%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 Qwen2.5-Omni-7B GGUF模型
Qwen2.5-Omni-7B GGUF模型是一款功能强大的多模态模型,能够感知文本、图像、音频和视频等多种模态信息,并以流式方式生成文本和自然语音响应。本项目详细介绍了该模型的生成细节、量化方法以及不同模型格式的选择建议,帮助用户根据自身需求选择合适的模型。
🚀 快速开始
本项目的模型生成和使用涉及到一些特定的工具和方法。以下是一些关键信息,帮助你快速了解如何开始使用Qwen2.5-Omni-7B GGUF模型:
- 模型生成:该模型使用 llama.cpp 在提交版本
1f63e75f下生成。 - 量化方法:采用了一种新的量化方法,通过规则提升重要层的量化精度,虽然会增加模型文件大小,但能提高给定模型大小下的精度。具体可参考 Layer bumping with llama.cpp。
- 模型格式选择:根据硬件能力和内存限制,选择合适的模型格式,如BF16、F16、Q4_K等。详细信息可参考下面的“选择合适的模型格式”部分。
✨ 主要特性
模型生成特性
- 基于特定版本生成:使用 llama.cpp 的特定提交版本生成模型,确保模型的稳定性和可复现性。
量化特性
- 新量化方法:测试了一种新的量化方法,通过规则提升重要层的量化精度,在低比特量化和MOE模型中表现更优。
- 精度与文件大小平衡:虽然会增加模型文件大小,但能提高给定模型大小下的精度。
多模态特性
- 全模态感知:能够感知文本、图像、音频和视频等多种模态信息。
- 流式响应:以流式方式生成文本和自然语音响应,实现实时交互。
性能特性
- 多模态任务表现出色:在多模态任务中,如OmniBench,表现优于类似规模的单模态模型和闭源模型。
- 单模态任务优秀:在语音识别、翻译、音频理解、图像推理、视频理解和语音生成等单模态任务中也有出色表现。
📚 详细文档
模型生成细节
该模型使用 llama.cpp 在提交版本 1f63e75f 下生成。
量化方法
测试了一种新的量化方法,使用规则提升重要层的量化精度,使其高于标准imatrix的使用。标准IMatrix在低比特量化和MOE模型中表现不佳,因此使用 llama.cpp 的 --tensor-type 选项提升选定层的量化精度。具体可参考 Layer bumping with llama.cpp。这种方法会增加模型文件大小,但能提高给定模型大小下的精度。
选择合适的模型格式
选择正确的模型格式取决于你的硬件能力和内存限制。以下是不同模型格式的详细介绍:
BF16 (Brain Float 16) – 若支持BF16加速则使用
- 特点:一种16位浮点格式,专为快速计算设计,同时保留良好的精度。与FP32具有相似的动态范围,但内存使用更低。
- 适用场景:
- 硬件支持BF16加速(检查设备规格)。
- 希望在节省内存的同时获得更高的精度。
- 计划将模型重新量化为其他格式。
- 避免场景:
- 硬件不支持BF16(可能会回退到FP32并运行较慢)。
- 需要与缺乏BF16优化的旧设备兼容。
F16 (Float 16) – 比BF16更广泛支持
- 特点:一种16位浮点格式,具有高精度,但动态范围比BF16小。适用于大多数支持FP16加速的设备(包括许多GPU和一些CPU)。
- 适用场景:
- 硬件支持FP16但不支持BF16。
- 需要在速度、内存使用和准确性之间取得平衡。
- 在GPU或其他针对FP16计算优化的设备上运行。
- 避免场景:
- 设备缺乏原生FP16支持(可能运行比预期慢)。
- 有内存限制。
混合精度模型 (如 bf16_q8_0, f16_q4_K) – 兼顾两者优点
- 特点:这些格式选择性地量化非关键层,同时保持关键层的全精度(如注意力和输出层)。
- 适用场景:
