%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
模型概述
模型特點
模型能力
使用案例
🚀 SmolVLM-Instruct GGUF模型
SmolVLM是一個緊湊的開源多模態模型,它可以接受任意的圖像和文本輸入序列,並生成文本輸出。該模型專為高效設計,能夠回答關於圖像的問題、描述視覺內容、基於多張圖像創作故事,甚至在沒有視覺輸入的情況下作為純語言模型使用。其輕量級架構使其適用於設備端應用,同時在多模態任務上保持了強大的性能。
🚀 快速開始
你可以使用transformers庫來加載、推理和微調SmolVLM模型。以下是一個使用示例:
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# 加載圖像
image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
image2 = load_image("https://huggingface.co/spaces/merve/chameleon-7b/resolve/main/bee.jpg")
# 初始化處理器和模型
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
).to(DEVICE)
# 創建輸入消息
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "Can you describe the two images?"}
]
},
]
# 準備輸入
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = inputs.to(DEVICE)
# 生成輸出
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
"""
Assistant: The first image shows a green statue of the Statue of Liberty standing on a stone pedestal in front of a body of water.
The statue is holding a torch in its right hand and a tablet in its left hand. The water is calm and there are no boats or other objects visible.
The sky is clear and there are no clouds. The second image shows a bee on a pink flower.
The bee is black and yellow and is collecting pollen from the flower. The flower is surrounded by green leaves.
"""
✨ 主要特性
- 多模態處理:能夠接受圖像和文本的任意序列輸入,並生成文本輸出。
- 高效輕量:適合設備端應用,在多模態任務上仍保持強大性能。
- 功能多樣:可回答圖像相關問題、描述視覺內容、創作故事等。
📦 安裝指南
文檔未提及具體安裝步驟,可參考transformers庫的官方安裝指南進行安裝。
💻 使用示例
基礎用法
# 上述快速開始中的代碼示例即為基礎用法示例
高級用法
模型優化
精度優化:如果你的硬件支持,可以使用半精度(torch.float16或torch.bfloat16)加載和運行模型,以獲得更好的性能。
from transformers import AutoModelForVision2Seq
import torch
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16
).to("cuda")
你還可以使用bitsandbytes、torchao或Quanto對SmolVLM進行4/8位量化。更多選項請參考此頁面。
from transformers import AutoModelForVision2Seq, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
