%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
モデル概要
モデル特徴
モデル能力
使用事例
🚀 SmolVLM-Instruct GGUFモデル
SmolVLM-Instruct GGUFモデルは、画像とテキストの入力を受け取り、テキスト出力を生成するコンパクトなオープンマルチモーダルモデルです。効率性を重視して設計され、画像に関する質問に答えたり、視覚コンテンツを説明したり、複数の画像を基にストーリーを作成したりすることができます。
🚀 クイックスタート
SmolVLMは、画像とテキストの任意のシーケンスを入力として受け取り、テキスト出力を生成するコンパクトなオープンマルチモーダルモデルです。以下のコード例では、transformersライブラリを使用して、SmolVLMをロードし、推論を行う方法を示しています。
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# 画像の読み込み
image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
image2 = load_image("https://huggingface.co/spaces/merve/chameleon-7b/resolve/main/bee.jpg")
# プロセッサとモデルの初期化
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
).to(DEVICE)
# 入力メッセージの作成
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "Can you describe the two images?"}
]
},
]
# 入力の準備
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = inputs.to(DEVICE)
# 出力の生成
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
"""
Assistant: The first image shows a green statue of the Statue of Liberty standing on a stone pedestal in front of a body of water.
The statue is holding a torch in its right hand and a tablet in its left hand. The water is calm and there are no boats or other objects visible.
The sky is clear and there are no clouds. The second image shows a bee on a pink flower.
The bee is black and yellow and is collecting pollen from the flower. The flower is surrounded by green leaves.
"""
✨ 主な機能
- 多様な入力に対応:任意の画像とテキストのシーケンスを入力として受け取り、テキスト出力を生成することができます。
- 軽量なアーキテクチャ:デバイス上でのアプリケーションに適しており、マルチモーダルタスクでも強力な性能を発揮します。
- 高精度な推論:半精度(
torch.float16またはtorch.bfloat16)でのロードと実行が可能で、ハードウェアがサポートする場合は性能が向上します。
📦 インストール
SmolVLMを使用するには、transformersライブラリをインストールする必要があります。以下のコマンドを使用してインストールできます。
pip install transformers
💻 使用例
基本的な使用法
上記のクイックスタートセクションのコード例を参照してください。
高度な使用法
モデルの最適化
ハードウェアがサポートする場合は、半精度でモデルをロードして実行することで、性能を向上させることができます。
from transformers import AutoModelForVision2Seq