- 需要比仅量化模型更高的准确性,但无法承受全BF16/F16的内存需求。
- 设备支持混合精度推理。
- 希望在受限硬件上优化生产级模型的权衡。
- 避免场景:
- 目标设备不支持混合或全精度加速。
- 在超严格的内存限制下运行(此时应使用全量化格式)。
量化模型 (Q4_K, Q6_K, Q8, 等) – 用于CPU和低VRAM推理
- 特点:量化可以减小模型大小和内存使用,同时尽可能保持准确性。
- 适用场景:
- 在CPU上运行推理,需要优化的模型。
- 设备具有低VRAM,无法加载全精度模型。
- 希望在保持合理准确性的同时减少内存占用。
- 避免场景:
- 需要最高准确性(全精度模型更适合)。
- 硬件有足够的VRAM用于更高精度的格式(BF16/F16)。
极低比特量化 (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)
- 特点:这些模型针对非常高的内存效率进行了优化,适用于低功耗设备或大规模部署,其中内存是关键限制因素。
- 不同类型介绍:
- IQ3_XS:超低位量化(3位),具有非常高的内存效率。适用于超低内存设备,即使Q4_K也太大的情况。但准确性较低。
- IQ3_S:小块大小,用于最大内存效率。适用于低内存设备,比IQ3_XS更实用。
- IQ3_M:中等块大小,比IQ3_S具有更好的准确性。适用于低内存设备,IQ3_S过于受限的情况。
- Q4_K:4位量化,具有逐块优化,以提高准确性。适用于低内存设备,Q6_K太大的情况。
- Q4_0:纯4位量化,针对ARM设备进行了优化。适用于基于ARM的设备或低内存环境。
超低比特量化 (IQ1_S, IQ1_M, IQ2_S, IQ2_M, IQ2_XS, IQ2_XSS)
- 特点:超低位量化(1 - 2位),具有极高的内存效率。
- 适用场景:适用于必须将模型放入非常受限内存的情况。
- 注意事项:准确性非常低,可能无法按预期工作。使用前请充分测试。
模型格式选择总结表
| 模型格式 | 精度 | 内存使用 | 设备要求 | 最佳使用场景 |
|---|---|---|---|---|
| BF16 | 非常高 | 高 | 支持BF16的GPU/CPU | 高速推理,减少内存使用 |
| F16 | 高 | 高 | 支持FP16的GPU/CPU | 当BF16不可用时进行推理 |
| Q4_K | 中低 | 低 | CPU或低VRAM设备 | 内存受限的推理 |
| Q6_K | 中等 | 适中 | 内存较多的CPU | 量化时获得更好的准确性 |
| Q8_0 | 高 | 适中 | 具有适中VRAM的GPU/CPU | 量化模型中最高的准确性 |
| IQ3_XS | 低 | 非常低 | 超低内存设备 | 最大内存效率,低准确性 |
| IQ3_S | 低 | 非常低 | 低内存设备 | 比IQ3_XS更实用 |
| IQ3_M | 中低 | 低 | 低内存设备 | 比IQ3_S具有更好的准确性 |
| Q4_0 | 低 | 低 | 基于ARM的/嵌入式设备 | Llama.cpp自动优化ARM推理 |
| 超低比特 (IQ1/2_*) | 非常低 | 极低 | 小型边缘/嵌入式设备 | 将模型放入极紧的内存中;低准确性 |
混合 (如 bf16_q8_0) |
中高 | 适中 | 支持混合精度的硬件 | 平衡性能和内存,关键层接近FP准确性 |
模型概述
简介
Qwen2.5-Omni是一个端到端的多模态模型,旨在感知多种模态,包括文本、图像、音频和视频,同时以流式方式生成文本和自然语音响应。
关键特性
- 全模态与新颖架构:提出了Thinker-Talker架构,这是一个端到端的多模态模型,能够感知多种模态,并以流式方式生成文本和自然语音响应。还提出了一种新颖的位置嵌入,名为TMRoPE(时间对齐多模态RoPE),用于同步视频输入与音频的时间戳。
