🚀 Qwen2.5-Omni-7B GGUFモデル
Qwen2.5-Omni-7B GGUFモデルは、多様なモダリティを扱うことができるモデルです。このREADMEでは、モデルの生成詳細、量子化方法、適切なモデルフォーマットの選択方法などについて説明します。
🚀 クイックスタート
このセクションでは、Qwen2.5-Omni-7B GGUFモデルの基本的な使い方を説明します。
✨ 主な機能
モデル生成詳細
このモデルは、llama.cpp のコミット 1f63e75f を使用して生成されました。
量子化方法
標準のIMatrixでは、低ビット量子化やMOEモデルでの性能が十分ではないことがわかりました。そこで、Layer bumping with llama.cpp を参照して、llama.cppの --tensor-type を使用して選択したレイヤーのビット数を上げる方法を試しています。これにより、モデルファイルのサイズは大きくなりますが、与えられたモデルサイズに対する精度が向上します。
モデルフォーマットの選択
モデルフォーマットの選択は、ハードウェア能力 と メモリ制限 に依存します。以下に、いくつかのモデルフォーマットとその特徴を示します。
BF16 (Brain Float 16)
- 16ビット浮動小数点数形式で、高速な計算と良好な精度を両立します。
- FP32と同様のダイナミックレンジを持ち、メモリ使用量が少ないです。
- ハードウェアがBF16アクセラレーションをサポートしている場合に推奨されます。
使用する場合:
- ハードウェアがネイティブのBF16サポートを持っている場合(例:新しいGPU、TPU)。
- メモリを節約しながら、より高い精度が必要な場合。
- モデルを別のフォーマットに再量子化する予定の場合。
避ける場合:
- ハードウェアがBF16をサポートしていない場合(FP32にフォールバックし、低速になる可能性があります)。
- BF16最適化を持たない古いデバイスとの互換性が必要な場合。
F16 (Float 16)
- 16ビット浮動小数点数形式で、BF16よりも広くサポートされています。
- 多くのGPUや一部のCPUで動作します。
- BF16よりも若干数値精度が低いですが、推論には一般的に十分です。
使用する場合:
- ハードウェアがFP16をサポートしているが、BF16をサポートしていない場合。
- 速度、メモリ使用量、精度のバランスが必要な場合。
- FP16計算に最適化されたGPUや他のデバイスで実行する場合。
避ける場合:
- デバイスがネイティブのFP16サポートを持っていない場合(予想よりも低速になる可能性があります)。
