license: other
license_name: qwen-research
license_link: LICENSE
language:
- en
tags:
- multimodal
library_name: transformers
pipeline_tag: any-to-any
Qwen2.5-Omni

概要
紹介
Qwen2.5-Omniは、テキスト、画像、音声、動画など多様なモダリティを認識し、同時にテキストと自然な音声応答をストリーミング方式で生成するエンドツーエンドのマルチモーダルモデルです。
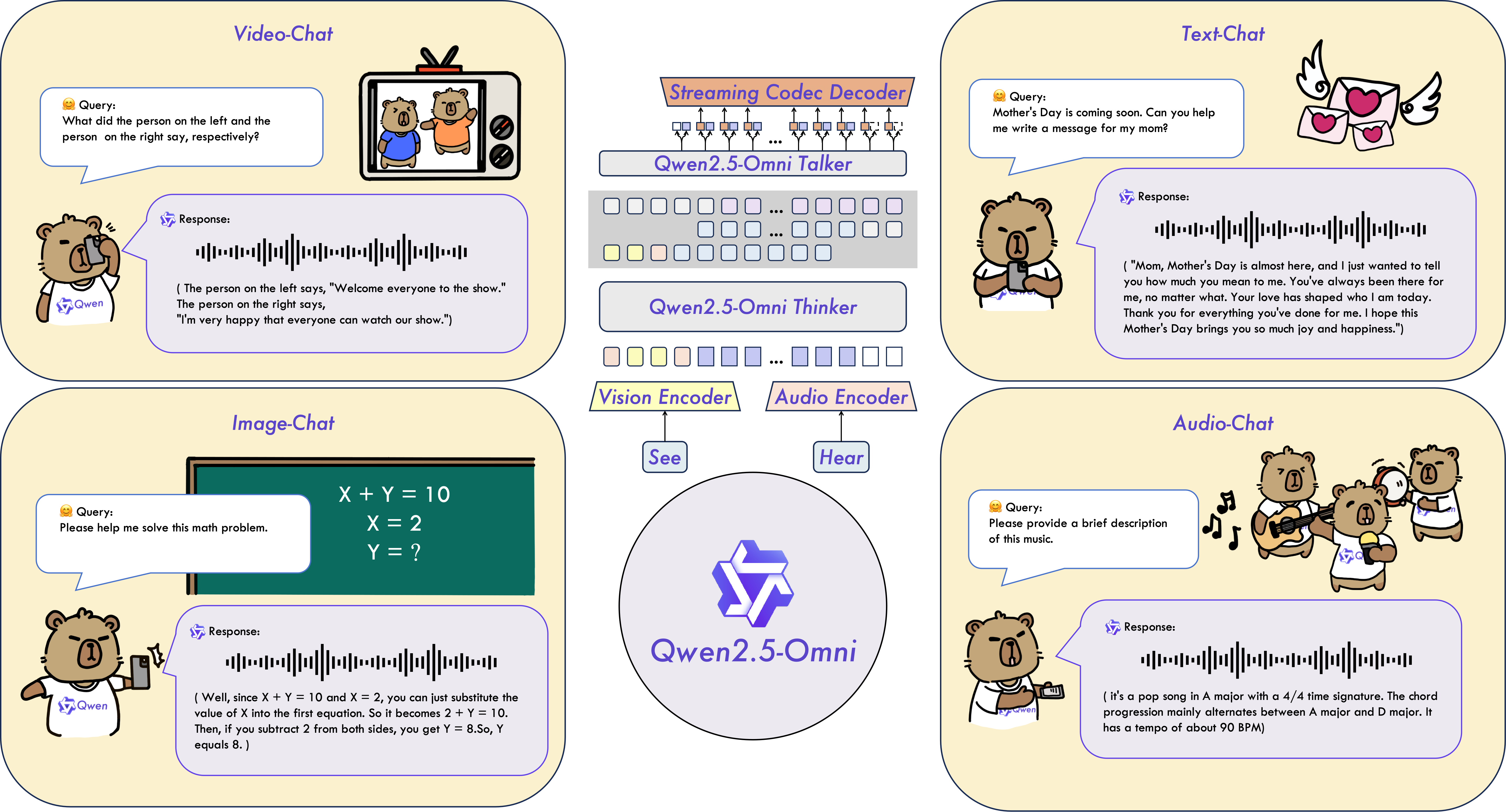
主な特徴
-
オムニかつ革新的なアーキテクチャ: Thinker-Talkerアーキテクチャを提案し、テキスト、画像、音声、動画など多様なモダリティを認識し、同時にテキストと自然な音声応答をストリーミング方式で生成します。動画入力と音声のタイムスタンプを同期させるために、TMRoPE(Time-aligned Multimodal RoPE)という新しい位置埋め込みを提案しています。
-
リアルタイム音声・動画チャット: 完全なリアルタイムインタラクションをサポートするアーキテクチャで、チャンク入力と即時出力に対応しています。
-
自然で堅牢な音声生成: 既存のストリーミングおよび非ストリーミングの代替モデルを凌駕し、音声生成において優れた堅牢性と自然さを実証しています。
-
全モダリティでの強力な性能: 同サイズの単一モダリティモデルと比較して、すべてのモダリティで卓越した性能を示しています。Qwen2.5-Omniは、同サイズのQwen2-Audioを音声能力で上回り、Qwen2.5-VL-7Bと同等の性能を達成しています。
-
優れたエンドツーエンド音声指示追従: Qwen2.5-Omniは、MMLUやGSM8Kなどのベンチマークで示されるように、テキスト入力と同等の効果を持つエンドツーエンド音声指示追従の性能を示しています。
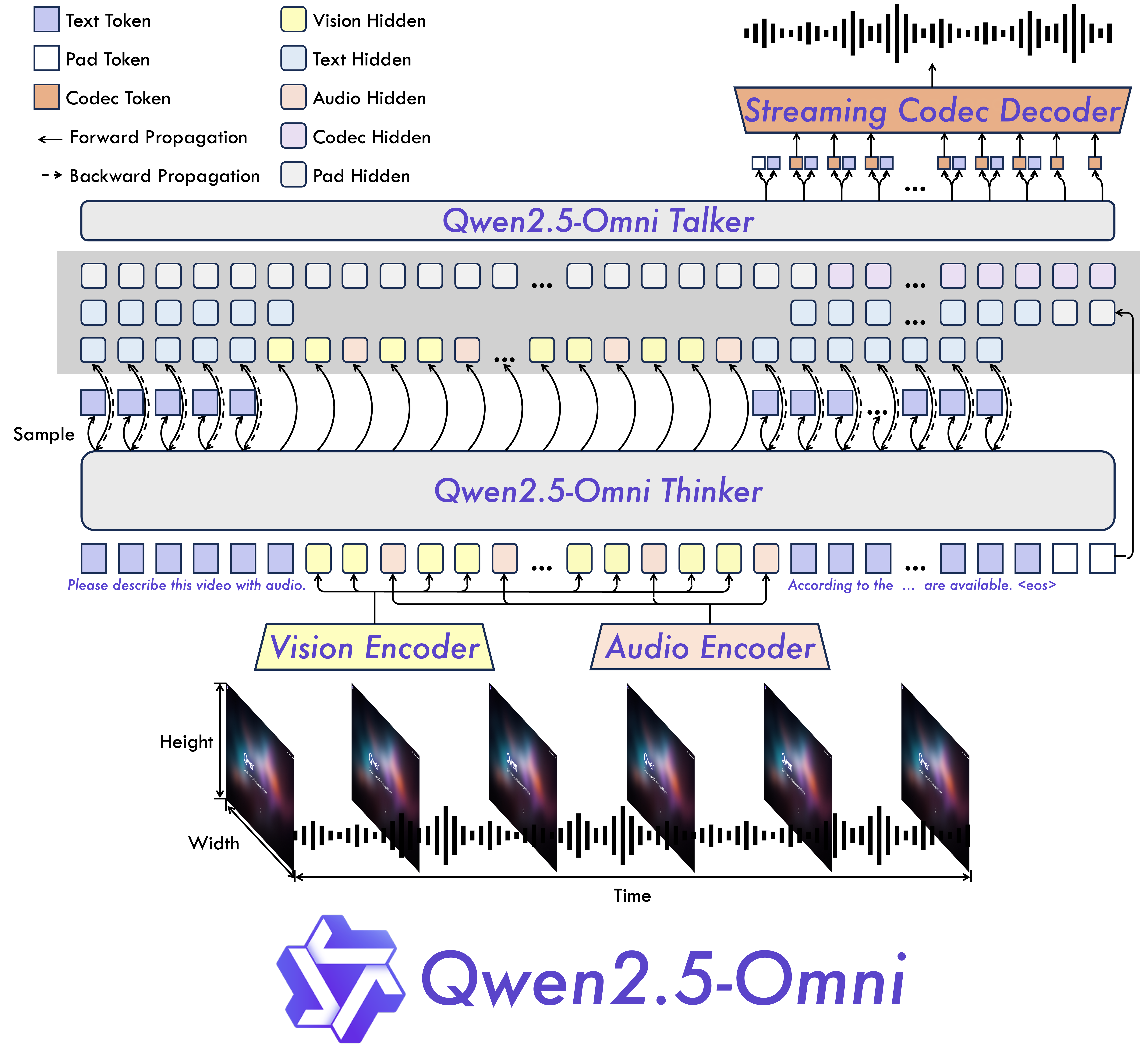
モデルアーキテクチャ
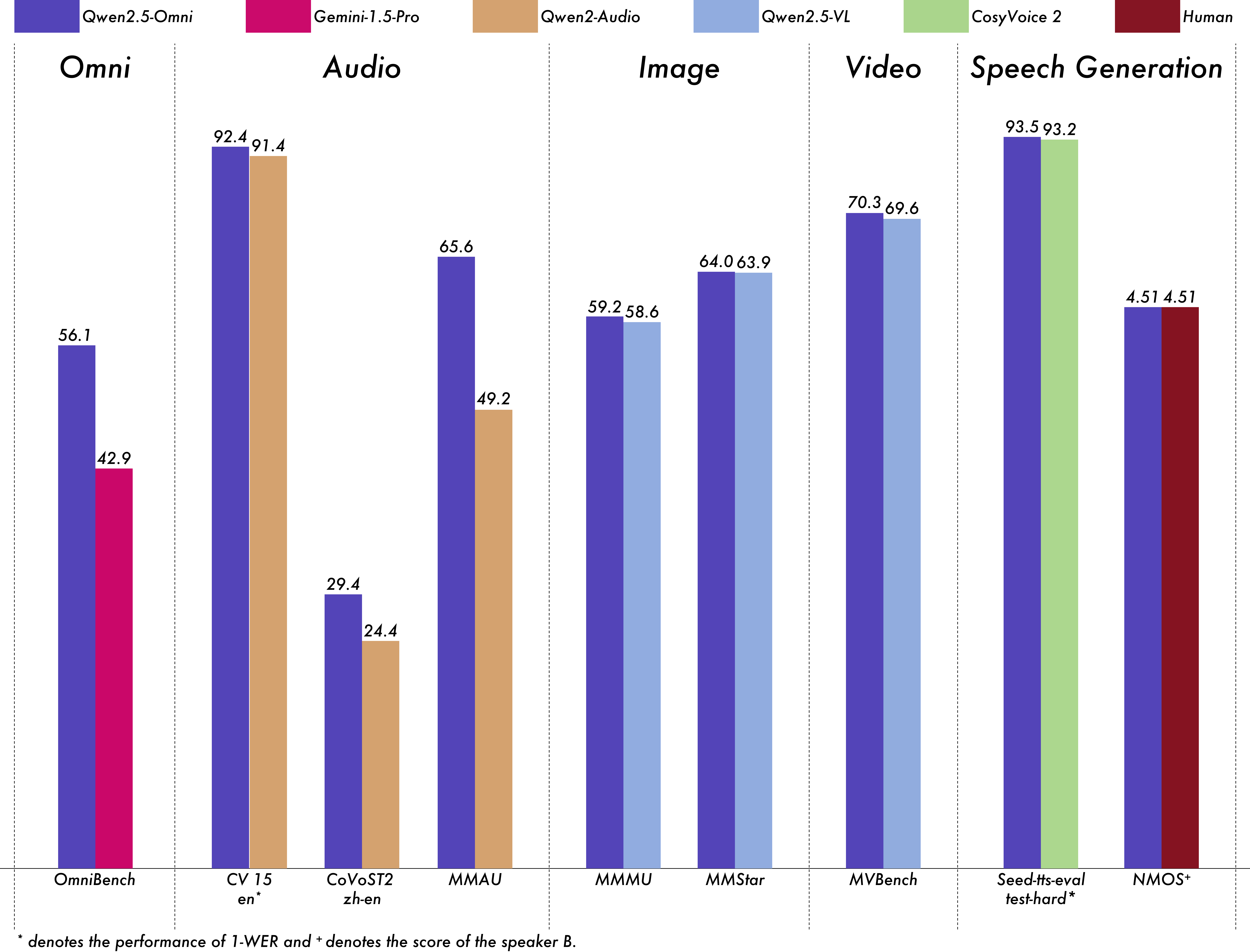
性能