import torch
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16
).to("cuda")
また、bitsandbytes、torchaoまたはQuantoを使用して、4/8ビット量子化でモデルをロードすることもできます。詳細はこのページを参照してください。
from transformers import AutoModelForVision2Seq, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
quantization_config=quantization_config,
)
ビジョンエンコーダの効率化
プロセッサを初期化する際に、size={"longest_edge": N*384}を設定することで、画像の解像度を調整することができます。デフォルトのN=4は、1536×1536の入力画像に適しています。文書の場合は、N=5が有益な場合があります。Nを減らすと、GPUメモリを節約でき、低解像度の画像に適しています。また、ビデオでのファインチューニングにも役立ちます。
📚 ドキュメント
モデルの概要
- 開発者: Hugging Face
- モデルタイプ: マルチモーダルモデル(画像+テキスト)
- 言語: 英語
- ライセンス: Apache 2.0
- アーキテクチャ: Idefics3に基づいています。
リソース
用途
SmolVLMは、画像とテキストのマルチモーダルタスクでの推論に使用できます。入力は、テキストクエリと1つ以上の画像で構成されます。テキストと画像は任意に交差させることができ、画像のキャプション付け、視覚的な質問応答、視覚コンテンツに基づくストーリー作成などのタスクが可能です。ただし、画像生成はサポートされていません。
特定のタスクでSmolVLMをファインチューニングするには、ファインチューニングチュートリアルに従ってください。
技術的な概要
SmolVLMは、軽量なSmolLM2言語モデルを活用して、コンパクトで強力なマルチモーダル体験を提供します。以前のIdeficsモデルと比較して、いくつかの変更が導入されています。
- 画像圧縮:Idefics3と比較して、より激しい画像圧縮を導入し、モデルの推論速度を向上させ、RAM使用量を削減しています。
- 視覚トークンエンコーディング:384×384の画像パッチをエンコードするために81の視覚トークンを使用しています。大きな画像はパッチに分割され、それぞれが個別にエンコードされるため、性能を損なうことなく効率が向上します。
トレーニングとアーキテクチャの詳細については、技術レポートを参照してください。
🔧 技術詳細
モデル生成の詳細
このモデルは、llama.cppを使用して、コミット5787b5daで生成されました。
量子化方法の検証
標準のIMatrixでは、低ビット量子化やMOEモデルでの性能が十分でないことがわかりました。そのため、llama.cppの--tensor-typeを使用して、選択したレイヤーをバンプアップする新しい量子化方法をテストしています。詳細はLayer bumping with llama.cppを参照してください。
この方法は、モデルファイルが大きくなる可能性がありますが、与えられたモデルサイズに対して精度が向上します。この方法の性能についてのフィードバックをいただけると幸いです。
適切なモデル形式の選択
適切なモデル形式の選択は、ハードウェアの能力とメモリ制約に依存します。
BF16 (Brain Float 16) – BF16アクセラレーションが利用可能な場合に使用
- 16ビットの浮動小数点形式で、高速な計算を実現しながら、良好な精度を維持します。
- FP32と同様のダイナミックレンジを持ち、メモリ使用量が少ないです。
- ハードウェアがBF16アクセラレーションをサポートしている場合(デバイスの仕様を確認してください)に推奨されます。
- FP32と比較して、メモリ使用量を削減しながら、高性能な推論に適しています。
BF16を使用する場合:
- ハードウェアがネイティブのBF16サポートを持っている場合(例:新しいGPU、TPU)。
- メモリを節約しながら、より高い精度が必要な場合。
- モデルを別の形式に再量子化する予定がある場合。
