%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型简介
模型特点
模型能力
使用案例
🚀 Qwen2.5-Omni
Qwen2.5-Omni是一个端到端的多模态模型,能够感知文本、图像、音频和视频等多种模态信息,并以流式方式同时生成文本和自然语音响应。
🚀 快速开始
我们提供了简单的示例,展示如何使用🤗 Transformers库来使用Qwen2.5-Omni。Qwen2.5-Omni的代码已集成在最新的Hugging face transformers库中,建议你使用以下命令从源代码进行构建:
pip uninstall transformers
pip install git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview
pip install accelerate
否则,你可能会遇到以下错误:
KeyError: 'qwen2_5_omni'
我们还提供了一个工具包,帮助你更方便地处理各种类型的音频和视觉输入,就像使用API一样。这包括base64编码、URL和交错的音频、图像和视频。你可以使用以下命令安装它,并确保你的系统已经安装了ffmpeg:
# 强烈建议使用 `[decord]` 特性以加快视频加载速度
pip install qwen-omni-utils[decord] -U
如果你不使用Linux系统,可能无法从PyPI安装decord。在这种情况下,你可以使用pip install qwen-omni-utils -U,它将回退到使用torchvision进行视频处理。不过,你仍然可以从源代码安装decord,以便在加载视频时使用decord。
🤗 Transformers使用方法
以下是一个代码片段,展示如何使用transformers和qwen_omni_utils库来使用聊天模型:
import soundfile as sf
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# 默认:将模型加载到可用的设备上
model = Qwen2_5OmniForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
# 建议启用 flash_attention_2 以获得更好的加速和内存节省效果
# model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-Omni-7B",
# torch_dtype="auto",
# device_map="auto",
# attn_implementation="flash_attention_2",
# )
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
conversation = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# 设置是否使用视频中的音频
USE_AUDIO_IN_VIDEO = True
# 推理前的准备工作
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# 推理:生成输出文本和音频
text_ids, audio = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
最小GPU内存要求
| 模型 | 精度 | 15秒视频 | 30秒视频 | 60秒视频 |
|---|---|---|---|---|
| Qwen-Omni-3B | FP32 | 89.10 GB | 不推荐 | 不推荐 |
| Qwen-Omni-3B | BF16 | 18.38 GB | 22.43 GB | 28.22 GB |
| Qwen-Omni-7B | FP32 | 93.56 GB | 不推荐 | 不推荐 |
| Qwen-Omni-7B | BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
注意:上表展示了使用transformers进行推理的理论最小内存要求,并且BF16是在attn_implementation="flash_attention_2"的情况下进行测试的;然而,在实际应用中,实际内存使用量通常至少是理论值的1.2倍。更多信息,请参阅此处链接资源。
视频URL资源使用情况
视频URL的兼容性在很大程度上取决于第三方库的版本。具体细节如下表所示。如果你不想使用默认的后端,可以通过FORCE_QWENVL_VIDEO_READER=torchvision或FORCE_QWENVL_VIDEO_READER=decord来更改后端。
| 后端 | HTTP | HTTPS |
|---|---|---|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
批量推理
当设置return_audio=False时,模型可以将由文本、图像、音频和视频等各种类型的混合样本组成的输入进行批量处理。以下是一个示例:
# 批量推理的示例消息
# 仅包含视频的对话
conversation1 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "/path/to/video.mp4"},
]
}
]
# 仅包含音频的对话
conversation2 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "audio", "audio": "/path/to/audio.wav"},
]
}
]
# 纯文本对话
conversation3 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": "who are you?"
