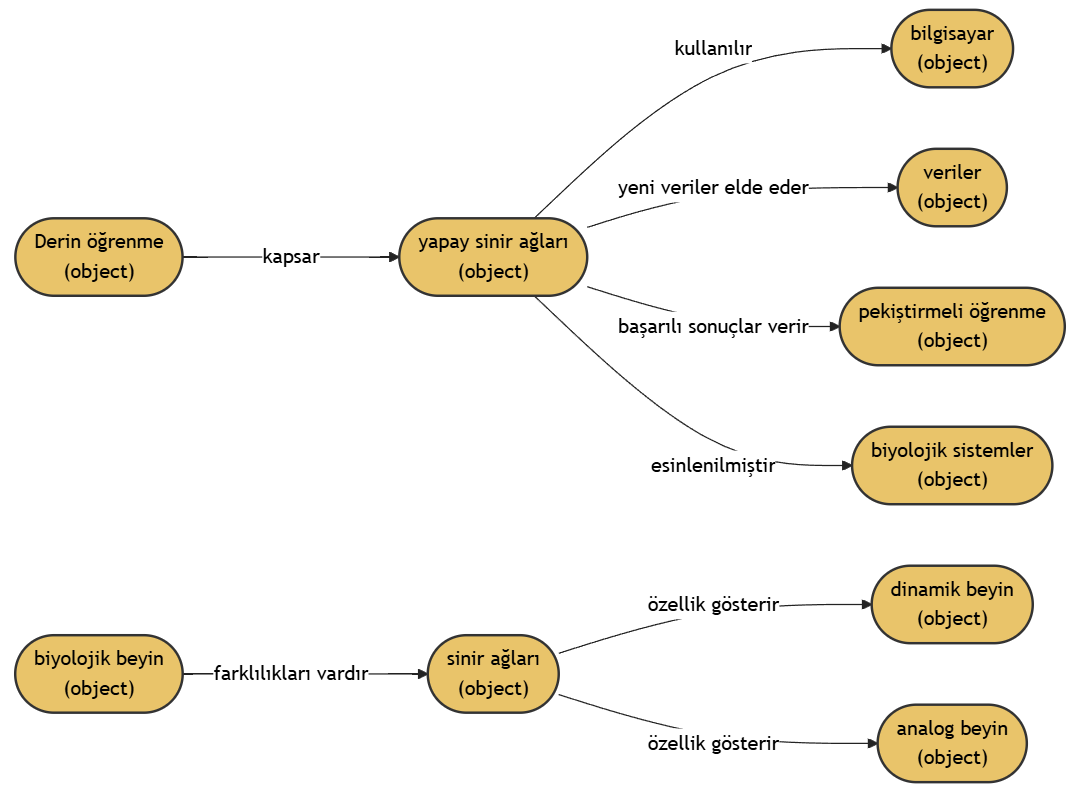
content = """Derin öğrenme (aynı zamanda derin yapılandırılmış öğrenme, hiyerarşik öğrenme ya da derin makine öğrenmesi) bir veya daha fazla gizli katman içeren yapay sinir ağları ve benzeri makine öğrenme algoritmalarını kapsayan çalışma alanıdır.
Yani en az bir adet yapay sinir ağının (YSA) kullanıldığı ve birçok algoritma ile, bilgisayarın eldeki verilerden yeni veriler elde etmesidir.
