%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Model Overview
Model Features
Model Capabilities
Use Cases
🚀 Qwen2.5-Omni-7B GGUF Models
Qwen2.5-Omni-7B GGUF models offer a range of quantization methods and formats to suit different hardware capabilities and memory constraints, enabling efficient and high - precision inference across various devices.
🚀 Quick Start
Model Generation Details
This model was generated using llama.cpp at commit 1f63e75f.
Quantization beyond the IMatrix
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use. The standard IMatrix does not perform very well at low - bit quantization and for MOE models. So, llama.cpp --tensor - type is used to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model - converter/tensor_list_builder.py). This creates larger model files but increases precision for a given model size.
💡 Usage Tip
Please provide feedback on how you find this method performs.
Choosing the Right Model Format
Selecting the correct model format depends on your hardware capabilities and memory constraints.
BF16 (Brain Float 16) – Use if BF16 acceleration is available
- A 16 - bit floating - point format designed for faster computation while retaining good precision.
- Provides similar dynamic range as FP32 but with lower memory usage.
- Recommended if your hardware supports BF16 acceleration (check your device's specs).
- Ideal for high - performance inference with reduced memory footprint compared to FP32.
⚠️ Important Note
- Use BF16 if: - Your hardware has native BF16 support (e.g., newer GPUs, TPUs). - You want higher precision while saving memory. - You plan to requantize the model into another format.
- Avoid BF16 if: - Your hardware does not support BF16 (it may fall back to FP32 and run slower). - You need compatibility with older devices that lack BF16 optimization.
F16 (Float 16) – More widely supported than BF16
- A 16 - bit floating - point format with high precision but a smaller range of values than BF16.
- Works on most devices with FP16 acceleration support (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
⚠️ Important Note
- Use F16 if: - Your hardware supports FP16 but not BF16. - You need a balance between speed, memory usage, and accuracy. - You are running on a GPU or another device optimized for FP16 computations.
- Avoid F16 if: - Your device lacks native FP16 support (it may run slower than expected). - You have memory limitations.
Hybrid Precision Models (e.g., bf16_q8_0, f16_q4_K) – Best of Both Worlds
These formats selectively quantize non - essential layers while keeping key layers in full precision (e.g., attention and output layers).
- Named like
bf16_q8_0(meaning full - precision BF16 core layers + quantized Q8_0 other layers). - Strike a balance between memory efficiency and accuracy, improving over fully quantized models without requiring the full memory of BF16/F16.
⚠️ Important Note
- Use Hybrid Models if: - You need better accuracy than quant - only models but can't afford full BF16/F16 everywhere. - Your device supports mixed - precision inference. - You want to optimize trade - offs for production - grade models on constrained hardware.
- Avoid Hybrid Models if: - Your target device doesn't support mixed or full - precision acceleration. - You are operating under ultra - strict memory limits (in which case use fully quantized formats).
Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low - VRAM Inference
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- Lower - bit models (Q4_K) – Best for minimal memory usage, may have lower precision.
- Higher - bit models (Q6_K, Q8_0) – Better accuracy, requires more memory.
⚠️ Important Note
- Use Quantized Models if: - You are running inference on a CPU and need an optimized model. - Your device has low VRAM and cannot load full - precision models. - You want to reduce memory footprint while keeping reasonable accuracy.
- Avoid Quantized Models if: - You need maximum accuracy (full - precision models are better for this). - Your hardware has enough VRAM for higher - precision formats (BF16/F16).
Very Low - Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)
These models are optimized for very high memory efficiency, making them ideal for low - power devices or large - scale deployments where memory is a critical constraint.
- IQ3_XS: Ultra - low - bit quantization (3 - bit) with very high memory efficiency.
- Use case: Best for ultra - low - memory devices where even Q4_K is too large.
- Trade - off: Lower accuracy compared to higher - bit quantizations.
- IQ3_S: Small block size for maximum memory efficiency.
- Use case: Best for low - memory devices where IQ3_XS is too aggressive.