quantization_config=quantization_config,
)
視覺編碼器效率優化:在初始化處理器時,通過設置size={"longest_edge": N*384}來調整圖像分辨率,其中N是你期望的值。默認N=4,對應輸入圖像大小為1536x1536。對於文檔處理,N=5可能更合適。減小N可以節省GPU內存,適用於低分辨率圖像,也可用於視頻微調。
📚 詳細文檔
模型生成細節
該模型使用llama.cpp在提交版本5787b5da時生成。
超越IMatrix的量化方法
測試一種新的量化方法,使用規則將重要層的量化級別提升到標準IMatrix之上。標準IMatrix在低比特量化和MOE模型中表現不佳,因此使用llama.cpp --tensor-type來提升選定層的量化級別。詳情見使用llama.cpp進行層提升。這種方法會增加模型文件大小,但能提高給定模型大小下的精度。
選擇合適的模型格式
選擇正確的模型格式取決於你的硬件能力和內存限制。
| 模型格式 | 精度 | 內存使用 | 設備要求 | 最佳使用場景 |
|---|---|---|---|---|
| BF16 | 非常高 | 高 | 支持BF16的GPU/CPU | 減少內存的高速推理 |
| F16 | 高 | 高 | 支持FP16的GPU/CPU | BF16不可用時的推理 |
| Q4_K | 中低 | 低 | CPU或低顯存設備 | 內存受限的推理 |
| Q6_K | 中等 | 適中 | 內存較多的CPU | 量化下更好的精度 |
| Q8_0 | 高 | 適中 | 顯存適中的GPU/CPU | 量化模型中最高的精度 |
| IQ3_XS | 低 | 非常低 | 超低內存設備 | 最大內存效率,低精度 |
| IQ3_S | 低 | 非常低 | 低內存設備 | 比IQ3_XS更可用 |
| IQ3_M | 中低 | 低 | 低內存設備 | 比IQ3_S精度更好 |
| Q4_0 | 低 | 低 | 基於ARM的/嵌入式設備 | Llama.cpp自動優化ARM推理 |
| 超低比特(IQ1/2_*) | 非常低 | 極低 | 小型邊緣/嵌入式設備 | 在極緊內存中適配模型;低精度 |
混合(如bf16_q8_0) |
中高 | 中等 | 支持混合精度的硬件 | 平衡性能和內存,關鍵層接近FP精度 |
模型總結
- 開發者:Hugging Face
- 模型類型:多模態模型(圖像+文本)
- 語言(NLP):英語
- 許可證:Apache 2.0
- 架構:基於Idefics3
資源
用途
SmolVLM可用於多模態(圖像+文本)任務的推理,輸入可以是文本查詢和一個或多個圖像的任意組合。支持圖像描述、視覺問答、基於圖像的故事創作等任務,但不支持圖像生成。若要對SmolVLM進行特定任務的微調,可參考微調教程(待添加鏈接)。
濫用和超出範圍的使用
SmolVLM不適用於高風險場景或影響個人福祉和生計的關鍵決策過程。該模型可能會生成看似事實但不準確的內容。濫用情況包括但不限於:
- 禁止用途:
- 評估或評分個人(如就業、教育、信貸方面)
- 關鍵自動化決策
- 生成不可靠的事實內容
- 惡意活動:
- 垃圾郵件生成
- 虛假信息傳播
- 騷擾或濫用
- 未經授權的監控
訓練細節
訓練數據
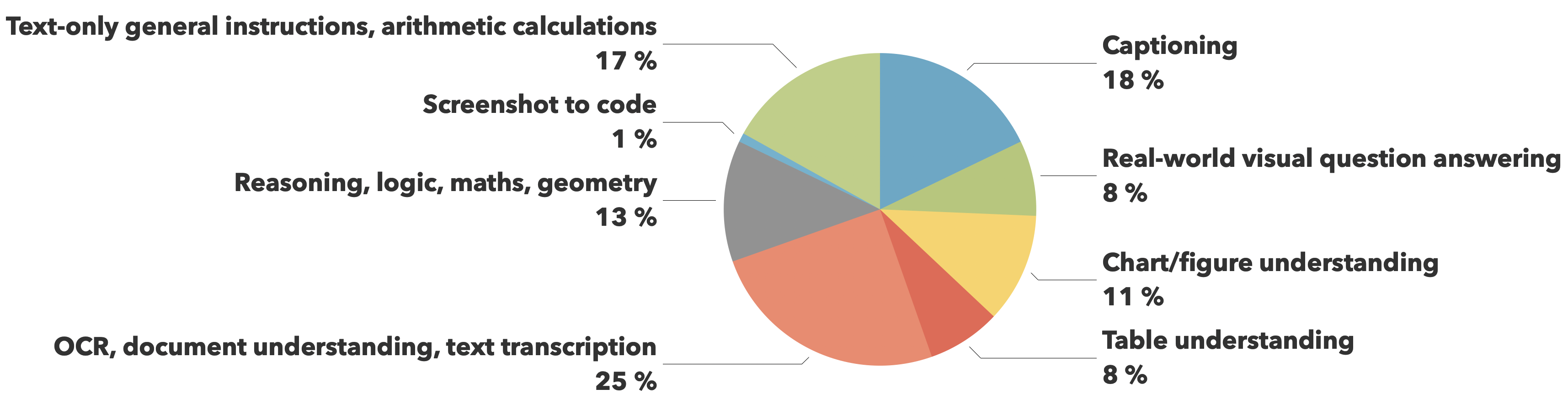
訓練數據來自The Cauldron和Docmatix數據集,重點關注文檔理解(25%)和圖像描述(18%),同時在視覺推理、圖表理解和一般指令遵循等其他關鍵能力方面保持平衡覆蓋。
評估
| 模型 | MMMU(驗證集) | MathVista(測試迷你集) | MMStar(驗證集) | DocVQA(測試集) | TextVQA(驗證集) | 最小GPU顯存要求(GB) |
|---|---|---|---|---|---|---|
| SmolVLM | 38.8 | 44.6 | 42.1 | 81.6 | 72.7 | 5.02 |
| Qwen-VL 2B | 41.1 | 47.8 | 47.5 | 90.1 | 79.7 | 13.70 |
| InternVL2 2B | 34.3 | 46.3 | 49.8 | 86.9 | 73.4 | 10.52 |
| PaliGemma 3B 448px | 34.9 | 28.7 | 48.3 | 32.2 | 56.0 | 6.72 |