- メモリ制限がある場合。
ハイブリッド精度モデル (例: bf16_q8_0, f16_q4_K)
- 重要でないレイヤーを量子化し、キーレイヤーを完全精度で保持することで、メモリ効率と精度のバランスを取ります。
- 例えば、
bf16_q8_0 は、完全精度のBF16コアレイヤーと量子化されたQ8_0の他のレイヤーを持ちます。
使用する場合:
- 量子化のみのモデルよりも高い精度が必要で、完全なBF16/F16をすべてのレイヤーに適用できない場合。
- デバイスが混合精度推論をサポートしている場合。
- 制約のあるハードウェアでの本番グレードのモデルのトレードオフを最適化したい場合。
避ける場合:
- ターゲットデバイスが混合または完全精度のアクセラレーションをサポートしていない場合。
- 非常に厳しいメモリ制限の下で動作している場合(この場合は完全に量子化されたフォーマットを使用します)。
量子化モデル (Q4_K, Q6_K, Q8など)
- モデルサイズとメモリ使用量を削減しながら、できるだけ精度を維持します。
- 低ビットモデル(Q4_K)は、最小限のメモリ使用量に最適ですが、精度が低い場合があります。
- 高ビットモデル(Q6_K、Q8_0)は、より高い精度を提供しますが、より多くのメモリを必要とします。
使用する場合:
- CPUで推論を実行し、最適化されたモデルが必要な場合。
- デバイスのVRAMが少なく、完全精度のモデルをロードできない場合。
- 合理的な精度を維持しながら、メモリフットプリントを削減したい場合。
避ける場合:
- 最大の精度が必要な場合(完全精度のモデルの方が適しています)。
- ハードウェアに十分なVRAMがあり、より高精度のフォーマット(BF16/F16)を使用できる場合。
超低ビット量子化 (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)
-
非常に高いメモリ効率を実現するために最適化されており、低電力デバイスや大規模なデプロイメントでメモリが重要な制約となる場合に最適です。
-
IQ3_XS: 超低ビット量子化(3ビット)で、非常に高いメモリ効率を持ちます。
- 使用例: Q4_Kでさえ大きすぎる超低メモリデバイスに最適。
- トレードオフ: 高ビット量子化と比較して精度が低い。
-
IQ3_S: 最大のメモリ効率を実現するための小さなブロックサイズ。
- 使用例: IQ3_XSが過度に制限的な低メモリデバイスに最適。
-
IQ3_M: IQ3_Sよりも良好な精度を実現するための中サイズのブロックサイズ。