- IQ3_M: Medium block size for better accuracy than IQ3_S.
- Use case: Suitable for low - memory devices where IQ3_S is too limiting.
- Q4_K: 4 - bit quantization with block - wise optimization for better accuracy.
- Use case: Best for low - memory devices where Q6_K is too large.
- Q4_0: Pure 4 - bit quantization, optimized for ARM devices.
- Use case: Best for ARM - based devices or low - memory environments.
Ultra Low - Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)
- Ultra - low - bit quantization (1 - 2 - bit) with extreme memory efficiency.
- Use case: Best for cases where you have to fit the model into very constrained memory.
- Trade - off: Very Low Accuracy. May not function as expected. Please test fully before using.
Summary Table: Model Format Selection
| Property | Details |
|---|---|
| Model Format | Precision |
| BF16 | Very High |
| F16 | High |
| Q4_K | Medium - Low |
| Q6_K | Medium |
| Q8_0 | High |
| IQ3_XS | Low |
| IQ3_S | Low |
| IQ3_M | Low - Medium |
| Q4_0 | Low |
| Ultra Low - Bit (IQ1/2_*) | Very Low |
Hybrid (e.g., bf16_q8_0) |
Medium–High |
✨ Features
Overview
Qwen2.5 - Omni is an end - to - end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner.
Key Features
- Omni and Novel Architecture: We propose Thinker - Talker architecture, an end - to - end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. We propose a novel position embedding, named TMRoPE (Time - aligned Multimodal RoPE), to synchronize the timestamps of video inputs with audio.