| moondream2 | 32.4 | 24.3 | 40.3 | 70.5 | 65.2 | 3.87 |
| MiniCPM-V-2 | 38.2 | 39.8 | 39.1 | 71.9 | 74.1 | 7.88 |
| MM1.5 1B | 35.8 | 37.2 | 0.0 | 81.0 | 72.5 | NaN |
🔧 技術細節
SmolVLM利用輕量級的SmolLM2語言模型,提供緊湊而強大的多模態體驗。與之前的Idefics模型相比,它有以下改進:
- 圖像壓縮:引入比Idefics3更激進的圖像壓縮方法,使模型推理更快,使用的RAM更少。
- 視覺令牌編碼:使用81個視覺令牌對384x384大小的圖像塊進行編碼。較大的圖像會被分割成塊,分別進行編碼,在不影響性能的前提下提高了效率。
📄 許可證
SmolVLM基於形狀優化的SigLIP作為圖像編碼器,SmolLM2作為文本解碼器。SmolVLM的檢查點以Apache 2.0許可證發佈。
📖 引用信息
你可以按以下方式引用我們:
@article{marafioti2025smolvlm,
title={SmolVLM: Redefining small and efficient multimodal models},
author={Andrés Marafioti and Orr Zohar and Miquel Farré and Merve Noyan and Elie Bakouch and Pedro Cuenca and Cyril Zakka and Loubna Ben Allal and Anton Lozhkov and Nouamane Tazi and Vaibhav Srivastav and Joshua Lochner and Hugo Larcher and Mathieu Morlon and Lewis Tunstall and Leandro von Werra and Thomas Wolf},
journal={arXiv preprint arXiv:2504.05299},
year={2025}
}
🔍 量子網絡監控測試相關
測試說明
如果你覺得這些模型有用,可以幫助測試AI驅動的量子網絡監控助手,進行量子就緒安全檢查。
- 量子網絡監控器:量子網絡監控器
- 源代碼:量子網絡監控服務的完整開源代碼可在GitHub倉庫找到,你還能找到用於量化模型的代碼GGUFModelBuilder。
測試方法
選擇一種AI助手類型:
TurboLLM(GPT - 4.1 - mini)HugLLM(Huggingface開源模型)TestLLM(僅支持CPU的實驗性模型)
測試內容
正在測試小型開源模型在AI網絡監控方面的極限,具體包括:
- 針對即時網絡服務的函數調用
- 模型在處理以下任務時的最小規模:
- 自動化Nmap安全掃描
- 量子就緒檢查
- 網絡監控任務
各助手特點
TestLLM
當前的實驗性模型(在Huggingface Docker空間的2個CPU線程上運行llama.cpp):
- 零配置設置
- 加載時間約30秒(推理慢,但無API成本),無令牌限制,因為成本低。
- 尋求幫助:如果你對邊緣設備AI感興趣,歡迎合作!
TurboLLM
使用gpt - 4.1 - mini:
- 性能出色,但OpenAI按令牌收費,因此令牌使用受限。
- 可創建自定義cmd處理器,在量子網絡監控代理上運行.NET代碼。
- 支持即時網絡診斷和監控、安全審計、滲透測試(Nmap/Metasploit)。
HugLLM
使用最新的開源模型,在Hugging Face推理API上運行,使用Novita託管的最新模型時表現良好。
測試命令示例
"Give me info on my websites SSL certificate""Check if my server is using quantum safe encyption for communication""Run a comprehensive security audit on my server""Create a cmd processor to .. (what ever you want)"注意,你需要安裝量子網絡監控代理才能運行.NET代碼,這是一個非常靈活和強大的功能,請謹慎使用!
結束語
創建這些模型文件和運行量子網絡監控服務的服務器費用由本人承擔。