🚀 ビジョン用Perceiver IO (学習済み位置埋め込み)
ImageNet(1400万枚の画像、1000クラス)で解像度224x224で事前学習されたPerceiver IOモデルです。このモデルは、Jaegleらによる論文 Perceiver IO: A General Architecture for Structured Inputs & Outputs で紹介され、最初は このリポジトリ で公開されました。
免責事項: Perceiver IOを公開したチームはこのモデルについてモデルカードを作成していないため、このモデルカードはHugging Faceチームによって作成されました。
📚 ドキュメント
モデルの説明
Perceiver IOは、あらゆるモダリティ(テキスト、画像、音声、ビデオなど)に適用できるトランスフォーマーエンコーダモデルです。核心的なアイデアは、あまり大きくない潜在ベクトルの集合(例えば256または512)に自己注意機構を適用し、入力を潜在ベクトルとの交差注意にのみ使用することです。これにより、自己注意機構の時間とメモリ要件が入力のサイズに依存しなくなります。
デコードには、いわゆるデコーダクエリを使用します。これにより、潜在ベクトルの最終的な隠れ状態を柔軟にデコードして、任意のサイズと意味論の出力を生成することができます。画像分類の場合、出力はロジットを含むテンソルで、形状は (batch_size, num_labels) です。
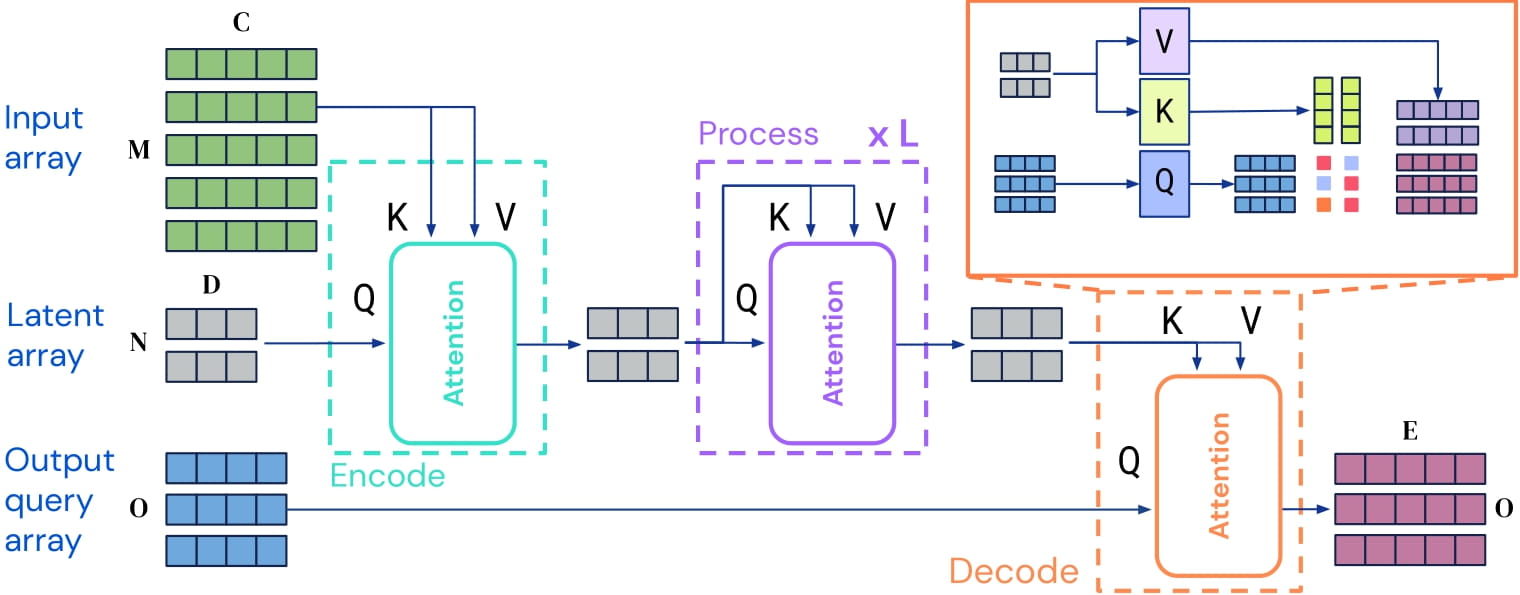
Perceiver IOアーキテクチャ。
自己注意機構の時間とメモリ要件が入力のサイズに依存しないため、Perceiver IOの著者らは、ViTで行われるようなパッチではなく、生のピクセル値に対して直接モデルを学習させることができます。この特定のモデルでは、ピクセル値に学習済みの1次元位置埋め込みを追加するだけなので、画像の2次元構造に関する特権的な情報は与えられていません。
モデルを事前学習することで、画像の内部表現を学習し、それを下流タスクに役立つ特徴抽出に使用することができます。たとえば、ラベル付き画像のデータセットがある場合、分類デコーダを置き換えて標準的な分類器を学習させることができます。
想定される用途と制限
この生のモデルは画像分類に使用できます。興味のあるタスクに関する他の微調整済みバージョンを モデルハブ で探すことができます。
使い方
以下は、このモデルをPyTorchで使用する方法です。
基本的な使用法
from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationLearned
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-learned")
model = PerceiverForImageClassificationLearned.from_pretrained("deepmind/vision-perceiver-learned")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
encoding = feature_extractor(image, return_tensors="pt")
inputs = encoding.pixel_values
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> should print Predicted class: tabby, tabby cat
学習データ
このモデルは、1400万枚の画像と1000クラスからなる ImageNet データセットで事前学習されています。
学習手順
前処理
画像は中央で切り抜かれ、解像度224x224にリサイズされ、RGBチャンネル全体で正規化されます。事前学習中にデータ拡張が使用されたことに注意してください。詳細は 論文 の付録Hを参照してください。
事前学習
ハイパーパラメータの詳細は 論文 の付録Hに記載されています。
評価結果
このモデルは、画像の2次元構造に関する特権的な情報を持たないにもかかわらず、ImageNet-1kで72.7のトップ1精度を達成することができます。
BibTeXエントリと引用情報
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
📄 ライセンス
このモデルはApache-2.0ライセンスの下で提供されています。
| 属性 |
详情 |
| モデルタイプ |
トランスフォーマーエンコーダモデル |
| 学習データ |
ImageNet(1400万枚の画像、1000クラス) |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 複数言語対応
Transformers 複数言語対応