- Real - Time Voice and Video Chat: Architecture designed for fully real - time interactions, supporting chunked input and immediate output.
- Natural and Robust Speech Generation: Surpassing many existing streaming and non - streaming alternatives, demonstrating superior robustness and naturalness in speech generation.
- Strong Performance Across Modalities: Exhibiting exceptional performance across all modalities when benchmarked against similarly sized single - modality models. Qwen2.5 - Omni outperforms the similarly sized Qwen2 - Audio in audio capabilities and achieves comparable performance to Qwen2.5 - VL - 7B.
- Excellent End - to - End Speech Instruction Following: Qwen2.5 - Omni shows performance in end - to - end speech instruction following that rivals its effectiveness with text inputs, evidenced by benchmarks such as MMLU and GSM8K.
Model Architecture
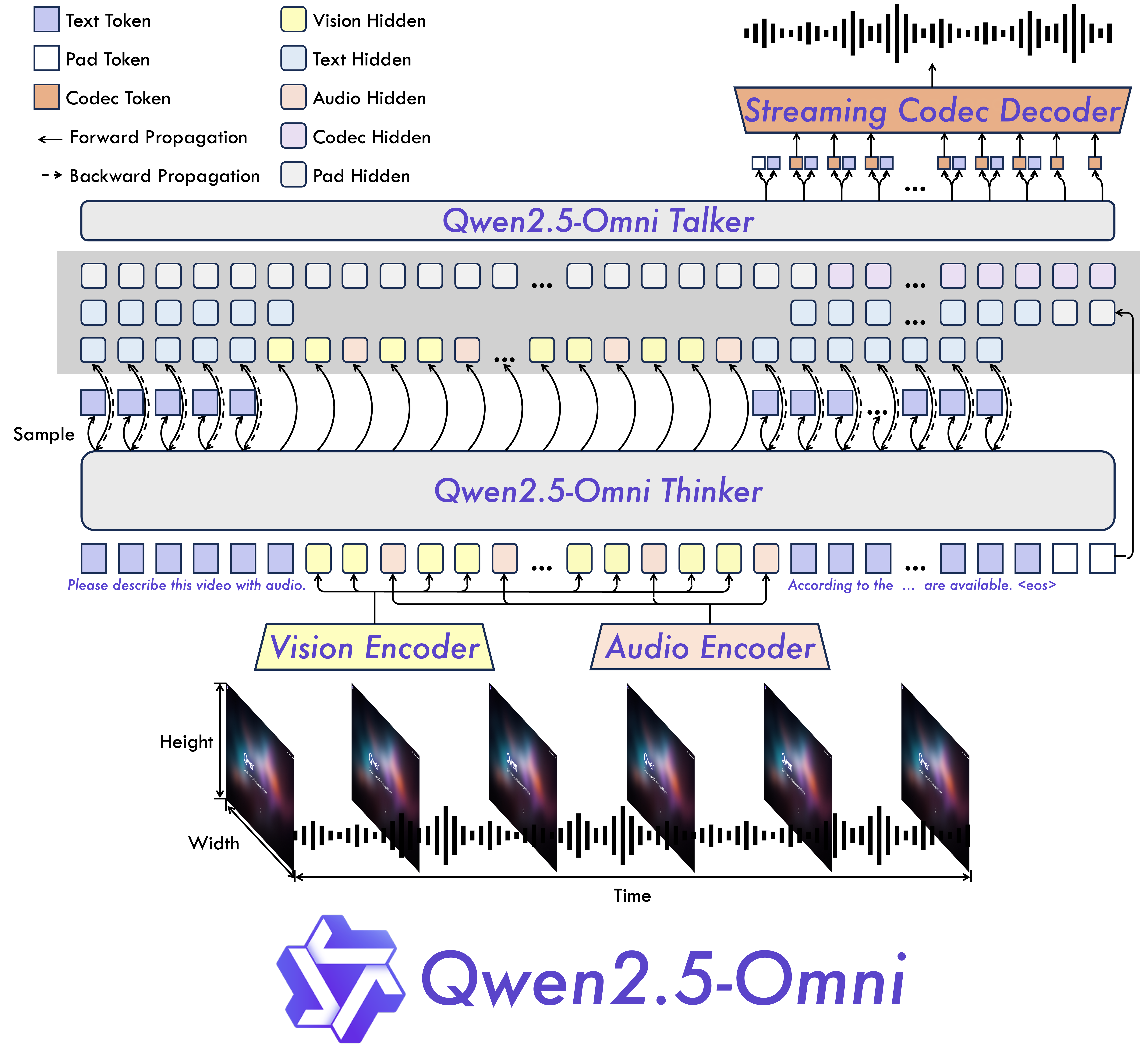
Performance
We conducted a comprehensive evaluation of Qwen2.5 - Omni, which demonstrates strong performance across all modalities when compared to similarly sized single - modality models and closed - source models like Qwen2.5 - VL - 7B, Qwen2 - Audio, and Gemini - 1.5 - pro. In tasks requiring the integration of multiple modalities, such as OmniBench, Qwen2.5 - Omni achieves state - of - the - art performance. Furthermore, in single - modality tasks, it excels in areas including speech recognition (Common Voice), translation (CoVoST2), audio understanding (MMAU), image reasoning (MMMU, MMStar), video understanding (MVBench), and speech generation (Seed - tts - eval and subjective naturalness).