- 使用例: IQ3_Sが制限的すぎる低メモリデバイスに適しています。
-
Q4_K: ブロック単位の最適化により、より高い精度を実現する4ビット量子化。
- 使用例: Q6_Kが大きすぎる低メモリデバイスに最適。
-
Q4_0: ARMデバイス用に最適化された純粋な4ビット量子化。
- 使用例: ARMベースのデバイスまたは低メモリ環境に最適。
超超低ビット量子化 (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)
- 超超低ビット量子化(1、2ビット)で、極端なメモリ効率を持ちます。
- 使用例: 非常に制約のあるメモリにモデルを収める必要がある場合に最適。
- トレードオフ: 非常に低い精度。予想どおりに機能しない場合があります。使用前に十分にテストしてください。
モデルフォーマット選択のまとめ
| モデルフォーマット |
精度 |
メモリ使用量 |
デバイス要件 |
最適な使用例 |
| BF16 |
非常に高い |
高い |
BF16対応のGPU/CPU |
メモリを削減した高速推論 |
| F16 |
高い |
高い |
FP16対応のGPU/CPU |
BF16が利用できない場合の推論 |
| Q4_K |
中 - 低 |
低い |
CPUまたは低VRAMデバイス |
メモリ制約のある推論 |
| Q6_K |
中 |
中程度 |
より多くのメモリを持つCPU |
量子化によるより高い精度 |
| Q8_0 |
高い |
中程度 |
中程度のVRAMを持つGPU/CPU |
量子化モデルの中で最も高い精度 |
| IQ3_XS |
低い |
非常に低い |
超低メモリデバイス |
最大のメモリ効率、低精度 |
| IQ3_S |
低い |
非常に低い |
低メモリデバイス |
IQ3_XSよりも少し使いやすい |
| IQ3_M |
低 - 中 |
低い |
低メモリデバイス |
IQ3_Sよりも良好な精度 |
| Q4_0 |
低い |
低い |
ARMベース/組み込みデバイス |
Llama.cppがARM推論用に自動的に最適化 |
| 超超低ビット (IQ1/2_*) |
非常に低い |
非常に低い |
小さなエッジ/組み込みデバイス |
非常に制約のあるメモリにモデルを収める、低精度 |
ハイブリッド (例: bf16_q8_0) |
中 - 高 |
中程度 |
混合精度対応のハードウェア |
バランスの取れたパフォーマンスとメモリ、重要なレイヤーでのFPに近い精度 |
📚 ドキュメント
Qwen2.5-Omniの概要