BF16を避ける場合:
- ハードウェアがBF16をサポートしていない場合(FP32にフォールバックし、低速になる可能性があります)。
- BF16最適化を持たない古いデバイスとの互換性が必要な場合。
F16 (Float 16) – BF16よりも広くサポートされている
- 16ビットの浮動小数点形式で、高い精度を持ち、BF16よりも値の範囲が狭いです。
- FP16アクセラレーションをサポートするほとんどのデバイス(多くのGPUや一部のCPUを含む)で動作します。
- BF16よりもわずかに数値精度が低いですが、一般的に推論には十分です。
F16を使用する場合:
- ハードウェアがFP16をサポートしているが、BF16をサポートしていない場合。
- 速度、メモリ使用量、精度のバランスが必要な場合。
- FP16計算に最適化されたGPUまたは他のデバイスで実行する場合。
F16を避ける場合:
- デバイスがネイティブのFP16サポートを持っていない場合(予想よりも低速になる可能性があります)。
- メモリ制約がある場合。
ハイブリッド精度モデル (例:bf16_q8_0, f16_q4_K) – 両者の良いところを兼ね備えた形式
これらの形式は、非必須のレイヤーを選択的に量子化し、重要なレイヤー(例:アテンションレイヤーや出力レイヤー)をフル精度で保持します。
bf16_q8_0のように命名され、フル精度のBF16コアレイヤー + 量子化されたQ8_0の他のレイヤーを意味します。- メモリ効率と精度のバランスを取り、完全に量子化されたモデルよりも改善され、BF16/F16の全メモリを必要としません。
ハイブリッドモデルを使用する場合:
- 量子化のみのモデルよりも高い精度が必要で、すべての部分でBF16/F16を使用することができない場合。
- デバイスが混合精度推論をサポートしている場合。
- 制約のあるハードウェアでの本番グレードのモデルのトレードオフを最適化したい場合。
ハイブリッドモデルを避ける場合:
- ターゲットデバイスが混合またはフル精度のアクセラレーションをサポートしていない場合。
- 超厳格なメモリ制約の下で動作している場合(この場合は、完全に量子化された形式を使用してください)。
量子化モデル (Q4_K, Q6_K, Q8, など) – CPUと低VRAMでの推論に適しています
量子化は、モデルサイズとメモリ使用量を削減しながら、できるだけ精度を維持します。
- 低ビットモデル (Q4_K) – 最小限のメモリ使用量に最適ですが、精度が低い場合があります。
- 高ビットモデル (Q6_K, Q8_0) – より高い精度を提供しますが、より多くのメモリを必要とします。
量子化モデルを使用する場合:
- CPUで推論を実行し、最適化されたモデルが必要な場合。
- デバイスのVRAMが少なく、フル精度のモデルをロードできない場合。
- 合理的な精度を維持しながら、メモリ使用量を削減したい場合。
量子化モデルを避ける場合:
- 最大限の精度が必要な場合(フル精度のモデルの方が適しています)。
- ハードウェアに十分なVRAMがあり、より高い精度の形式(BF16/F16)が使用可能な場合。
超低ビット量子化 (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)
これらのモデルは、非常に高いメモリ効率を実現するように最適化されており、低電力デバイスやメモリが重要な制約となる大規模なデプロイメントに適しています。
- IQ3_XS:超低ビット量子化(3ビット)で、非常に高いメモリ効率を持ちます。
- 使用ケース:Q4_Kでさえ大きすぎる超低メモリデバイスに最適です。
- トレードオフ:高ビット量子化と比較して、精度が低いです。
- IQ3_S:最大限のメモリ効率のための小さなブロックサイズを持ちます。
- 使用ケース:IQ3_XSが過度に制限的な低メモリデバイスに最適です。
- IQ3_M:IQ3_Sよりも高い精度のための中間ブロックサイズを持ちます。
- 使用ケース:IQ3_Sが制限的すぎる低メモリデバイスに適しています。
- Q4_K:ブロック単位の最適化による4ビット量子化で、より高い精度を提供します。
- 使用ケース:Q6_Kが大きすぎる低メモリデバイスに最適です。
- Q4_0:純粋な4ビット量子化で、ARMデバイス用に最適化されています。