- 实时语音和视频聊天:架构设计用于完全实时交互,支持分块输入和即时输出。
- 自然而强大的语音生成:在语音生成方面优于许多现有的流式和非流式替代方案,表现出卓越的鲁棒性和自然度。
- 跨模态强大性能:在与类似规模的单模态模型和闭源模型(如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro)进行基准测试时,在所有模态上表现出出色的性能。在需要集成多种模态的任务中,如OmniBench,Qwen2.5-Omni达到了最先进的性能。
- 出色的端到端语音指令跟随:Qwen2.5-Omni在端到端语音指令跟随方面的表现与文本输入时的效果相当,如在MMLU和GSM8K等基准测试中得到证明。
模型架构
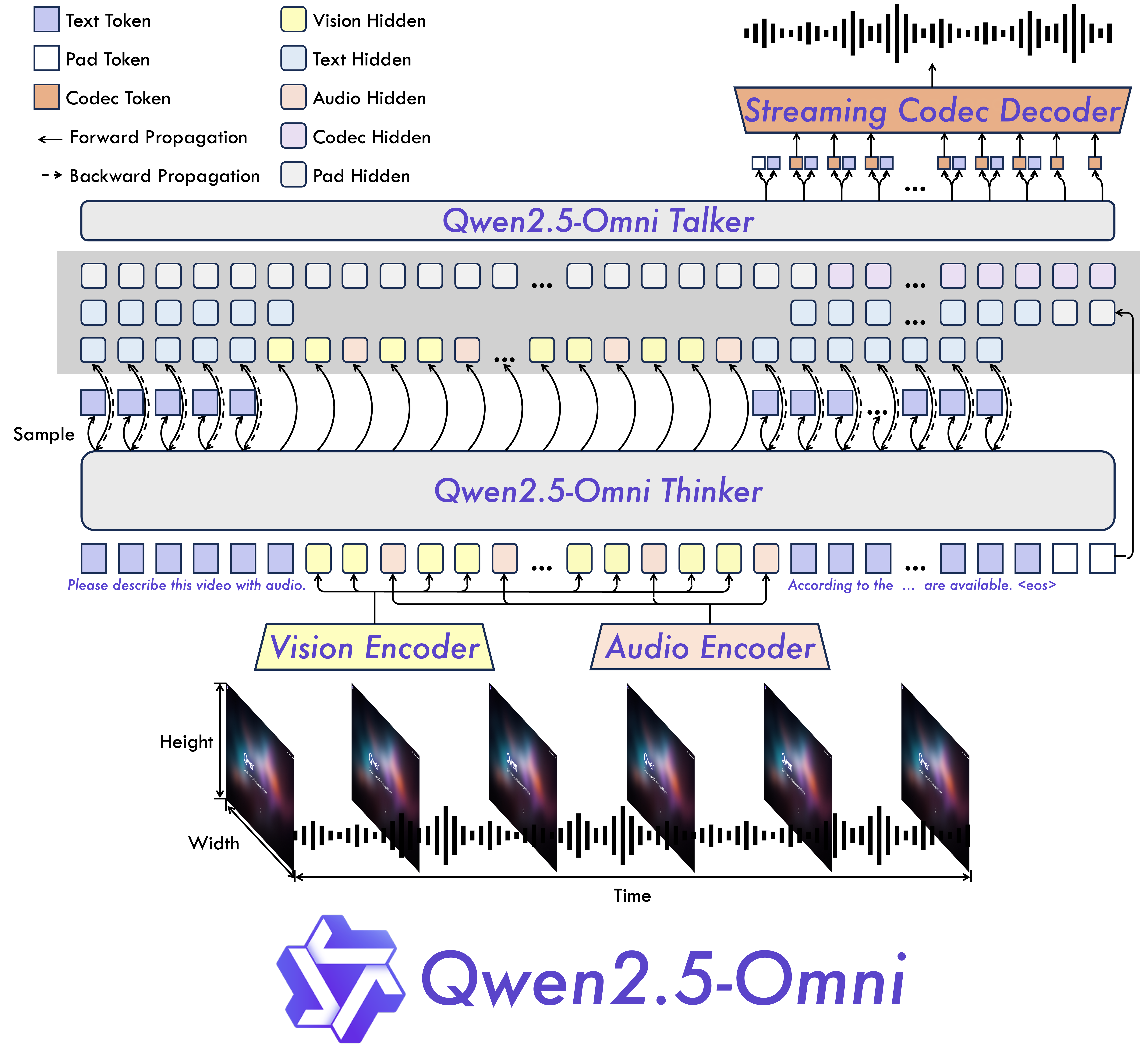
性能
对Qwen2.5-Omni进行了全面评估,与类似规模的单模态模型和闭源模型(如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro)相比,在所有模态上表现出强大的性能。在需要集成多种模态的任务中,如OmniBench,Qwen2.5-Omni达到了最先进的性能。此外,在单模态任务中,它在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)和语音生成(Seed-tts-eval和主观自然度)等领域表现出色。
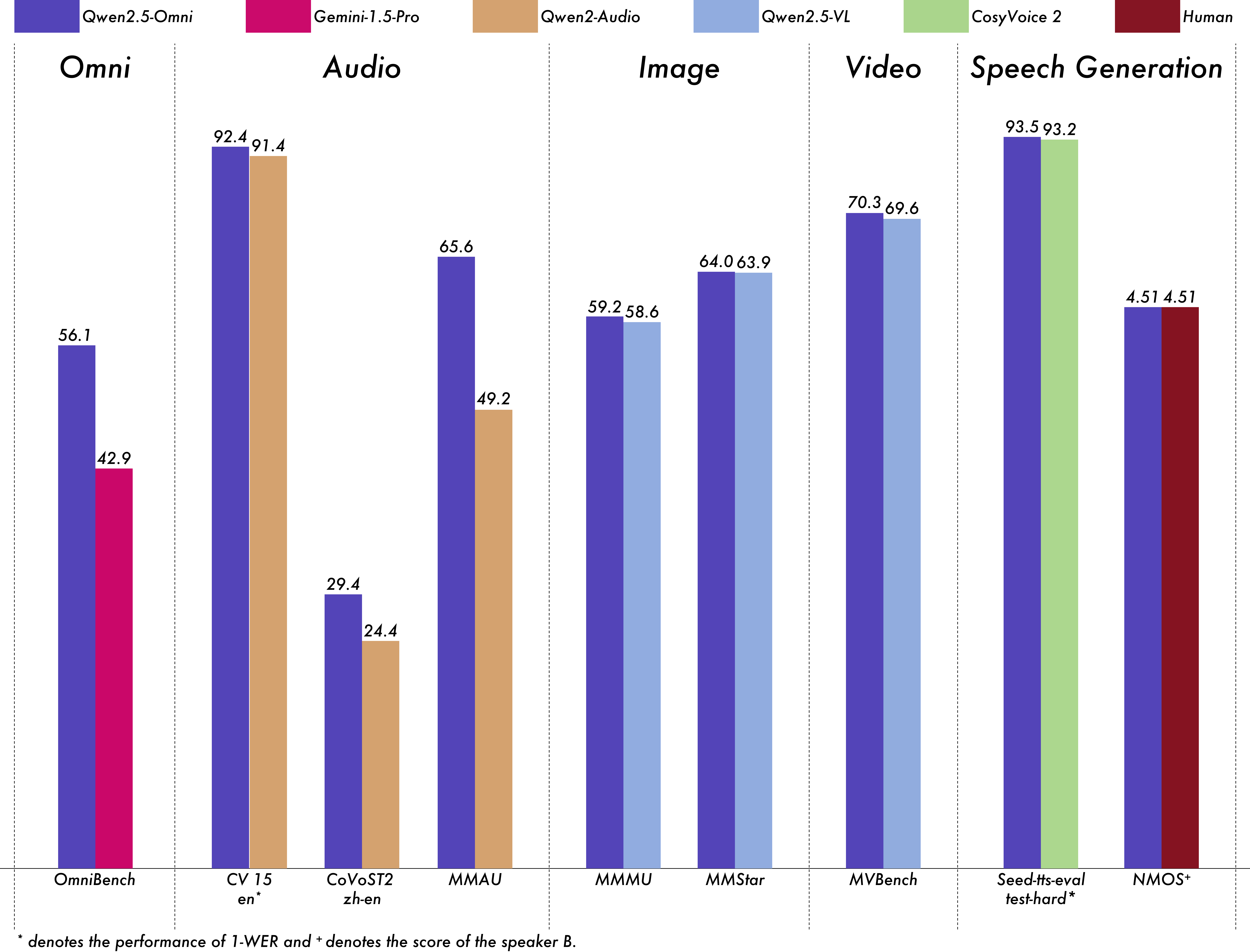
多模态到文本性能
多模态 -> 文本
| 数据集 | 模型 | 性能 |
|---|---|---|
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
Gemini-1.5-Pro | 42.67%|42.26%|46.23%|42.91% |
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
MIO-Instruct | 36.96%|33.58%|11.32%|33.80% |
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
AnyGPT (7B) | 17.77%|20.75%|13.21%|18.04% |
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
video-SALMONN | 34.11%|31.70%|56.60%|35.64% |
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
UnifiedIO2-xlarge | 39.56%|36.98%|29.25%|38.00% |
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
UnifiedIO2-xxlarge | 34.24%|36.98%|24.53%|33.98% |
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
MiniCPM-o | - |
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
Baichuan-Omni-1.5 | - |
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
Qwen2.5-Omni-3B | 52.14%|52.08%|52.83%|52.19% |
| OmniBench 语音 | 声音事件 | 音乐 | 平均 |
Qwen2.5-Omni-7B | 55.25%|60.00%|52.83%|56.13% |
音频到文本性能
音频 -> 文本
| 数据集 | 模型 | 性能 |
