%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Model Overview
Model Features
Model Capabilities
Use Cases
🚀 SmolVLM-Instruct GGUF Models
SmolVLM-Instruct GGUF Models are a set of models designed for efficient multimodal processing. They can handle various tasks such as answering questions about images, describing visual content, and creating stories based on multiple images.
🚀 Quick Start
You can use the following Python code to load and run the SmolVLM model:
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Load images
image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
image2 = load_image("https://huggingface.co/spaces/merve/chameleon-7b/resolve/main/bee.jpg")
# Initialize processor and model
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
).to(DEVICE)
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "Can you describe the two images?"}
]
},
]
# Prepare inputs
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = inputs.to(DEVICE)
# Generate outputs
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
"""
Assistant: The first image shows a green statue of the Statue of Liberty standing on a stone pedestal in front of a body of water.
The statue is holding a torch in its right hand and a tablet in its left hand. The water is calm and there are no boats or other objects visible.
The sky is clear and there are no clouds. The second image shows a bee on a pink flower.
The bee is black and yellow and is collecting pollen from the flower. The flower is surrounded by green leaves.
"""
✨ Features
- Multimodal Input: Accepts arbitrary sequences of image and text inputs to produce text outputs.
- Efficient Architecture: Lightweight and suitable for on-device applications while maintaining strong performance on multimodal tasks.
- Versatile Use Cases: Can answer questions about images, describe visual content, create stories based on multiple images, or function as a pure language model without visual inputs.
📦 Installation
The model can be loaded using the transformers library. You can install transformers using pip:
pip install transformers
💻 Usage Examples
Basic Usage
The above quick start code is a basic example of using the SmolVLM model to describe images.
Advanced Usage
Model Optimizations
Precision: For better performance, load and run the model in half-precision (torch.float16 or torch.bfloat16) if your hardware supports it.
from transformers import AutoModelForVision2Seq
import torch
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16
).to("cuda")
You can also load SmolVLM with 4/8-bit quantization using bitsandbytes, torchao or Quanto. Refer to this page for other options.
from transformers import AutoModelForVision2Seq, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
quantization_config=quantization_config,
)
Vision Encoder Efficiency: Adjust the image resolution by setting size={"longest_edge": N*384} when initializing the processor, where N is your desired value. The default N=4 works well, which results in input images of size 1536×1536. For documents, N=5 might be beneficial. Decreasing N can save GPU memory and is appropriate for lower-resolution images. This is also useful if you want to fine-tune on videos.
📚 Documentation
Model Summary
- Developed by: Hugging Face
- Model type: Multi-modal model (image+text)
- Language(s) (NLP): English
- License: Apache 2.0
- Architecture: Based on Idefics3 (see technical summary)
Resources
- Demo: SmolVLM Demo
- Blog: Blog post
Uses
SmolVLM can be used for inference on multimodal (image + text) tasks where the input comprises text queries along with one or more images. Text and images can be interleaved arbitrarily, enabling tasks like image captioning, visual question answering, and storytelling based on visual content. The model does not support image generation.
To fine-tune SmolVLM on a specific task, you can follow the fine-tuning tutorial.
Technical Summary
SmolVLM leverages the lightweight SmolLM2 language model to provide a compact yet powerful multimodal experience. It introduces several changes compared to previous Idefics models:
- Image compression: A more radical image compression compared to Idefics3 is introduced to enable the model to infer faster and use less RAM.
- Visual Token Encoding: SmolVLM uses 81 visual tokens to encode image patches of size 384×384. Larger images are divided into patches, each encoded separately, enhancing efficiency without compromising performance.
More details about the training and architecture are available in our technical report.
Misuse and Out-of-scope Use
SmolVLM is not intended for high-stakes scenarios or critical decision-making processes that affect an individual's well-being or livelihood. The model may produce content that appears factual but may not be accurate. Misuse includes, but is not limited to:
- Prohibited Uses:
- Evaluating or scoring individuals (e.g., in employment, education, credit)
- Critical automated decision-making
- Generating unreliable factual content
- Malicious Activities:
- Spam generation
- Disinformation campaigns
- Harassment or abuse
- Unauthorized surveillance
License
SmolVLM is built upon the shape-optimized SigLIP as image encoder and SmolLM2 for text decoder part.
We release the SmolVLM checkpoints under the Apache 2.0 license.