Qwen2.5-Omniは、テキスト、画像、音声、ビデオなどの多様なモダリティを感知し、同時にテキストと自然な音声応答をストリーミング方式で生成するエンドツーエンドのマルチモーダルモデルです。
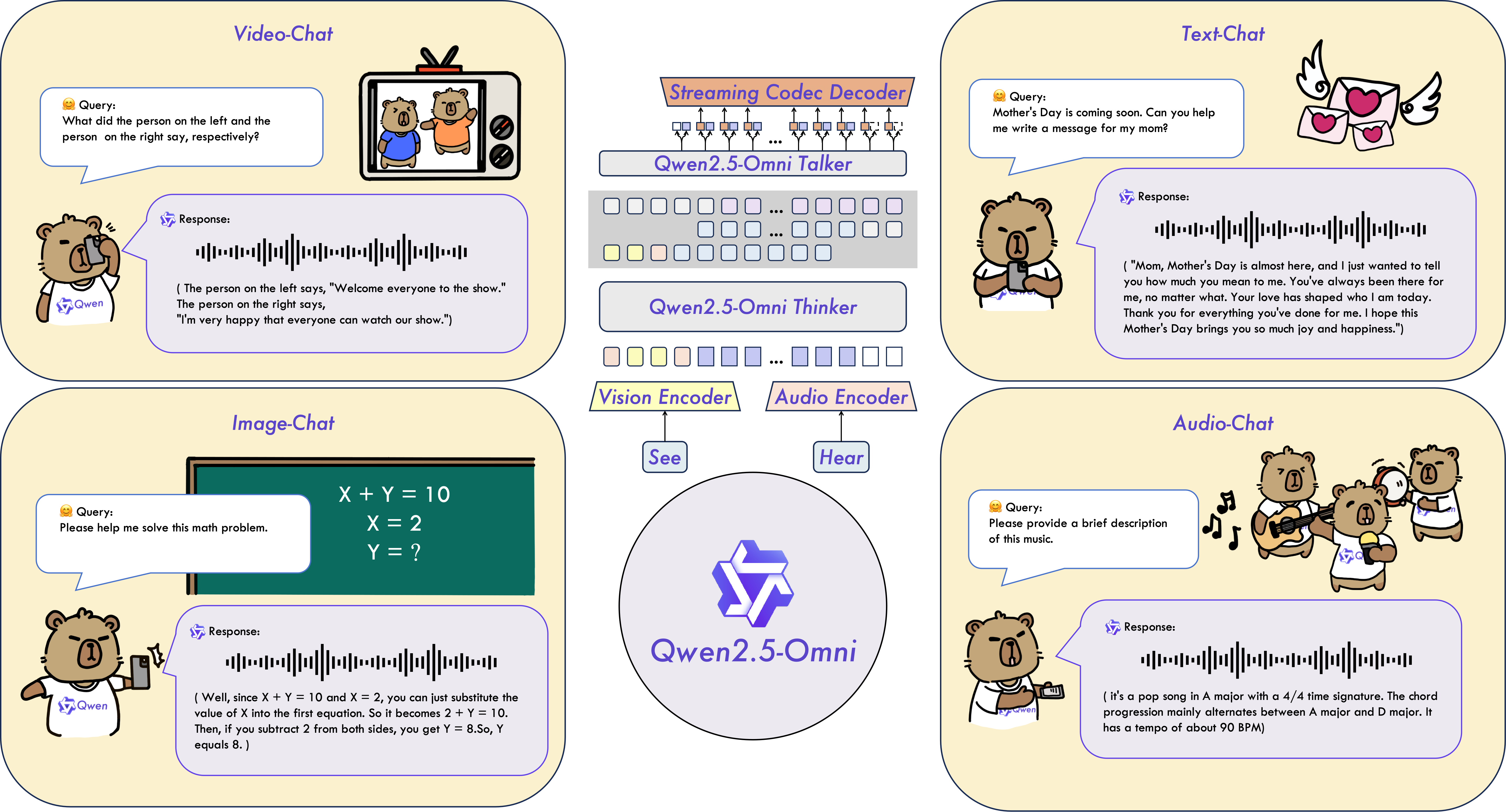
主な特徴
- オムニと革新的なアーキテクチャ: Thinker-Talkerアーキテクチャを提案し、テキスト、画像、音声、ビデオなどの多様なモダリティを感知し、同時にテキストと自然な音声応答をストリーミング方式で生成するエンドツーエンドのマルチモーダルモデルです。また、TMRoPE (Time-aligned Multimodal RoPE) という新しい位置埋め込みを提案し、ビデオ入力のタイムスタンプを音声と同期させます。
- リアルタイムの音声とビデオチャット: 完全にリアルタイムなインタラクションをサポートするアーキテクチャで、チャンク単位の入力と即時出力をサポートします。
- 自然で堅牢な音声生成: 多くの既存のストリーミングおよび非ストリーミングの代替手段を上回り、音声生成において優れた堅牢性と自然性を示します。
- すべてのモダリティでの強力なパフォーマンス: 同じサイズの単一モダリティモデルと比較して、すべてのモダリティで優れたパフォーマンスを示します。Qwen2.5-Omniは、同じサイズのQwen2-Audioよりも音声能力が優れており、Qwen2.5-VL-7Bと同等のパフォーマンスを達成しています。
- 優れたエンドツーエンドの音声命令追従: Qwen2.5-Omniは、エンドツーエンドの音声命令追従において、テキスト入力と同等の効果を示しており、MMLUやGSM8Kなどのベンチマークで証明されています。
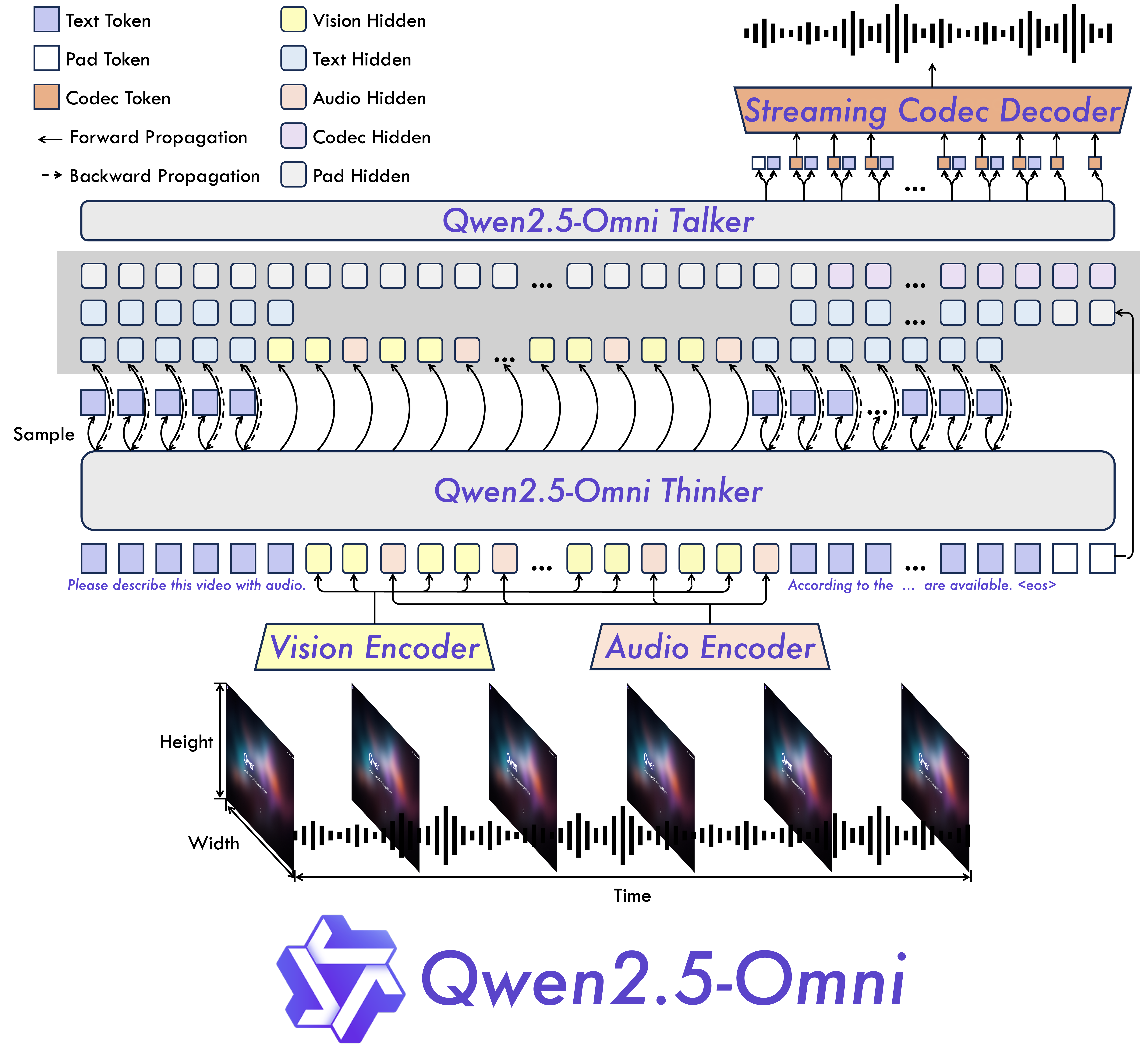
モデルアーキテクチャ
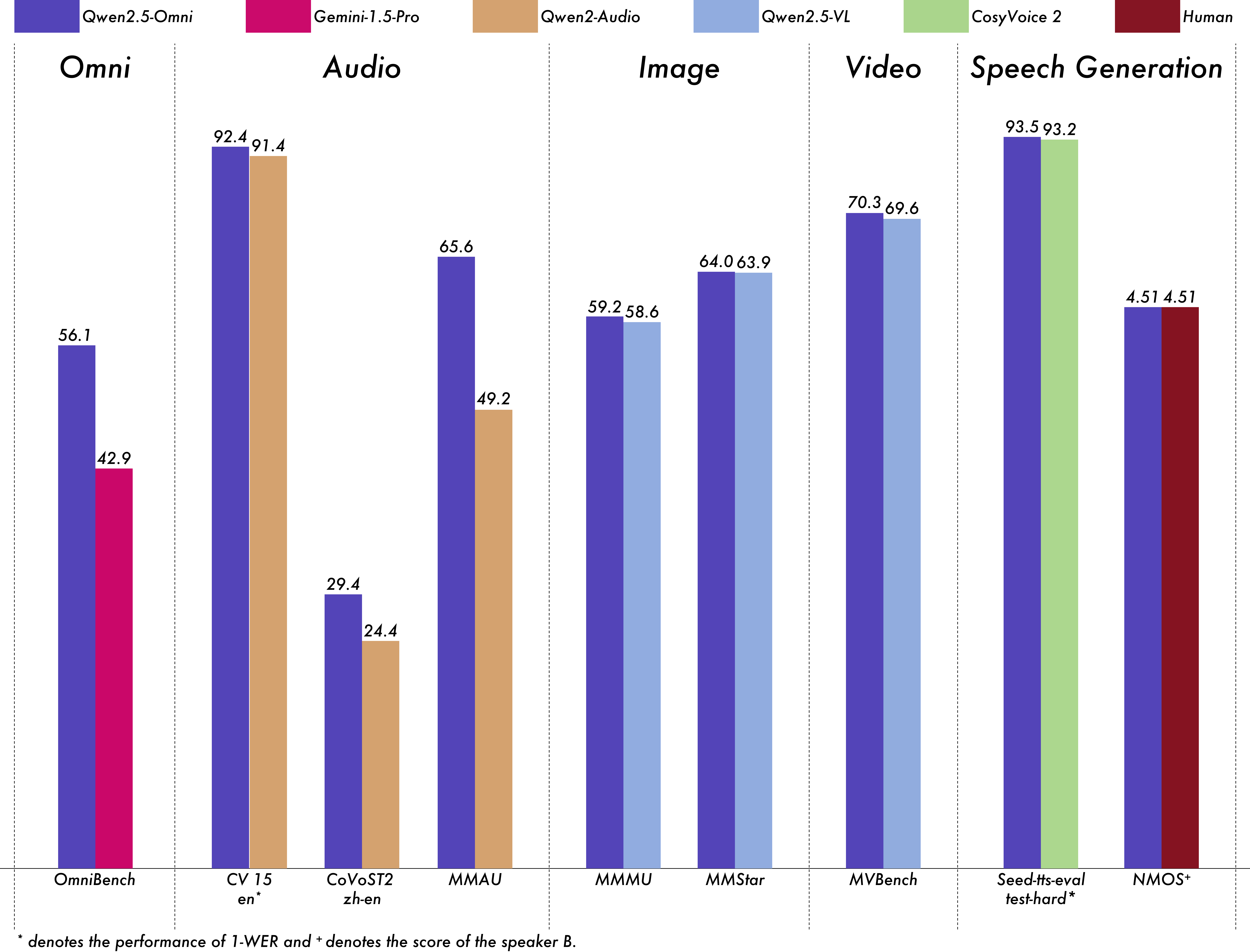
パフォーマンス
Qwen2.5-Omniの包括的な評価を行い、同じサイズの単一モダリティモデルやQwen2.5-VL-7B、Qwen2-Audio、Gemini-1.5-proなどの閉ソースモデルと比較して、すべてのモダリティで強力なパフォーマンスを示しています。OmniBenchなどの複数のモダリティの統合を必要とするタスクでは、最先端のパフォーマンスを達成しています。また、単一モダリティのタスクでは、音声認識(Common Voice)、翻訳(CoVoST2)、音声理解(MMAU)、画像推論(MMMU、MMStar)、ビデオ理解(MVBench)、音声生成(Seed-tts-evalおよび主観的な自然性)などの分野で優れています。