}
]
# 包含多种媒体的对话
conversation4 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/image.jpg"},
{"type": "video", "video": "/path/to/video.mp4"},
{"type": "audio", "audio": "/path/to/audio.wav"},
{"type": "text", "text": "What are the elements can you see and hear in these medias?"},
],
}
]
# 合并消息以进行批量处理
conversations = [conversation1, conversation2, conversation3, conversation4]
# 设置是否使用视频中的音频
USE_AUDIO_IN_VIDEO = True
# 批量推理前的准备工作
text = processor.apply_chat_template(conversations, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversations, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# 批量推理
text_ids = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO, return_audio=False)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
使用提示
音频输出提示
如果用户需要音频输出,系统提示必须设置为 "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",否则音频输出可能无法正常工作。
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
}
使用视频中的音频
在多模态交互过程中,用户提供的视频通常会附带音频(例如关于视频内容的问题,或视频中某些事件产生的声音)。这些信息有助于模型提供更好的交互体验。因此,我们为用户提供了以下选项,以决定是否使用视频中的音频:
# 第一个位置,数据预处理阶段
audios, images, videos = process_mm_info(conversations, use_audio_in_video=True)
# 第二个位置,模型处理器阶段
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt",
padding=True, use_audio_in_video=True)
# 第三个位置,模型推理阶段
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
值得注意的是,在多轮对话中,这些位置的use_audio_in_video参数必须设置为相同的值,否则可能会出现意外结果。
是否使用音频输出
模型支持文本和音频输出。如果用户不需要音频输出,可以在初始化模型后调用model.disable_talker()。此选项将节省约~2GB的GPU内存,但generate函数的return_audio选项将只能设置为False。
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
model.disable_talker()
为了获得更灵活的体验,我们建议用户在调用generate函数时决定是否返回音频。如果将return_audio设置为False,模型将仅返回文本输出,从而更快地获得文本响应。