Training Details
Training Data
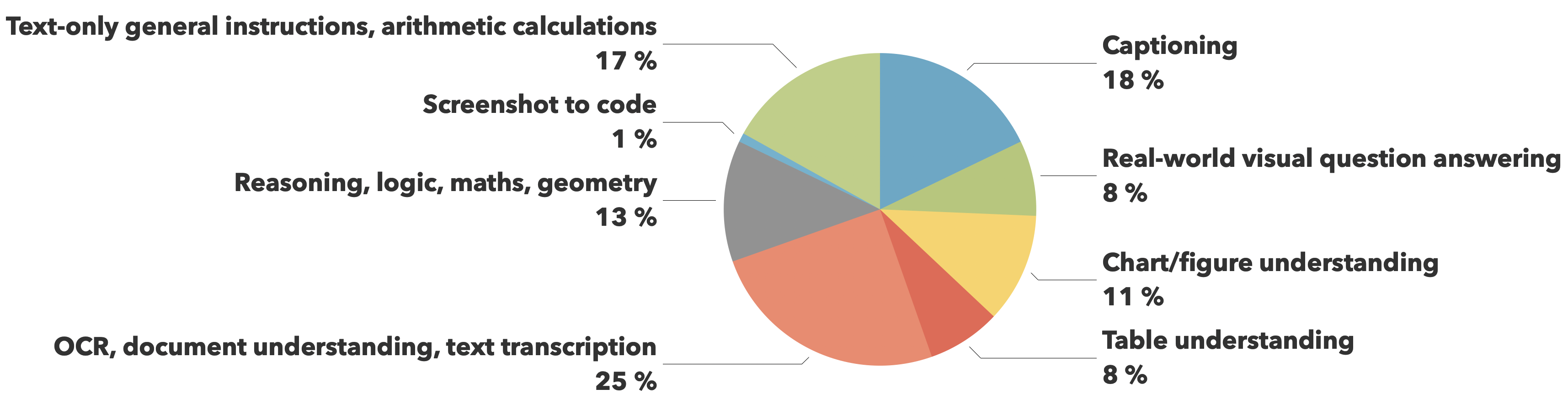
The training data comes from The Cauldron and Docmatix datasets, with emphasis on document understanding (25%) and image captioning (18%), while maintaining balanced coverage across other crucial capabilities like visual reasoning, chart comprehension, and general instruction following.
Evaluation
| Model | MMMU (val) | MathVista (testmini) | MMStar (val) | DocVQA (test) | TextVQA (val) | Min GPU RAM required (GB) |
|---|---|---|---|---|---|---|
| SmolVLM | 38.8 | 44.6 | 42.1 | 81.6 | 72.7 | 5.02 |
| Qwen-VL 2B | 41.1 | 47.8 | 47.5 | 90.1 | 79.7 | 13.70 |
| InternVL2 2B | 34.3 | 46.3 | 49.8 | 86.9 | 73.4 | 10.52 |
| PaliGemma 3B 448px | 34.9 | 28.7 | 48.3 | 32.2 | 56.0 | 6.72 |
| moondream2 | 32.4 | 24.3 | 40.3 | 70.5 | 65.2 | 3.87 |
| MiniCPM-V-2 | 38.2 | 39.8 | 39.1 | 71.9 | 74.1 | 7.88 |
| MM1.5 1B | 35.8 | 37.2 | 0.0 | 81.0 | 72.5 | NaN |
🔧 Technical Details
Model Generation Details
This model was generated using llama.cpp at commit 5787b5da.
Quantization beyond the IMatrix
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
The standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So llama.cpp --tensor-type is used to bump up selected layers. See Layer bumping with llama.cpp
This does create larger model files but increases precision for a given model size.
Please provide feedback on how you find this method performs
Choosing the Right Model Format
Selecting the correct model format depends on your hardware capabilities and memory constraints.
BF16 (Brain Float 16) – Use if BF16 acceleration is available
- A 16-bit floating-point format designed for faster computation while retaining good precision.
- Provides similar dynamic range as FP32 but with lower memory usage.
- Recommended if your hardware supports BF16 acceleration (check your device's specs).
- Ideal for high-performance inference with reduced memory footprint compared to FP32.
Use BF16 if:
- Your hardware has native BF16 support (e.g., newer GPUs, TPUs).
- You want higher precision while saving memory.
- You plan to requantize the model into another format.
Avoid BF16 if:
- Your hardware does not support BF16 (it may fall back to FP32 and run slower).
- You need compatibility with older devices that lack BF16 optimization.
F16 (Float 16) – More widely supported than BF16
- A 16-bit floating-point high precision but with less of range of values than BF16.
- Works on most devices with FP16 acceleration support (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
Use F16 if:
- Your hardware supports FP16 but not BF16.
- You need a balance between speed, memory usage, and accuracy.
- You are running on a GPU or another device optimized for FP16 computations.
Avoid F16 if:
- Your device lacks native FP16 support (it may run slower than expected).
- You have memory limitations.
Hybrid Precision Models (e.g., bf16_q8_0, f16_q4_K) – Best of Both Worlds
These formats selectively quantize non-essential layers while keeping key layers in full precision (e.g., attention and output layers).