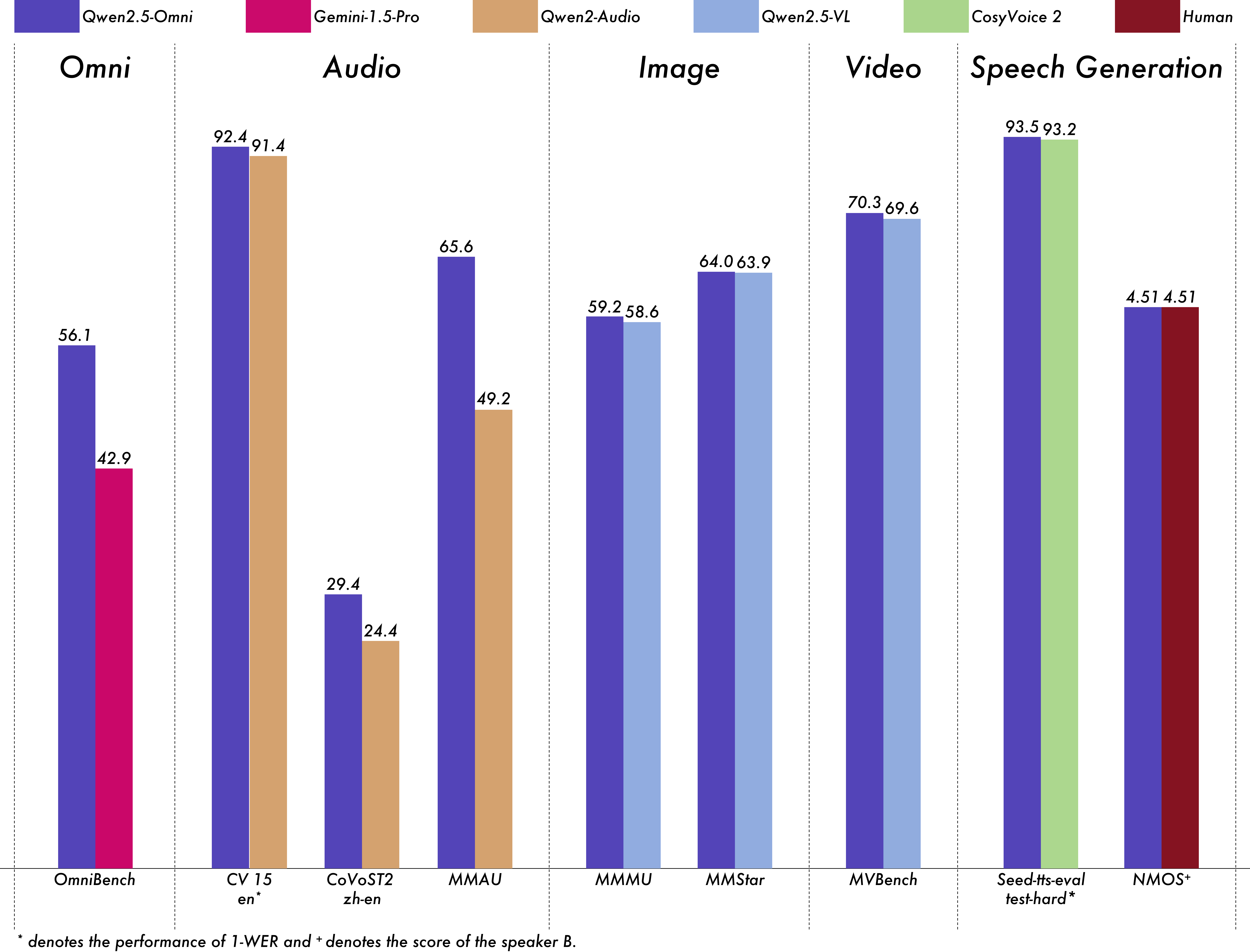
Multimodality -> Text
| Datasets | Model | Performance |
|---|---|---|
| OmniBench Speech | Sound Event | Music | Avg |
Gemini-1.5-Pro | 42.67%|42.26%|46.23%|42.91% |
| MIO-Instruct | 36.96%|33.58%|11.32%|33.80% | |
| AnyGPT (7B) | 17.77%|20.75%|13.21%|18.04% | |
| video-SALMONN | 34.11%|31.70%|56.60%|35.64% | |
| UnifiedIO2-xlarge | 39.56%|36.98%|29.25%|38.00% | |
| UnifiedIO2-xxlarge | 34.24%|36.98%|24.53%|33.98% | |
| MiniCPM-o | -|-|-|40.50% | |
| Baichuan-Omni-1.5 | -|-|-|42.90% | |
| Qwen2.5-Omni-3B | 52.14%|52.08%|52.83%|52.19% | |
| Qwen2.5-Omni-7B | 55.25%|60.00%|52.83%|56.13% |
Audio -> Text
| Datasets | Model | Performance |
|---|---|---|
| ASR | ||
| Librispeech dev-clean | dev other | test-clean | test-other |
SALMONN | -|-|2.1|4.9 |
| SpeechVerse | -|-|2.1|4.4 | |
| Whisper-large-v3 | -|-|1.8|3.6 | |
| Llama-3-8B | -|-|-|3.4 | |
| Llama-3-70B | -|-|-|3.1 | |
| Seed-ASR-Multilingual | -|-|1.6|2.8 | |
| MiniCPM-o | -|-|1.7|- | |
| MinMo | -|-|1.7|3.9 | |
| Qwen-Audio | 1.8|4.0|2.0|4.2 | |
| Qwen2-Audio | 1.3|3.4|1.6|3.6 | |
| Qwen2.5-Omni-3B | 2.0|4.1|2.2|4.5 | |
| Qwen2.5-Omni-7B | 1.6|3.5|1.8|3.4 | |
| Common Voice 15 en | zh | yue | fr |
Whisper-large-v3 | 9.3|12.8|10.9|10.8 |
| MinMo | 7.9|6.3|6.4|8.5 | |
| Qwen2-Audio | 8.6|6.9|5.9|9.6 | |
| Qwen2.5-Omni-3B | 9.1|6.0|11.6|9.6 | |
| Qwen2.5-Omni-7B | 7.6|5.2|7.3|7.5 | |
| Fleurs zh | en |
Whisper-large-v3 | 7.7|4.1 |