- 使用ケース:ARMベースのデバイスまたは低メモリ環境に最適です。
超超低ビット量子化 (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)
- 超超低ビット量子化(1/2ビット)で、非常に高いメモリ効率を持ちます。
- 使用ケース:非常に制約のあるメモリにモデルを収める必要がある場合に最適です。
- トレードオフ:非常に低い精度です。期待どおりに機能しない場合があります。使用前に十分にテストしてください。
モデル形式選択のまとめ表
| モデル形式 | 精度 | メモリ使用量 | デバイス要件 | 最適な使用ケース |
|---|---|---|---|---|
| BF16 | 非常に高い | 高い | BF16対応のGPU/CPU | メモリを削減した高速推論 |
| F16 | 高い | 高い | FP16対応のGPU/CPU | BF16が利用できない場合の推論 |
| Q4_K | 中 - 低 | 低い | CPUまたは低VRAMデバイス | メモリ制約のある推論 |
| Q6_K | 中 | 中程度 | より多くのメモリを持つCPU | 量子化によるより高い精度 |
| Q8_0 | 高い | 中程度 | 中程度のVRAMを持つGPU/CPU | 量子化モデルの中で最も高い精度 |
| IQ3_XS | 低い | 非常に低い | 超低メモリデバイス | 最大限のメモリ効率、低い精度 |
| IQ3_S | 低い | 非常に低い | 低メモリデバイス | IQ3_XSよりも少し使いやすい |
| IQ3_M | 低 - 中 | 低い | 低メモリデバイス | IQ3_Sよりも高い精度 |
| Q4_0 | 低い | 低い | ARMベース/組み込みデバイス | Llama.cppがARM推論用に自動的に最適化します |
| 超超低ビット (IQ1/2_*) | 非常に低い | 非常に低い | 小さなエッジ/組み込みデバイス | 非常に狭いメモリにモデルを収める; 低い精度 |
ハイブリッド (例:bf16_q8_0) |
中 - 高 | 中程度 | 混合精度対応のハードウェア | バランスの取れた性能とメモリ、重要なレイヤーでのFPに近い精度 |
📄 ライセンス
SmolVLMは、画像エンコーダとしてthe shape-optimized SigLIP、テキストデコーダ部分としてSmolLM2を使用して構築されています。
SmolVLMのチェックポイントは、Apache 2.0ライセンスの下で公開されています。
トレーニングデータ
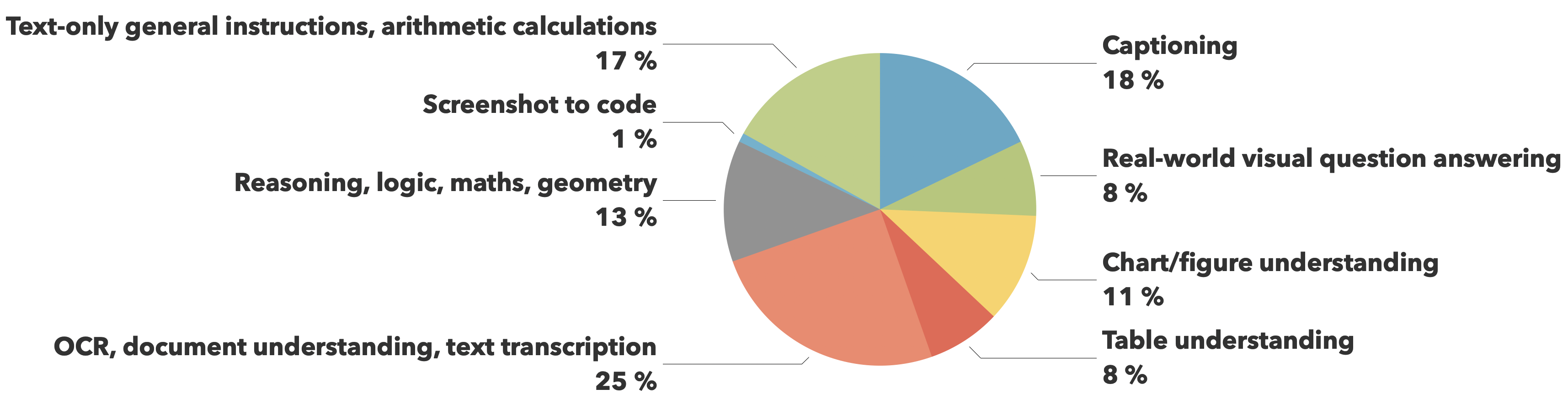
トレーニングデータは、The CauldronとDocmatixデータセットから取得されており、文書理解(25%)と画像キャプション付け(18%)に重点を置き、視覚的な推論、チャート理解、一般的な命令の追従などの他の重要な機能にもバランスよくカバーされています。
評価
| モデル | MMMU (val) | MathVista (testmini) | MMStar (val) | DocVQA (test) | TextVQA (val) | 必要な最小GPU RAM (GB) |
|---|---|---|---|---|---|---|
| SmolVLM | 38.8 | 44.6 | 42.1 | 81.6 | 72.7 | 5.02 |
| Qwen-VL 2B | 41.1 | 47.8 | 47.5 | 90.1 | 79.7 | 13.70 |
| InternVL2 2B | 34.3 | 46.3 | 49.8 | 86.9 | 73.4 | 10.52 |
| PaliGemma 3B 448px | 34.9 | 28.7 | 48.3 | 32.2 | 56.0 | 6.72 |
| moondream2 | 32.4 | 24.3 | 40.3 | 70.5 | 65.2 | 3.87 |
| MiniCPM-V-2 | 38.2 | 39.8 | 39.1 | 71.9 | 74.1 | 7.88 |
| MM1.5 1B | 35.8 | 37.2 | 0.0 | 81.0 | 72.5 | NaN |
引用情報
次のように引用することができます。
@article{marafioti2025smolvlm,