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
...
text_ids = model.generate(**inputs, return_audio=False)
更改输出音频的语音类型
Qwen2.5-Omni支持更改输出音频的语音类型。"Qwen/Qwen2.5-Omni-7B"检查点支持以下两种语音类型:
| 语音类型 | 性别 | 描述 |
|---|---|---|
| Chelsie | 女性 | 一种甜美的、天鹅绒般的声音,带有温柔的温暖和明亮的清晰度。 |
| Ethan | 男性 | 一种明亮、乐观的声音,充满感染力和温暖、亲切的氛围。 |
用户可以使用generate函数的speaker参数来指定语音类型。默认情况下,如果未指定speaker,则默认语音类型为Chelsie。
text_ids, audio = model.generate(**inputs, speaker="Chelsie")
text_ids, audio = model.generate(**inputs, speaker="Ethan")
使用Flash-Attention 2加速生成
首先,确保安装最新版本的Flash Attention 2:
pip install -U flash-attn --no-build-isolation
此外,你的硬件应与FlashAttention 2兼容。更多信息请参阅flash attention仓库的官方文档。FlashAttention-2只能在模型以torch.float16或torch.bfloat16加载时使用。
要使用FlashAttention-2加载和运行模型,请在加载模型时添加attn_implementation="flash_attention_2":
from transformers import Qwen2_5OmniForConditionalGeneration
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
device_map="auto",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
✨ 主要特性
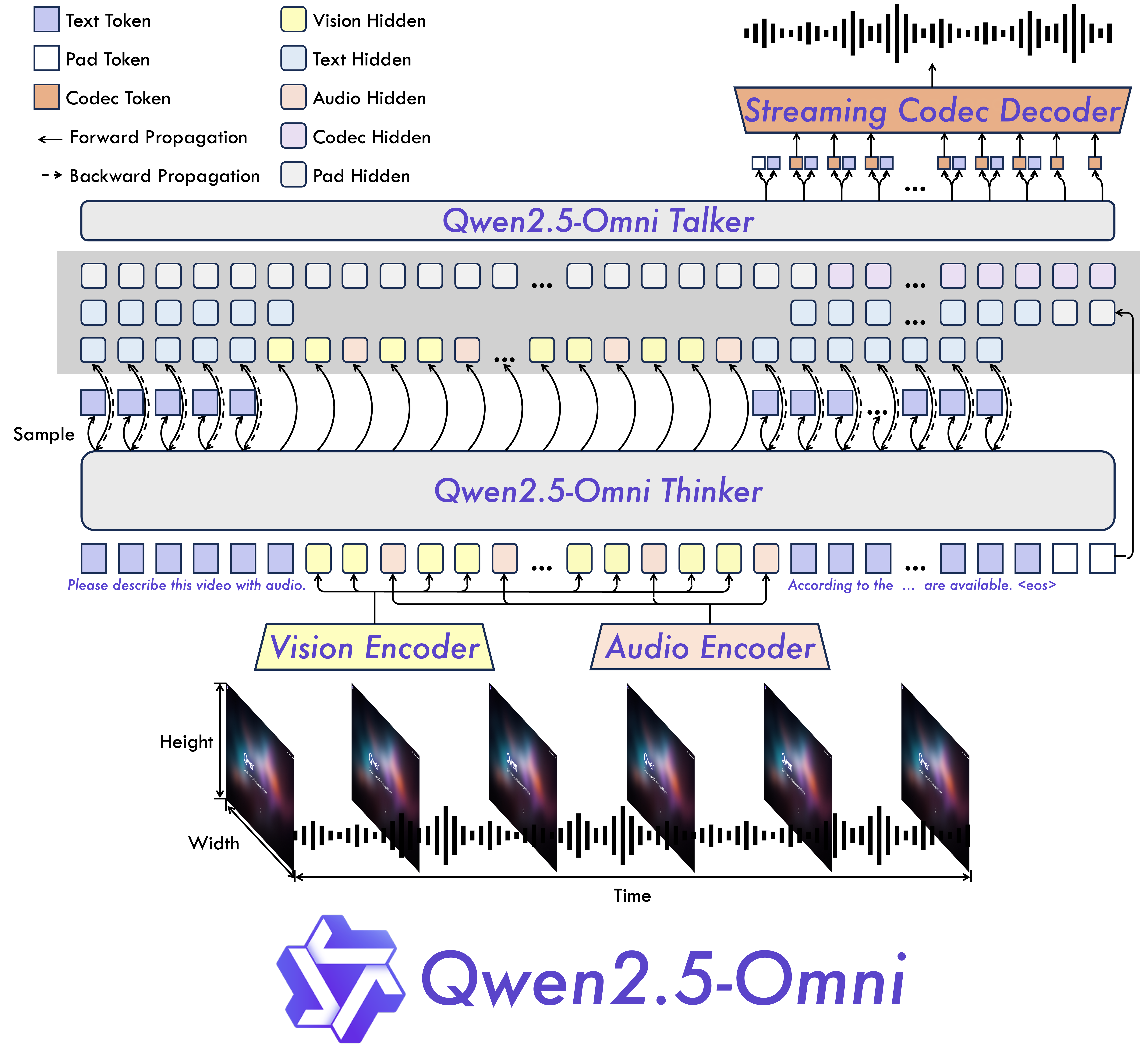
- 全模态与新颖架构:我们提出了Thinker-Talker架构,这是一种端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态信息,同时以流式方式生成文本和自然语音响应。我们还提出了一种新颖的位置嵌入方法,名为TMRoPE(时间对齐的多模态RoPE),用于同步视频输入与音频的时间戳。
- 实时语音和视频聊天:该架构专为全实时交互而设计,支持分块输入和即时输出。
- 自然且鲁棒的语音生成:在语音生成方面,超越了许多现有的流式和非流式替代方案,展现出卓越的鲁棒性和自然度。
- 跨模态的强大性能:与同等规模的单模态模型相比,Qwen2.5-Omni在所有模态上均表现出色。在音频能力方面,Qwen2.5-Omni优于同等规模的Qwen2-Audio,并且在性能上与Qwen2.5-VL-7B相当。
- 出色的端到端语音指令遵循能力:Qwen2.5-Omni在端到端语音指令遵循方面的表现与其在文本输入时的效果相当,这在MMLU和GSM8K等基准测试中得到了证明。
模型架构
性能
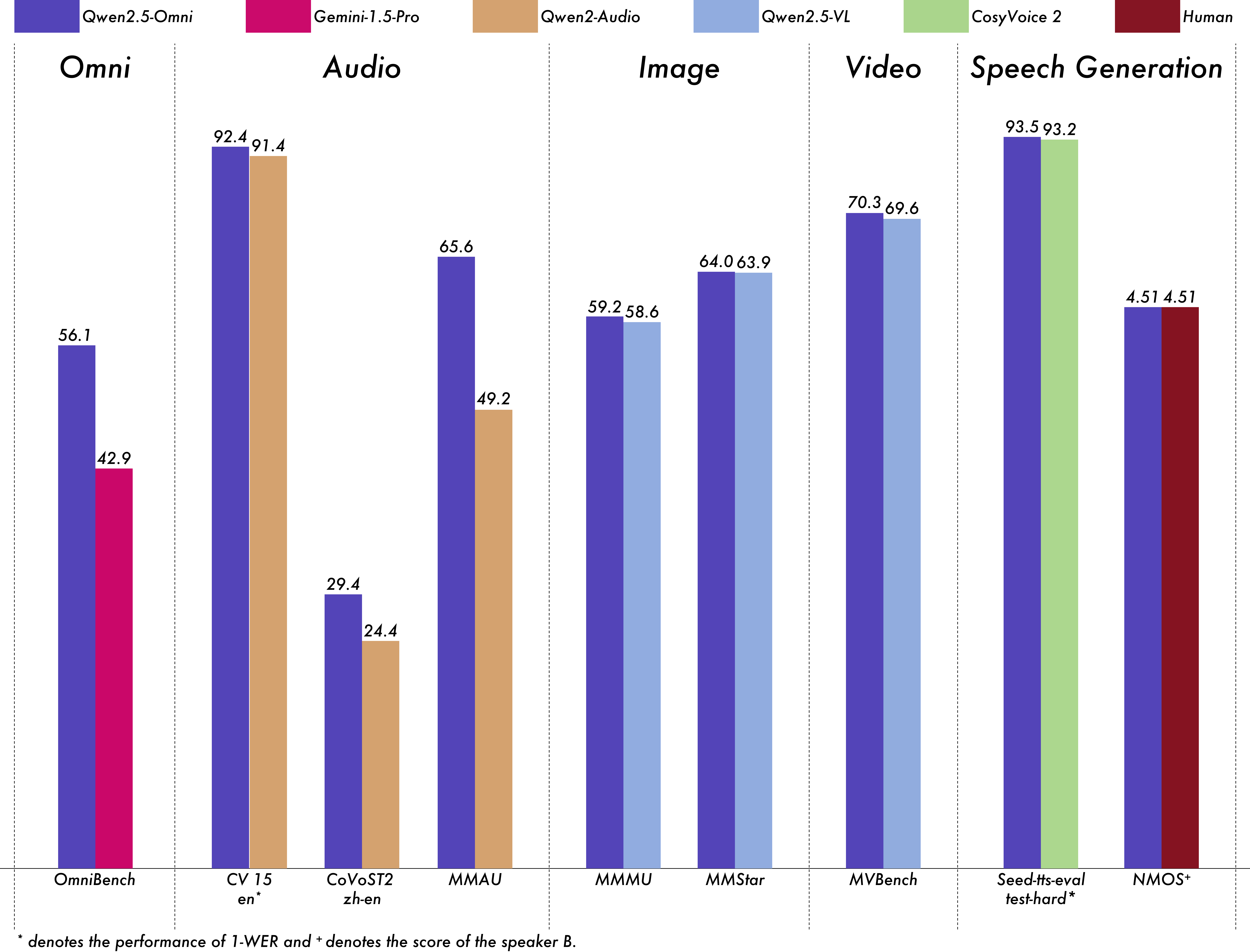