Qwen2.5-Omniの包括的な評価を行い、同サイズの単一モダリティモデルやQwen2.5-VL-7B、Qwen2-Audio、Gemini-1.5-proなどのクローズドソースモデルと比較して、すべてのモダリティで強力な性能を示しています。OmniBenchのような複数のモダリティを統合するタスクでは、Qwen2.5-Omniは最先端の性能を達成しています。さらに、単一モダリティタスクでは、音声認識(Common Voice)、翻訳(CoVoST2)、音声理解(MMAU)、画像推論(MMMU、MMStar)、動画理解(MVBench)、音声生成(Seed-tts-evalおよび主観的自然さ)などの領域で優れています。
マルチモダリティ -> テキスト
| データセット |
モデル |
性能 |
OmniBench
音声 | 音響イベント | 音楽 | 平均 |
Gemini-1.5-Pro |
42.67%|42.26%|46.23%|42.91% |
| MIO-Instruct |
36.96%|33.58%|11.32%|33.80% |
| AnyGPT (7B) |
17.77%|20.75%|13.21%|18.04% |
| video-SALMONN |
34.11%|31.70%|56.60%|35.64% |
| UnifiedIO2-xlarge |
39.56%|36.98%|29.25%|38.00% |
| UnifiedIO2-xxlarge |
34.24%|36.98%|24.53%|33.98% |
| MiniCPM-o |
-|-|-|40.50% |
| Baichuan-Omni-1.5 |
-|-|-|42.90% |
| Qwen2.5-Omni-3B |
52.14%|52.08%|52.83%|52.19% |
| Qwen2.5-Omni-7B |
55.25%|60.00%|52.83%|56.13% |
音声 -> テキスト
| データセット |
モデル |
性能 |
| ASR |
Librispeech
dev-clean | dev other | test-clean | test-other |
SALMONN |
-|-|2.1|4.9 |
| SpeechVerse |
-|-|2.1|4.4 |
| Whisper-large-v3 |
-|-|1.8|3.6 |
| Llama-3-8B |
-|-|-|3.4 |
| Llama-3-70B |
-|-|-|3.1 |
| Seed-ASR-Multilingual |
-|-|1.6|2.8 |
| MiniCPM-o |
-|-|1.7|- |
| MinMo |
-|-|1.7|3.9 |
| Qwen-Audio |