|---|---|---|
| ASR | ||
| Librispeech dev-clean | dev other | test-clean | test-other |
SALMONN | - |
| Librispeech dev-clean | dev other | test-clean | test-other |
SpeechVerse | - |
| Librispeech dev-clean | dev other | test-clean | test-other |
Whisper-large-v3 | - |
| Librispeech dev-clean | dev other | test-clean | test-other |
Llama-3-8B | - |
| Librispeech dev-clean | dev other | test-clean | test-other |
Llama-3-70B | - |
| Librispeech dev-clean | dev other | test-clean | test-other |
Seed-ASR-Multilingual | - |
| Librispeech dev-clean | dev other | test-clean | test-other |
MiniCPM-o | - |
| Librispeech dev-clean | dev other | test-clean | test-other |
MinMo | - |
| Librispeech dev-clean | dev other | test-clean | test-other |
Qwen-Audio | 1.8 |
| Librispeech dev-clean | dev other | test-clean | test-other |
Qwen2-Audio | 1.3 |
| Librispeech dev-clean | dev other | test-clean | test-other |
Qwen2.5-Omni-3B | 2.0 |
| Librispeech dev-clean | dev other | test-clean | test-other |
Qwen2.5-Omni-7B | 1.6 |
| Common Voice 15 en | zh | yue | fr |
Whisper-large-v3 | 9.3 |
| Common Voice 15 en | zh | yue | fr |
MinMo | 7.9 |
| Common Voice 15 en | zh | yue | fr |
Qwen2-Audio | 8.6 |
| Common Voice 15 en | zh | yue | fr |
Qwen2.5-Omni-3B | 9.1 |
| Common Voice 15 en | zh | yue | fr |
Qwen2.5-Omni-7B | 7.6 |
| Fleurs zh | en |
Whisper-large-v3 | 7.7 |
| Fleurs zh | en |
Seed-ASR-Multilingual | - |
| Fleurs zh | en |
Megrez-3B-Omni | 10.8 |
| Fleurs zh | en |
MiniCPM-o | 4.4 |
| Fleurs zh | en |
MinMo | 3.0 |
| Fleurs zh | en |
Qwen2-Audio | 7.5 |
| Fleurs zh | en |
Qwen2.5-Omni-3B | 3.2 |
| Fleurs zh | en |
Qwen2.5-Omni-7B | 3.0 |