マルチモーダリティ -> テキスト
| データセット |
モデル |
パフォーマンス |
OmniBench
Speech | Sound Event | Music | Avg |
Gemini-1.5-Pro |
42.67%|42.26%|46.23%|42.91% |
|
MIO-Instruct |
36.96%|33.58%|11.32%|33.80% |
|
AnyGPT (7B) |
17.77%|20.75%|13.21%|18.04% |
|
video-SALMONN |
34.11%|31.70%|56.60%|35.64% |
|
UnifiedIO2-xlarge |
39.56%|36.98%|29.25%|38.00% |
|
UnifiedIO2-xxlarge |
34.24%|36.98%|24.53%|33.98% |
|
MiniCPM-o |
- |
|
Baichuan-Omni-1.5 |
- |
|
Qwen2.5-Omni-3B |
52.14%|52.08%|52.83%|52.19% |
|
Qwen2.5-Omni-7B |
55.25%|60.00%|52.83%|56.13% |
音声 -> テキスト
| データセット |
モデル |
パフォーマンス |
| ASR |
|
|
Librispeech
dev-clean | dev other | test-clean | test-other |
SALMONN |
- |
|
SpeechVerse |
- |
|
Whisper-large-v3 |
- |
|
Llama-3-8B |
- |
|
Llama-3-70B |
- |
|
Seed-ASR-Multilingual |
- |
|
MiniCPM-o |
- |
|
MinMo |
- |
|
Qwen-Audio |
1.8 |
|
Qwen2-Audio |
1.3 |
|
Qwen2.5-Omni-3B |
2.0 |
|
Qwen2.5-Omni-7B |
1.6 |
Common Voice 15
en | zh | yue | fr |
Whisper-large-v3 |
9.3 |
|
MinMo |
7.9 |
|
Qwen2-Audio |
8.6 |
|
Qwen2.5-Omni-3B |
9.1 |
|
Qwen2.5-Omni-7B |
7.6 |
Fleurs
zh | en |
Whisper-large-v3 |
7.7 |
|
Seed-ASR-Multilingual |
- |
|
Megrez-3B-Omni |