1.8|4.0|2.0|4.2 |
| Qwen2-Audio |
1.3|3.4|1.6|3.6 |
| Qwen2.5-Omni-3B |
2.0|4.1|2.2|4.5 |
| Qwen2.5-Omni-7B |
1.6|3.5|1.8|3.4 |
Common Voice 15
en | zh | yue | fr |
Whisper-large-v3 |
9.3|12.8|10.9|10.8 |
| MinMo |
7.9|6.3|6.4|8.5 |
| Qwen2-Audio |
8.6|6.9|5.9|9.6 |
| Qwen2.5-Omni-3B |
9.1|6.0|11.6|9.6 |
| Qwen2.5-Omni-7B |
7.6|5.2|7.3|7.5 |
Fleurs
zh | en |
Whisper-large-v3 |
7.7|4.1 |
| Seed-ASR-Multilingual |
-|3.4 |
| Megrez-3B-Omni |
10.8|- |
| MiniCPM-o |
4.4|- |
| MinMo |
3.0|3.8 |
| Qwen2-Audio |
7.5|- |
| Qwen2.5-Omni-3B |
3.2|5.4 |
| Qwen2.5-Omni-7B |
3.0|4.1 |
Wenetspeech
test-net | test-meeting |
Seed-ASR-Chinese |
4.7|5.7 |
| Megrez-3B-Omni |
-|16.4 |
| MiniCPM-o |
6.9|- |
| MinMo |
6.8|7.4 |
| Qwen2.5-Omni-3B |
6.3|8.1 |
| Qwen2.5-Omni-7B |
5.9|7.7 |
| Voxpopuli-V1.0-en |
Llama-3-8B |
6.2 |
| Llama-3-70B |
5.7 |
| Qwen2.5-Omni-3B |
6.6 |
| Qwen2.5-Omni-7B |
5.8 |
| S2TT |
CoVoST2
en-de | de-en | en-zh | zh-en |
SALMONN |
18.6|-|33.1|- |
| SpeechLLaMA |
-|27.1|-|12.3 |
| BLSP |
14.1|-|-|- |
| MiniCPM-o |
-|-|48.2|27.2 |
| MinMo |
-|39.9|46.7|26.0 |
| Qwen-Audio |