title={SmolVLM: Redefining small and efficient multimodal models},
author={Andrés Marafioti and Orr Zohar and Miquel Farré and Merve Noyan and Elie Bakouch and Pedro Cuenca and Cyril Zakka and Loubna Ben Allal and Anton Lozhkov and Nouamane Tazi and Vaibhav Srivastav and Joshua Lochner and Hugo Larcher and Mathieu Morlon and Lewis Tunstall and Leandro von Werra and Thomas Wolf},
journal={arXiv preprint arXiv:2504.05299},
year={2025}
}
モデルのテストに関する情報
もしこれらのモデルが役に立つと思われる場合は、AI搭載の量子ネットワークモニターアシスタントの量子対応セキュリティチェックを行うためのテストに協力していただけると幸いです。
量子ネットワークモニターサービスの完全なオープンソースコードは、私のGitHubリポジトリ(NetworkMonitorという名前のリポジトリ)で入手できます。量子ネットワークモニターのソースコード また、モデルを自分で量子化したい場合は、私が使用しているコードもGGUFModelBuilderで見つけることができます。
テスト方法
AIアシスタントのタイプを選択してください。
TurboLLM(GPT-4.1-mini)HugLLM(Huggingfaceのオープンソースモデル)TestLLM(実験的なCPU専用)
テスト内容
私は、AIネットワークモニタリングのための小さなオープンソースモデルの限界を追求しています。具体的には、
- ライブネットワークサービスに対する関数呼び出し
- 以下のタスクを処理しながら、モデルをどれだけ小さくできるか
- 自動化されたNmapセキュリティスキャン
- 量子対応チェック
- ネットワークモニタリングタスク
TestLLM – 現在の実験的モデル (Hugging FaceのDockerスペース上で2つのCPUスレッドで動作するllama.cpp)
- ゼロコンフィギュレーションセットアップ
- 30秒のロード時間(推論は遅いですが、APIコストがかからない)。コストが低いため、トークン制限はありません。
- 協力者を募集しています! エッジデバイスAIに興味がある方は、一緒に協力しましょう!
その他のアシスタント
- TurboLLM – gpt-4.1-miniを使用しています。
- 非常に良好な性能を発揮しますが、残念ながらOpenAIはトークンごとに料金を請求します。そのため、トークンの使用量に制限があります。
- 量子ネットワークモニターエージェントで.NETコードを実行するためのカスタムコマンドプロセッサを作成します。
- リアルタイムのネットワーク診断とモニタリング
- セキュリティ監査
- ペネトレーションテスト (Nmap/Metasploit)
- HugLLM – 最新のオープンソースモデルを使用しています。
- Hugging Faceの推論APIで動作します。Novitaでホストされている最新のモデルを使用して、かなり良好な性能を発揮します。
テストできるコマンドの例
"Give me info on my websites SSL certificate""Check if my server is using quantum safe encyption for communication""Run a comprehensive security audit on my server""Create a cmd processor to .. (what ever you want)"注:.NETコードを実行するには、量子ネットワークモニターエージェントをインストールする必要があります。これは非常に柔軟で強力な機能です。注意して使用してください!
最後に
私は、これらのモデルファイルを作成し、量子ネットワークモニターサービスを実行するためのサーバーを資金提供しています。