我们对Qwen2.5-Omni进行了全面评估,结果表明,与同等规模的单模态模型和闭源模型(如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro)相比,Qwen2.5-Omni在所有模态上均表现出强大的性能。在需要整合多种模态的任务中,如OmniBench,Qwen2.5-Omni取得了最先进的性能。此外,在单模态任务中,它在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)和语音生成(Seed-tts-eval和主观自然度)等方面表现出色。
多模态 -> 文本
数据集
模型
性能
OmniBench
语音 | 声音事件 | 音乐 | 平均Gemini-1.5-Pro
42.67% | 42.26% | 46.23% | 42.91%
MIO-Instruct
36.96% | 33.58% | 11.32% | 33.80%
AnyGPT (7B)
17.77% | 20.75% | 13.21% | 18.04%
video-SALMONN
34.11% | 31.70% | 56.60% | 35.64%
UnifiedIO2-xlarge
39.56% | 36.98% | 29.25% | 38.00%
UnifiedIO2-xxlarge
34.24% | 36.98% | 24.53% | 33.98%
MiniCPM-o
- | - | - | 40.50%
Baichuan-Omni-1.5
- | - | - | 42.90%
Qwen2.5-Omni-3B
52.14% | 52.08% | 52.83% | 52.19%
Qwen2.5-Omni-7B
55.25% | 60.00% | 52.83% | 56.13%
音频 -> 文本
数据集
模型
性能
自动语音识别(ASR)
Librispeech
dev-clean | dev other | test-clean | test-otherSALMONN
- | - | 2.1 | 4.9
SpeechVerse
- | - | 2.1 | 4.4
Whisper-large-v3
- | - | 1.8 | 3.6
Llama-3-8B
- | - | - | 3.4
Llama-3-70B
- | - | - | 3.1
Seed-ASR-Multilingual
- | - | 1.6 | 2.8
MiniCPM-o
- | - | 1.7 | -
MinMo
- | - | 1.7 | 3.9
Qwen-Audio
1.8 | 4.0 | 2.0 | 4.2
Qwen2-Audio
1.3 | 3.4 | 1.6 | 3.6
Qwen2.5-Omni-3B
2.0 | 4.1 | 2.2 | 4.5
Qwen2.5-Omni-7B
1.6 | 3.5 | 1.8 | 3.4
Common Voice 15
en | zh | yue | frWhisper-large-v3
9.3 | 12.8 | 10.9 | 10.8
MinMo
7.9 | 6.3 | 6.4 | 8.5
Qwen2-Audio
8.6 | 6.9 | 5.9 | 9.6
Qwen2.5-Omni-3B
9.1 | 6.0 | 11.6 | 9.6
Qwen2.5-Omni-7B
7.6 | 5.2 | 7.3 | 7.5
Fleurs
zh | enWhisper-large-v3
7.7 | 4.1
Seed-ASR-Multilingual
- | 3.4
Megrez-3B-Omni
10.8 | -
MiniCPM-o
4.4 | -
MinMo
3.0 | 3.8
Qwen2-Audio
7.5 | -
Qwen2.5-Omni-3B
3.2 | 5.4