Derin öğrenme gözetimli, yarı gözetimli veya gözetimsiz olarak gerçekleştirilebilir.[1] Derin yapay sinir ağları pekiştirmeli öğrenme yaklaşımıyla da başarılı sonuçlar vermiştir.[2] Yapay sinir ağları, biyolojik sistemlerdeki bilgi işleme ve dağıtılmış iletişim düğümlerinden esinlenilmiştir. Yapay sinir ağlarının biyolojik beyinlerden çeşitli farklılıkları vardır. Özellikle, sinir ağları statik ve sembolik olma eğilimindeyken, çoğu canlı organizmanın biyolojik beyni dinamik(plastik) ve analogtur.[3][4][5]"""
conversation = [
{
"role": "user",
"content": content + "\n<knowledge_graph>"
}
]
outputs = llm.chat(
conversation,
sampling_params=sampling_params,
use_tqdm=False
)
result = json.loads(outputs[0].outputs[0].text)
print(result)
輸出示例
示例 1
文檔內容:
Derin öğrenme (aynı zamanda derin yapılandırılmış öğrenme, hiyerarşik öğrenme ya da derin makine öğrenmesi) bir veya daha fazla gizli katman içeren yapay sinir ağları ve benzeri makine öğrenme algoritmalarını kapsayan çalışma alanıdır.
Yani en az bir adet yapay sinir ağının (YSA) kullanıldığı ve birçok algoritma ile, bilgisayarın eldeki verilerden yeni veriler elde etmesidir.
Derin öğrenme gözetimli, yarı gözetimli veya gözetimsiz olarak gerçekleştirilebilir.[1] Derin yapay sinir ağları pekiştirmeli öğrenme yaklaşımıyla da başarılı sonuçlar vermiştir.[2] Yapay sinir ağları, biyolojik sistemlerdeki bilgi işleme ve dağıtılmış iletişim düğümlerinden esinlenilmiştir. Yapay sinir ağlarının biyolojik beyinlerden çeşitli farklılıkları vardır. Özellikle, sinir ağları statik ve sembolik olma eğilimindeyken, çoğu canlı organizmanın biyolojik beyni dinamik(plastik) ve analogtur.[3][4][5]
輸出結果:
{
"nodes": [
{
"type": "object",
"name": "Derin öğrenme"
},
{
"type": "object",
"name": "yapay sinir ağları"
},
{
"type": "object",
"name": "bilgisayar"
},
{
"type": "object",
"name": "veriler"
},
{
"type": "object",
"name": "pekiştirmeli öğrenme"
},
{
"type": "object",
"name": "biyolojik sistemler"
},
{
"type": "object",
"name": "biyolojik beyin"
},
{
"type": "object",
"name": "sinir ağları"
},
{
"type": "object",
"name": "dinamik beyin"
},
{
"type": "object",