- Named like
bf16_q8_0(meaning full-precision BF16 core layers + quantized Q8_0 other layers). - Strike a balance between memory efficiency and accuracy, improving over fully quantized models without requiring the full memory of BF16/F16.
Use Hybrid Models if:
- You need better accuracy than quant-only models but can’t afford full BF16/F16 everywhere.
- Your device supports mixed-precision inference.
- You want to optimize trade-offs for production-grade models on constrained hardware.
Avoid Hybrid Models if:
- Your target device doesn’t support mixed or full-precision acceleration.
- You are operating under ultra-strict memory limits (in which case use fully quantized formats).
Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- Lower-bit models (Q4_K) – Best for minimal memory usage, may have lower precision.
- Higher-bit models (Q6_K, Q8_0) – Better accuracy, requires more memory.
Use Quantized Models if:
- You are running inference on a CPU and need an optimized model.
- Your device has low VRAM and cannot load full-precision models.
- You want to reduce memory footprint while keeping reasonable accuracy.
Avoid Quantized Models if:
- You need maximum accuracy (full-precision models are better for this).
- Your hardware has enough VRAM for higher-precision formats (BF16/F16).
Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)
These models are optimized for very high memory efficiency, making them ideal for low-power devices or large-scale deployments where memory is a critical constraint.
- IQ3_XS: Ultra-low-bit quantization (3-bit) with very high memory efficiency.
- Use case: Best for ultra-low-memory devices where even Q4_K is too large.
- Trade-off: Lower accuracy compared to higher-bit quantizations.
- IQ3_S: Small block size for maximum memory efficiency.
- Use case: Best for low-memory devices where IQ3_XS is too aggressive.
- IQ3_M: Medium block size for better accuracy than IQ3_S.
- Use case: Suitable for low-memory devices where IQ3_S is too limiting.
- Q4_K: 4-bit quantization with block-wise optimization for better accuracy.
- Use case: Best for low-memory devices where Q6_K is too large.
- Q4_0: Pure 4-bit quantization, optimized for ARM devices.
- Use case: Best for ARM-based devices or low-memory environments.
Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)
- Ultra-low-bit quantization (1 2-bit) with extreme memory efficiency.
- Use case: Best for cases where you have to fit the model into very constrained memory.
- Trade-off: Very Low Accuracy. May not function as expected. Please test fully before using.
Summary Table: Model Format Selection
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|---|---|---|---|---|
| BF16 | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| F16 | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| Q4_K | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| Q6_K | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| Q8_0 | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| IQ3_XS | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| IQ3_S | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| IQ3_M | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| Q4_0 | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| Ultra Low-Bit (IQ1/2_*) | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
Hybrid (e.g., bf16_q8_0) |
Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
📄 License
SmolVLM is built upon the shape-optimized SigLIP as image encoder and SmolLM2 for text decoder part.
We release the SmolVLM checkpoints under the Apache 2.0 license.
Citation information
You can cite us in the following way:
@article{marafioti2025smolvlm,
title={SmolVLM: Redefining small and efficient multimodal models},
author={Andrés Marafioti and Orr Zohar and Miquel Farré and Merve Noyan and Elie Bakouch and Pedro Cuenca and Cyril Zakka and Loubna Ben Allal and Anton Lozhkov and Nouamane Tazi and Vaibhav Srivastav and Joshua Lochner and Hugo Larcher and Mathieu Morlon and Lewis Tunstall and Leandro von Werra and Thomas Wolf},
journal={arXiv preprint arXiv:2504.05299},
year={2025}
}
If you find these models useful
Help me test my AI-Powered Quantum Network Monitor Assistant with quantum-ready security checks:
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : Source Code Quantum Network Monitor. You will also find the code I use to quantize the models if you want to do it yourself GGUFModelBuilder
How to test:
Choose an AI assistant type:
TurboLLM(GPT-4.1-mini)HugLLM(Hugginface Open-source models)TestLLM(Experimental CPU-only)
What I’m Testing
I’m pushing the limits of small open-source models for AI network monitoring, specifically:
- Function calling against live network services
- How small can a model go while still handling:
- Automated Nmap security scans
- Quantum-readiness checks
- Network Monitoring tasks
TestLLM – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- Zero-configuration setup
- 30s load time (slow inference but no API costs) . No token limited as the cost is low.
- Help wanted! If you’re into edge-device AI, let’s collaborate!
Other Assistants
TurboLLM – Uses gpt-4.1-mini :
- **It performs very well but unfortunately OpenAI charges per token. For this reason tokens usage is limited.
- Create custom cmd processors to run .net code on Quantum Network Monitor Agents
- Real-time network diagnostics and monitoring
- Security Audits
- Penetration testing (Nmap/Metasploit)
HugLLM – Latest Open-source models:
- Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
Example commands you could test:
"Give me info on my websites SSL certificate""Check if my server is using quantum safe encyption for communication""Run a comprehensive security audit on my server"- '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service