| Wenetspeech test-net | test-meeting |
Seed-ASR-Chinese | **4.7 |
| Wenetspeech test-net | test-meeting |
Megrez-3B-Omni | - |
| Wenetspeech test-net | test-meeting |
MiniCPM-o | 6.9 |
| Wenetspeech test-net | test-meeting |
MinMo | 6.8 |
| Wenetspeech test-net | test-meeting |
Qwen2.5-Omni-3B | 6.3 |
| Wenetspeech test-net | test-meeting |
Qwen2.5-Omni-7B | 5.9 |
| Voxpopuli-V1.0-en | Llama-3-8B | 6.2 |
| Voxpopuli-V1.0-en | Llama-3-70B | 5.7 |
| Voxpopuli-V1.0-en | Qwen2.5-Omni-3B | 6.6 |
| Voxpopuli-V1.0-en | Qwen2.5-Omni-7B | 5.8 |
| S2TT | ||
| CoVoST2 en-de | de-en | en-zh | zh-en |
SALMONN | 18.6 |
| CoVoST2 en-de | de-en | en-zh | zh-en |
SpeechLLaMA | - |
| CoVoST2 en-de | de-en | en-zh | zh-en |
BLSP | 14.1 |
| CoVoST2 en-de | de-en | en-zh | zh-en |
MiniCPM-o | - |
| CoVoST2 en-de | de-en | en-zh | zh-en |
MinMo | - |
| CoVoST2 en-de | de-en | en-zh | zh-en |
Qwen-Audio | 25.1 |
| CoVoST2 en-de | de-en | en-zh | zh-en |
Qwen2-Audio | 29.9 |
| CoVoST2 en-de | de-en | en-zh | zh-en |
Qwen2.5-Omni-3B | 28.3 |
| CoVoST2 en-de | de-en | en-zh | zh-en |
Qwen2.5-Omni-7B | 30.2 |
| SER | ||
| Meld | WavLM-large | 0.542 |
| Meld | MiniCPM-o | 0.524 |
| Meld | Qwen-Audio | 0.557 |
| Meld | Qwen2-Audio | 0.553 |
| Meld | Qwen2.5-Omni-3B | 0.558 |
| Meld | Qwen2.5-Omni-7B | 0.570 |
| VSC | ||
| VocalSound | CLAP | 0.495 |
| VocalSound | Pengi | 0.604 |
| VocalSound | Qwen-Audio | 0.929 |
| VocalSound | Qwen2-Audio | 0.939 |
| VocalSound | Qwen2.5-Omni-3B | 0.936 |
| VocalSound | Qwen2.5-Omni-7B | 0.939 |
| Music | ||
| GiantSteps Tempo | Llark-7B | 0.86 |
| GiantSteps Tempo | Qwen2.5-Omni-3B | 0.88 |
📄 许可证
本项目采用 Apache-2.0 许可证。
 Safetensors 英语
Safetensors 英语