"name": "analog beyin"
}
],
"relationships": [
{
"source": "Derin öğrenme",
"target": "yapay sinir ağları",
"relationship": "kapsar"
},
{
"source": "yapay sinir ağları",
"target": "bilgisayar",
"relationship": "kullanılır"
},
{
"source": "yapay sinir ağları",
"target": "veriler",
"relationship": "yeni veriler elde eder"
},
{
"source": "yapay sinir ağları",
"target": "pekiştirmeli öğrenme",
"relationship": "başarılı sonuçlar verir"
},
{
"source": "yapay sinir ağları",
"target": "biyolojik sistemler",
"relationship": "esinlenilmiştir"
},
{
"source": "biyolojik beyin",
"target": "sinir ağları",
"relationship": "farklılıkları vardır"
},
{
"source": "sinir ağları",
"target": "dinamik beyin",
"relationship": "özellik gösterir"
},
{
"source": "sinir ağları",
"target": "analog beyin",
"relationship": "özellik gösterir"
}
]
}
知識圖譜可視化:
示例 2
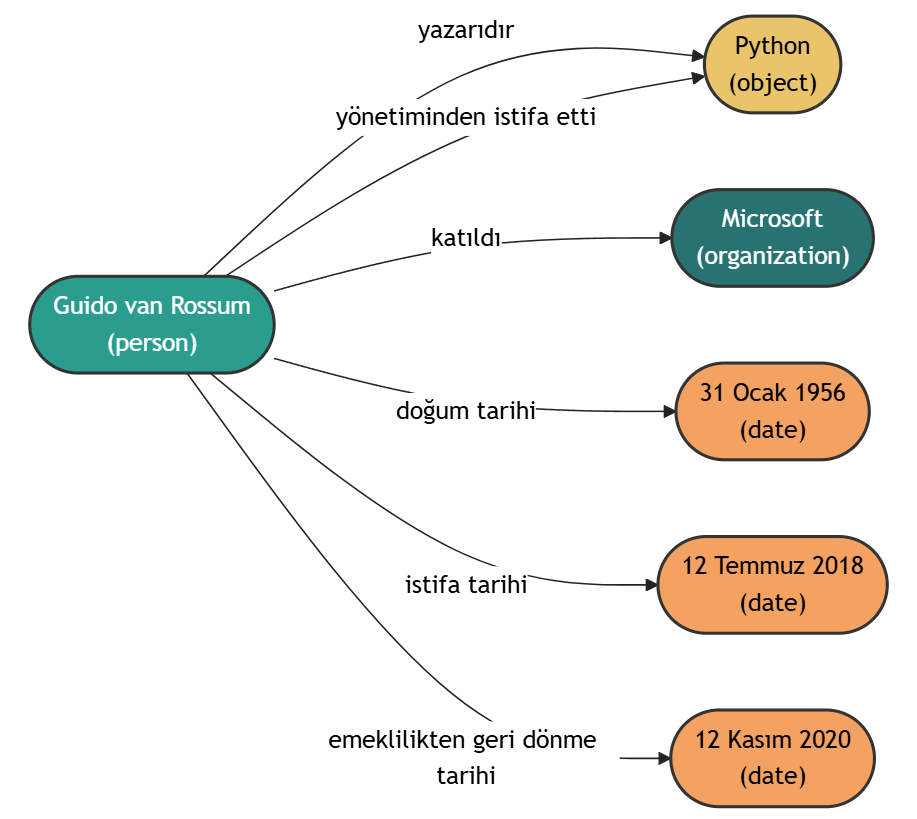
文檔內容:
Guido van Rossum (d. 31 Ocak 1956), Hollandalı bir bilgisayar programcısıdır.
Python programlama dilinin yazarıdır. Van Rossum 12 Temmuz 2018'de Python yönetiminden istifa ettiğini ve emekliye ayrıldığını duyurdu.[1] 12 Kasım 2020 tarihinde emeklilikten geri dönerek Microsoft'a katıldığını açıklamıştır.[2]
輸出結果:
{
"nodes": [
{
"type": "person",
"name": "Guido van Rossum"
},
{
"type": "object",
"name": "Python"
},
{
"type": "organization",
"name": "Microsoft"
},
{
"type": "date",
"name": "31 Ocak 1956"
},
{
"type": "date",
"name": "12 Temmuz 2018"
},
{
"type": "date",
"name": "12 Kasım 2020"
}
],
"relationships": [
{
"source": "Guido van Rossum",
"target": "Python",
"relationship": "yazarıdır"
},
{
"source": "Guido van Rossum",
"target": "Python",
"relationship": "yönetiminden istifa etti"
},
{
"source": "Guido van Rossum",
"target": "Microsoft",
"relationship": "katıldı"
},
{
"source": "Guido van Rossum",
"target": "31 Ocak 1956",
"relationship": "doğum tarihi"
},
{
"source": "Guido van Rossum",
"target": "12 Temmuz 2018",
"relationship": "istifa tarihi"
},
{
"source": "Guido van Rossum",
"target": "12 Kasım 2020",
"relationship": "emeklilikten geri dönme tarihi"
}
]
}
知識圖譜可視化:
🔧 技術細節
模型信息