Qwen2.5-Omni-7B
3.0 | 4.1
Wenetspeech
test-net | test-meetingSeed-ASR-Chinese
4.7 | 5.7
Megrez-3B-Omni
- | 16.4
MiniCPM-o
6.9 | -
MinMo
6.8 | 7.4
Qwen2.5-Omni-3B
6.3 | 8.1
Qwen2.5-Omni-7B
5.9 | 7.7
Voxpopuli-V1.0-en
Llama-3-8B
6.2
Llama-3-70B
5.7
Qwen2.5-Omni-3B
6.6
Qwen2.5-Omni-7B
5.8
语音到文本翻译(S2TT)
CoVoST2
en-de | de-en | en-zh | zh-enSALMONN
18.6 | - | 33.1 | -
SpeechLLaMA
- | 27.1 | - | 12.3
BLSP
14.1 | - | - | -
MiniCPM-o
- | - | 48.2 | 27.2
MinMo
- | 39.9 | 46.7 | 26.0
Qwen-Audio
25.1 | 33.9 | 41.5 | 15.7
Qwen2-Audio
29.9 | 35.2 | 45.2 | 24.4
Qwen2.5-Omni-3B
28.3 | 38.1 | 41.4 | 26.6
Qwen2.5-Omni-7B
30.2 | 37.7 | 41.4 | 29.4
语音情感识别(SER)
Meld
WavLM-large
0.542
MiniCPM-o
0.524
Qwen-Audio
0.557
Qwen2-Audio
0.553
Qwen2.5-Omni-3B
0.558
Qwen2.5-Omni-7B
0.570
语音声音分类(VSC)
VocalSound
CLAP
0.495
Pengi
0.604
Qwen-Audio
0.929
Qwen2-Audio
0.939
Qwen2.5-Omni-3B
0.936
Qwen2.5-Omni-7B
0.939
音乐相关任务
GiantSteps Tempo
Llark-7B
0.86
Qwen2.5-Omni-3B
0.88
Qwen2.5-Omni-7B
0.88
MusicCaps
LP-MusicCaps
0.291 | 0.149 | 0.089 | 0.061 | 0.129 | 0.130
Qwen2.5-Omni-3B
0.325 | 0.163 | 0.093 | 0.057 | 0.132 | 0.229
Qwen2.5-Omni-7B
0.328 | 0.162 | 0.090 | 0.055 | 0.127 | 0.225
音频推理
MMAU
声音 | 音乐 | 语音 | 平均Gemini-Pro-V1.5
56.75 | 49.40 | 58.55 | 54.90
Qwen2-Audio
54.95 | 50.98 | 42.04 | 49.20
Qwen2.5-Omni-3B
70.27 | 60.48 | 59.16 | 63.30
Qwen2.5-Omni-7B
67.87 | 69.16 | 59.76 | 65.60
语音聊天
VoiceBench
AlpacaEval | CommonEval | SD-QA | MMSUUltravox-v0.4.1-LLaMA-3.1-8B
4.55 | 3.90 | 53.35 | 47.17
MERaLiON
4.50 | 3.77 | 55.06 | 34.95
Megrez-3B-Omni
3.50 | 2.95 | 25.95 | 27.03
Lyra-Base
3.85 | 3.50 | 38.25 | 49.74
MiniCPM-o