25.1|33.9|41.5|15.7 |
| Qwen2-Audio |
29.9|35.2|45.2|24.4 |
| Qwen2.5-Omni-3B |
28.3|38.1|41.4|26.6 |
| Qwen2.5-Omni-7B |
30.2|37.7|41.4|29.4 |
| SER |
| Meld |
WavLM-large |
0.542 |
| MiniCPM-o |
0.524 |
| Qwen-Audio |
0.557 |
| Qwen2-Audio |
0.553 |
| Qwen2.5-Omni-3B |
0.558 |
| Qwen2.5-Omni-7B |
0.570 |
| VSC |
| VocalSound |
CLAP |
0.495 |
| Pengi |
0.604 |
| Qwen-Audio |
0.929 |
| Qwen2-Audio |
0.939 |
| Qwen2.5-Omni-3B |
0.936 |
| Qwen2.5-Omni-7B |
0.939 |
| Music |
| GiantSteps Tempo |
Llark-7B |
0.86 |
| Qwen2.5-Omni-3B |
0.88 |
| Qwen2.5-Omni-7B |
0.88 |
| MusicCaps |
LP-MusicCaps |
0.291|0.149|0.089|0.061|0.129|0.130 |
| Qwen2.5-Omni-3B |
0.325|0.163|0.093|0.057|0.132|0.229 |
| Qwen2.5-Omni-7B |
0.328|0.162|0.090|0.055|0.127|0.225 |
| 音声推論 |
MMAU
音響 | 音楽 | 音声 | 平均 |
Gemini-Pro-V1.5 |
56.75|49.40|58.55|54.90 |
| Qwen2-Audio |
54.95|50.98|42.04|49.20 |
| Qwen2.5-Omni-3B |
70.27|60.48|59.16|63.30 |
| Qwen2.5-Omni-7B |
67.87|69.16|59.76|65.60 |
| 音声チャット |
VoiceBench
AlpacaEval | CommonEval | SD-QA | MMSU |
Ultravox-v0.4.1-LLaMA-3.1-8B |
4.55|3.90|53.35|47.17 |
| MERaLiON |