10.8 |
|
MiniCPM-o |
4.4 |
|
MinMo |
3.0 |
|
Qwen2-Audio |
7.5 |
|
Qwen2.5-Omni-3B |
3.2 |
|
Qwen2.5-Omni-7B |
3.0 |
Wenetspeech
test-net | test-meeting |
Seed-ASR-Chinese |
4.7|5.7 |
|
Megrez-3B-Omni |
- |
|
MiniCPM-o |
6.9 |
|
MinMo |
6.8 |
|
Qwen2.5-Omni-3B |
6.3 |
|
Qwen2.5-Omni-7B |
5.9 |
| Voxpopuli-V1.0-en |
Llama-3-8B |
6.2 |
|
Llama-3-70B |
5.7 |
|
Qwen2.5-Omni-3B |
6.6 |
|
Qwen2.5-Omni-7B |
5.8 |
| S2TT |
|
|
CoVoST2
en-de | de-en | en-zh | zh-en |
SALMONN |
18.6 |
|
SpeechLLaMA |
- |
|
BLSP |
14.1 |
|
MiniCPM-o |
- |
|
MinMo |
- |
|
Qwen-Audio |
25.1 |
|
Qwen2-Audio |
29.9 |
|
Qwen2.5-Omni-3B |
28.3 |
|
Qwen2.5-Omni-7B |
30.2 |
| SER |
|
|
| Meld |
WavLM-large |
0.542 |
|
MiniCPM-o |
0.524 |
|
Qwen-Audio |
0.557 |
|
Qwen2-Audio |
0.553 |
|
Qwen2.5-Omni-3B |
0.558 |
|
Qwen2.5-Omni-7B |
0.570 |
| VSC |
|
|
| VocalSound |
CLAP |
0.495 |
|
Pengi |
0.604 |
|
Qwen-Audio |
0.929 |
|
Qwen2-Audio |
0.939 |
|
Qwen2.5-Omni-3B |
0.936 |
|
Qwen2.5-Omni-7B |
0.939 |
| Music |
|
|
| GiantSteps Tempo |
Llark-7B |
0.86 |
|
Qwen2.5-Omni-3B |
0.88 |
📄 ライセンス
このモデルは、Apache 2.0ライセンス の下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応