| 屬性 | 詳情 |
|---|---|
| 模型類型 | Gemma-2-2B-TR-Knowledge-Graph |
| 基礎模型 | gemma-2-2b-it |
| 訓練數據 | 使用了一個由 30K 個樣本組成的合成生成知識圖譜數據集,不包含專有數據。 |
| 訓練時間 | 在單個 RTX 6000 ADA 上訓練 3 小時。 |
| LoRA 配置 | lora_r: 64 lora_alpha: 32 lora_dropout: 0.05 lora_target_linear: true |
注意事項
該模型仍可能會生成錯誤或無意義的輸出,請在使用輸出結果之前進行驗證。
📄 許可證
Gemma
📚 引用
@article{Metin,
title={Metin/Gemma-2-2B-TR-Knowledge-Graph},
author={Metin Usta},
year={2024},
url={https://huggingface.co/Metin/Gemma-2-2B-TR-Knowledge-Graph}
}
Rebel Large
REBEL是一種基於BART的序列到序列模型,用於端到端關係抽取,支持200多種不同關係類型。
知識圖譜 Transformers 英語
Transformers 英語
R
Babelscape
37.57k
219
Nel Mgenre Multilingual
基於mGENRE的多語言生成式實體檢索模型,針對歷史文本優化,支持100+種語言,特別適配法語、德語和英語的歷史文檔實體鏈接。
知識圖譜 Transformers 支持多種語言
N
impresso-project
17.13k
2
Biomednlp KRISSBERT PubMed UMLS EL
MIT
KRISSBERT是一個基於知識增強自監督學習的生物醫學實體鏈接模型,通過利用無標註文本和領域知識訓練上下文編碼器,有效解決實體名稱多樣性變異和歧義性問題。
知識圖譜 Transformers 英語
B
microsoft
4,643
29
Coder Eng
Apache-2.0
CODER是一種知識增強型跨語言醫學術語嵌入模型,專注於醫學術語規範化任務。
知識圖譜 Transformers 英語
C
GanjinZero
4,298
4
Umlsbert ENG
Apache-2.0
CODER是一個基於知識注入的跨語言醫學術語嵌入模型,專注於醫學術語標準化任務。
知識圖譜 Transformers 英語
U
GanjinZero
3,400
13
Text2cypher Gemma 2 9b It Finetuned 2024v1
Apache-2.0
該模型是基於google/gemma-2-9b-it微調的Text2Cypher模型,能夠將自然語言問題轉換為Neo4j圖數據庫的Cypher查詢語句。
知識圖譜 Safetensors 英語
Safetensors 英語
Safetensors 英語T
neo4j
2,093
22
Triplex
Triplex是SciPhi.AI基於Phi3-3.8B微調的模型,專為從非結構化數據構建知識圖譜設計,可將知識圖譜創建成本降低98%。
知識圖譜
T
SciPhi
1,808
278
Genre Linking Blink
GENRE是一種基於序列到序列方法的實體檢索系統,採用微調後的BART架構,通過受約束的束搜索技術生成唯一實體名稱。
知識圖譜 英語
G
facebook
671
10
Text To Cypher Gemma 3 4B Instruct 2025.04.0
Gemma 3.4B IT 是一個基於文本到文本生成的大語言模型,專門用於將自然語言轉換為Cypher查詢語言。
知識圖譜 Safetensors
SafetensorsT
neo4j
596
2
Mrebel Large
REDFM是REBEL的多語言版本,用於多語言關係抽取任務,支持18種語言的關係三元組提取。
知識圖譜 Transformers 支持多種語言
M
Babelscape
573
71
精選推薦AI模型
Llama 3 Typhoon V1.5x 8b Instruct
專為泰語設計的80億參數指令模型,性能媲美GPT-3.5-turbo,優化了應用場景、檢索增強生成、受限生成和推理任務
大型語言模型 Transformers 支持多種語言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一個基於SODA數據集訓練的超小型對話模型,專為邊緣設備推理設計,體積僅為Cosmo-3B模型的2%左右。
對話系統 Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基於RoBERTa架構的中文抽取式問答模型,適用於從給定文本中提取答案的任務。
問答系統 中文
R
uer
2,694
98