4.50|3.77|55.06|34.95 |
| Megrez-3B-Omni |
3.50|2.95|25.95|27.03 |
| Lyra-Base |
3.85|3.50|38.25|49.74 |
| MiniCPM-o |
4.42|4.15|50.72|54.78 |
| Baichuan-Omni-1.5 |
4.50|4.05|43.40|57.25 |
| Qwen2-Audio |
3.74|3.43|35.71|35.72 |
| Qwen2.5-Omni-3B |
4.32|4.00|49.37|50.23 |
| Qwen2.5-Omni-7B |
4.49|3.93|55.71|61.32 |
VoiceBench
OpenBookQA | IFEval | AdvBench | 平均 |
Ultravox-v0.4.1-LLaMA-3.1-8B |
65.27|66.88|98.46|71.45 |
| MERaLiON |
27.23|62.93|94.81|62.91 |
| Megrez-3B-Omni |
28.35|25.71|87.69|46.25 |
| Lyra-Base |
72.75|36.28|59.62|57.66 |
| MiniCPM-o |
78.02|49.25|97.69|71.69 |
| Baichuan-Omni-1.5 |
74.51|54.54|97.31|71.14 |
| Qwen2-Audio |
49.45|26.33|96.73|55.35 |
| Qwen2.5-Omni-3B |
74.73|42.10|98.85|68.81 |
| Qwen2.5-Omni-7B |
81.10|52.87|99.42|74.12 |
画像 -> テキスト
| データセット |
Qwen2.5-Omni-7B |
Qwen2.5-Omni-3B |
その他最高 |
Qwen2.5-VL-7B |
GPT-4o-mini |
| MMMUval |
59.2 |
53.1 |
53.9 |
58.6 |
60.0 |
| MMMU-Prooverall |
36.6 |
29.7 |
- |
38.3 |
37.6 |
| MathVistatestmini |
67.9 |
59.4 |
71.9 |
68.2 |
52.5 |
| MathVisionfull |
25.0 |
20.8 |
23.1 |
25.1 |
- |
| MMBench-V1.1-ENtest |