4.42 | 4.15 | 50.72 | 54.78
Baichuan-Omni-1.5
4.50 | 4.05 | 43.40 | 57.25
Qwen2-Audio
3.74 | 3.43 | 35.71 | 35.72
Qwen2.5-Omni-3B
4.32 | 4.00 | 49.37 | 50.23
Qwen2.5-Omni-7B
4.49 | 3.93 | 55.71 | 61.32
VoiceBench
OpenBookQA | IFEval | AdvBench | 平均Ultravox-v0.4.1-LLaMA-3.1-8B
65.27 | 66.88 | 98.46 | 71.45
MERaLiON
27.23 | 62.93 | 94.81 | 62.91
Megrez-3B-Omni
28.35 | 25.71 | 87.69 | 46.25
Lyra-Base
72.75 | 36.28 | 59.62 | 57.66
MiniCPM-o
78.02 | 49.25 | 97.69 | 71.69
Baichuan-Omni-1.5
74.51 | 54.54 | 97.31 | 71.14
Qwen2-Audio
49.45 | 26.33 | 96.73 | 55.35
Qwen2.5-Omni-3B
74.73 | 42.10 | 98.85 | 68.81
Qwen2.5-Omni-7B
81.10 | 52.87 | 99.42 | 74.12
图像 -> 文本
数据集
Qwen2.5-Omni-7B
Qwen2.5-Omni-3B
其他最佳
Qwen2.5-VL-7B
GPT-4o-mini
MMMUval
59.2
53.1
53.9
58.6
60.0
MMMU-Prooverall
36.6
29.7
-
38.3
37.6
MathVistatestmini
67.9
59.4
71.9
68.2
52.5
MathVisionfull
25.0
20.8
23.1
25.1
-
MMBench-V1.1-ENtest
81.8
77.8
80.5
82.6
76.0
MMVetturbo
66.8
62.1
67.5
67.1
66.9
MMStar
64.0
55.7
64.0
63.9
54.8
MMEsum
2340
2117
2372
2347
2003
MuirBench
59.2
48.0
-
59.2
-
CRPErelation
76.5
73.7
-
76.4
-
RealWorldQAavg
70.3
62.6
71.9
68.5
-
MME-RealWorlden
61.6
55.6
-
57.4
-
MM-MT-Bench
6.0
5.0
-
6.3
-
AI2D
83.2
79.5
85.8
83.9
-
TextVQAval
84.4
79.8
83.2
84.9
-
DocVQAtest
95.2
93.3
93.5
95.7
-
ChartQAtest Avg
85.3
82.8
84.9
87.3
-
OCRBench_V2en
57.8
51.7
-
56.3
-
数据集
Qwen2.5-Omni-7B
Qwen2.5-Omni-3B
Qwen2.5-VL-7B
Grounding DINO
Gemini 1.5 Pro
Refcocoval
90.5
88.7
90.0
90.6
73.2
RefcocotextA
93.5
91.8
92.5
93.2
72.9
RefcocotextB
86.6
84.0
85.4
88.2
74.6
Refcoco+val
85.4
81.1
84.2
88.2
62.5
Refcoco+textA
91.0
87.5
89.1
89.0
63.9