| Seed-ASR-Multilingual | -|3.4 | |
| Megrez-3B-Omni | 10.8|- | |
| MiniCPM-o | 4.4|- | |
| MinMo | 3.0|3.8 | |
| Qwen2-Audio | 7.5|- | |
| Qwen2.5-Omni-3B | 3.2|5.4 | |
| Qwen2.5-Omni-7B | 3.0|4.1 | |
| Wenetspeech test-net | test-meeting |
Seed-ASR-Chinese | 4.7|5.7 |
| Megrez-3B-Omni | -|16.4 | |
| MiniCPM-o | 6.9|- | |
| MinMo | 6.8|7.4 | |
| Qwen2.5-Omni-3B | 6.3|8.1 | |
| Qwen2.5-Omni-7B | 5.9|7.7 | |
| Voxpopuli-V1.0-en | Llama-3-8B | 6.2 |
| Llama-3-70B | 5.7 | |
| Qwen2.5-Omni-3B | 6.6 | |
| Qwen2.5-Omni-7B | 5.8 | |
| S2TT | ||
| CoVoST2 en-de | de-en | en-zh | zh-en |
SALMONN | 18.6|-|33.1|- |
| SpeechLLaMA | -|27.1|-|12.3 | |
| BLSP | 14.1|-|-|- | |
| MiniCPM-o | -|-|48.2|27.2 | |
| MinMo | -|39.9|46.7|26.0 | |
| Qwen-Audio | 25.1|33.9|41.5|15.7 | |
| Qwen2-Audio | 29.9|35.2|45.2|24.4 | |
| Qwen2.5-Omni-3B | 28.3|38.1|41.4|26.6 | |
| Qwen2.5-Omni-7B | 30.2|37.7|41.4|29.4 | |
| SER | ||
| Meld | WavLM-large | 0.542 |
| MiniCPM-o | 0.524 | |
| Qwen-Audio | 0.557 | |
| Qwen2-Audio | 0.553 | |
| Qwen2.5-Omni-3B | 0.558 | |
| Qwen2.5-Omni-7B | 0.570 | |
| VSC | ||
| VocalSound | CLAP | 0.495 |
| Pengi | 0.604 | |
| Qwen-Audio | 0.929 | |
| Qwen2-Audio | 0.939 | |
| Qwen2.5-Omni-3B | 0.936 | |
| Qwen2.5-Omni-7B | 0.939 | |
| Music | ||
| GiantSteps Tempo | Llark-7B | 0.86 |
| Qwen2.5-Omni-3B | 0.88 | |
📄 License
This project is licensed under the Apache 2.0 License.
 Safetensors English
Safetensors English