81.8 |
77.8 |
80.5 |
82.6 |
76.0 |
| MMVetturbo |
66.8 |
62.1 |
67.5 |
67.1 |
66.9 |
| MMStar |
64.0 |
55.7 |
64.0 |
63.9 |
54.8 |
| MMEsum |
2340 |
2117 |
2372 |
2347 |
2003 |
| MuirBench |
59.2 |
48.0 |
- |
59.2 |
- |
| CRPErelation |
76.5 |
73.7 |
- |
76.4 |
- |
| RealWorldQAavg |
70.3 |
62.6 |
71.9 |
68.5 |
- |
| MME-RealWorlden |
61.6 |
55.6 |
- |
57.4 |
- |
| MM-MT-Bench |
6.0 |
5.0 |
- |
6.3 |
- |
| AI2D |
83.2 |
79.5 |
85.8 |
83.9 |
- |
| TextVQAval |
84.4 |
79.8 |
83.2 |
84.9 |
- |
| DocVQAtest |
95.2 |
93.3 |
93.5 |
95.7 |
- |
| ChartQAtest Avg |
85.3 |
82.8 |
84.9 |
87.3 |
- |
| OCRBench_V2en |
57.8 |
51.7 |
- |
56.3 |
- |
| データセット |
Qwen2.5-Omni-7B |
Qwen2.5-Omni-3B |
Qwen2.5-VL-7B |
Grounding DINO |
Gemini 1.5 Pro |
| Refcocoval |
90.5 |
88.7 |
90.0 |
90.6 |
73.2 |
| RefcocotextA |
93.5 |
91.8 |
92.5 |
93.2 |
72.9 |
| RefcocotextB |
86.6 |
84.0 |
85.4 |
88.2 |
74.6 |
| Refcoco+val |
85.4 |
81.1 |
84.2 |
88.2 |
62.5 |
| Refcoco+textA |
91.0 |
87.5 |
89.1 |
89.0 |
63.9 |
| Refcoco+textB |
79.3 |
73.2 |
76. |
|
|
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応