Refcoco+textB
79.3
73.2
76.9
75.9
65.0
Refcocog+val
87.4
85.0
87.2
86.1
75.2
Refcocog+test
87.9
85.1
87.2
87.0
76.2
ODinW
42.4
39.2
37.3
55.0
36.7
PointGrounding
66.5
46.2
67.3
-
-
视频(无音频) -> 文本
数据集
Qwen2.5-Omni-7B
Qwen2.5-Omni-3B
其他最佳
Qwen2.5-VL-7B
GPT-4o-mini
Video-MMEw/o sub
64.3
62.0
63.9
65.1
64.8
Video-MMEw sub
72.4
68.6
67.9
71.6
-
MVBench
70.3
68.7
67.2
69.6
-
EgoSchematest
68.6
61.4
63.2
65.0
-
零样本语音生成
数据集
模型
性能
内容一致性
SEED
test-zh | test-en | test-hardSeed-TTS_ICL
1.11 | 2.24 | 7.58
Seed-TTS_RL
1.00 | 1.94 | 6.42
MaskGCT
2.27 | 2.62 | 10.27
E2_TTS
1.97 | 2.19 | -
F5-TTS
1.56 | 1.83 | 8.67
CosyVoice 2
1.45 | 2.57 | 6.83
CosyVoice 2-S
1.45 | 2.38 | 8.08
Qwen2.5-Omni-3B_ICL
1.95 | 2.87 | 9.92
Qwen2.5-Omni-3B_RL
1.58 | 2.51 | 7.86
Qwen2.5-Omni-7B_ICL
1.70 | 2.72 | 7.97
Qwen2.5-Omni-7B_RL
1.42 | 2.32 | 6.54
说话人相似度
SEED
test-zh | test-en | test-hardSeed-TTS_ICL
0.796 | 0.762 | 0.776
Seed-TTS_RL
0.801 | 0.766 | 0.782
MaskGCT
0.774 | 0.714 | 0.748
E2_TTS
0.730 | 0.710 | -
F5-TTS
0.741 | 0.647 | 0.713
CosyVoice 2
0.748 | 0.652 | 0.724
CosyVoice 2-S
0.753 | 0.654 | 0.732
Qwen2.5-Omni-3B_ICL
0.741 | 0.635 | 0.748
Qwen2.5-Omni-3B_RL
0.744 | 0.635 | 0.746
Qwen2.5-Omni-7B_ICL
0.752 | 0.632 | 0.747
Qwen2.5-Omni-7B_RL
0.754 | 0.641 | 0.752
文本 -> 文本
数据集
Qwen2.5-Omni-7B
Qwen2.5-Omni-3B
Qwen2.5-7B
Qwen2.5-3B
Qwen2-7B
Llama3.1-8B
Gemma2-9B
MMLU-Pro
47.0
40.4
56.3
43.7
44.1
48.3
52.1
MMLU-redux
71.0
60.9
75.4
64.4
67.3
67.2
72.8
LiveBench0831
29.6
22.3
35.9
26.8
29.2
26.7
30.6
GPQA
30.8
34.3
36.4
30.3
34.3
32.8
32.8
MATH
71.5
63.6
75.5
65.9
52.9
51.9
44.3
GSM8K
88.7
82.6
91.6
86.7
85.7
84.5
76.7
HumanEval
78.7
70.7
84.8
74.4
79.9
72.6
68.9
MBPP
73.2
70.4
79.2
72.7
67.2
69.6
74.9
MultiPL-E
65.8
57.6
70.4
60.2
59.1
50.7
53.4
LiveCodeBench2305-2409
24.6
16.5
28.7
19.9
23.9
8.3
18.9
📚 详细文档
概述
介绍
Qwen2.5-Omni是一个端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态信息,同时以流式方式生成文本和自然语音响应。
关键特性
- 全模态与新颖架构:提出了Thinker-Talker架构,这是一种端到端的多模态模型,能够感知多种模态信息并生成相应响应。还提出了TMRoPE(时间对齐的多模态RoPE)位置嵌入方法,用于同步视频输入与音频的时间戳。
- 实时语音和视频聊天:架构支持全实时交互,允许分块输入和即时输出。
- 自然且鲁棒的语音生成:在语音生成方面表现出色,超越了许多现有模型,具有更好的鲁棒性和自然度。
- 跨模态的强大性能:与同等规模的单模态模型相比,在所有模态上均表现优异。在音频能力上优于Qwen2-Audio,与Qwen2.5-VL-7B相当。
- 出色的端到端语音指令遵循能力:在端到端语音指令遵循任务中表现出色,与文本输入时的效果相当,这在MMLU和GSM8K等基准测试中得到了验证。
模型架构
性能
对Qwen2.5-Omni进行了全面评估,结果显示,与同等规模的单模态模型和闭源模型(如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro)相比,它在所有模态上均表现出色。在需要整合多种模态的任务中,如OmniBench,取得了最先进的性能。在单模态任务中,如语音识别、翻译、音频理解、图像推理、视频理解和语音生成等方面也表现优异。
🔧 技术细节
模型架构
我们提出了Thinker-Talker架构,这是一种端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态信息,同时以流式方式生成文本和自然语音响应。我们还提出了一种新颖的位置嵌入方法,名为TMRoPE(时间对齐的多模态RoPE),用于同步视频输入与音频的时间戳。
实时交互
该架构专为全实时交互而设计,支持分块输入和即时输出,从而实现实时语音和视频聊天。
语音生成
Qwen2.5-Omni在语音生成方面表现出色,超越了许多现有的流式和非流式替代方案,展现出卓越的鲁棒性和自然度。
跨模态性能
与同等规模的单模态模型相比,Qwen2.5-Omni在所有模态上均表现出色。在音频能力方面,它优于同等规模的Qwen2-Audio,并且在性能上与Qwen2.5-VL-7B相当。
端到端语音指令遵循
Qwen2.5-Omni在端到端语音指令遵循方面的表现与其在文本输入时的效果相当,这在MMLU和GSM8K等基准测试中得到了证明。
📄 许可证
本项目采用Apache 2.0许可证,详情请见此处。
引用
如果您发现我们的论文和代码对您的研究有帮助,请考虑给我们一个星标 :star: 并进行引用 :pencil: :)
@article{Qwen2.5-Omni,
title={Qwen2.5-Omni Technical Report},
author={Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, Junyang Lin},
journal={arXiv preprint arXiv:2503.20215},
year={2025}
}
 Safetensors 英语
Safetensors 英语