🚀 vit-base-nsfw-detector
このモデルは、約25,000枚の画像(絵画、写真など)でvit-base-patch16-384をファインチューニングしたバージョンです。評価セットでは以下の結果を達成しています。
新着 [07/30]: Stable Diffusionでの使用に特化したNSFW/SFW画像検出用の新しいViTモデルを作成しました(理由については下記の免責事項を参照): AdamCodd/vit-nsfw-stable-diffusion。
免責事項: このモデルは生成画像を考慮して作成されていません!ここで使用されるデータセットには生成画像は含まれておらず、生成画像に対する性能は大幅に低下します。生成画像に特化した別のViTモデルが必要になります。以下は生成画像に対するモデルの実際のスコアです。
- 損失: 0.3682 (↑ 292.95%)
- 正解率: 0.8600 (↓ 10.91%)
- F1: 0.8654
- AUC: 0.9376 (↓ 5.75%)
- 適合率: 0.8350
- 再現率: 0.8980
✨ 主な機能
このモデルは、画像分類タスクに特化しており、主にSFW(セーフコンテンツ)とNSFW(不適切コンテンツ)の2クラス分類を行います。
📦 インストール
このモデルを使用するには、transformersライブラリが必要です。以下のコマンドでインストールできます。
pip install transformers
💻 使用例
基本的な使用法
ローカル画像の使用
from transformers import pipeline
from PIL import Image
img = Image.open("<path_to_image_file>")
predict = pipeline("image-classification", model="AdamCodd/vit-base-nsfw-detector")
predict(img)
リモート画像の使用
from transformers import ViTImageProcessor, AutoModelForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('AdamCodd/vit-base-nsfw-detector')
model = AutoModelForImageClassification.from_pretrained('AdamCodd/vit-base-nsfw-detector')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
Transformers.js (Vanilla JS)の使用
import { pipeline, env } from 'https://cdn.jsdelivr.net/npm/@xenova/transformers@2.17.1';
env.allowLocalModels = false;
const classifier = await pipeline('image-classification', 'AdamCodd/vit-base-nsfw-detector');
async function classifyImage(url) {
try {
const response = await fetch(url);
if (!response.ok) throw new Error('Failed to load image');
const blob = await response.blob();
const image = new Image();
const imagePromise = new Promise((resolve, reject) => {
image.onload = () => resolve(image);
image.onerror = reject;
image.src = URL.createObjectURL(blob);
});
const img = await imagePromise;
const classificationResults = await classifier([img.src]);
console.log('Predicted class: ', classificationResults[0].label);
} catch (error) {
console.error('Error classifying image:', error);
}
}
classifyImage('https://example.com/path/to/image.jpg');
📚 ドキュメント
モデルの説明
Vision Transformer (ViT) は、大規模な画像コレクション(ImageNet-21k)を教師あり学習で事前学習したトランスフォーマーエンコーダモデル(BERTライク)です。画像解像度は224x224ピクセルです。その後、100万枚の画像と1,000クラスからなるImageNet(ILSVRC2012とも呼ばれる)データセットで、より高解像度の384x384でファインチューニングされました。
意図された用途と制限
このモデルは、SFWとNSFWの2クラス分類を行うように訓練されています。モデルは制限的に訓練されており、「セクシー」な画像はNSFWとして分類されます。つまり、画像に乳首や過度の露出がある場合、NSFWとして分類されます。これは正常な動作です。
ただし、モデルは完全ではなく、一部の画像が誤ってNSFWとして分類されることがあります。また、transformers.jsパイプライン内で量子化されたONNXモデルを使用すると、モデルの精度が若干低下します。
訓練と評価データ
詳細情報は後日提供予定です。
訓練手順
訓練ハイパーパラメータ
訓練時に使用されたハイパーパラメータは以下の通りです。
- 学習率: 3e-05
- 訓練バッチサイズ: 32
- 評価バッチサイズ: 32
- シード: 42
- オプティマイザ: Adam (betas=(0.9,0.999), epsilon=1e-08)
- エポック数: 1
訓練結果
- 検証損失: 0.0937
- 正解率: 0.9654
- AUC: 0.9948
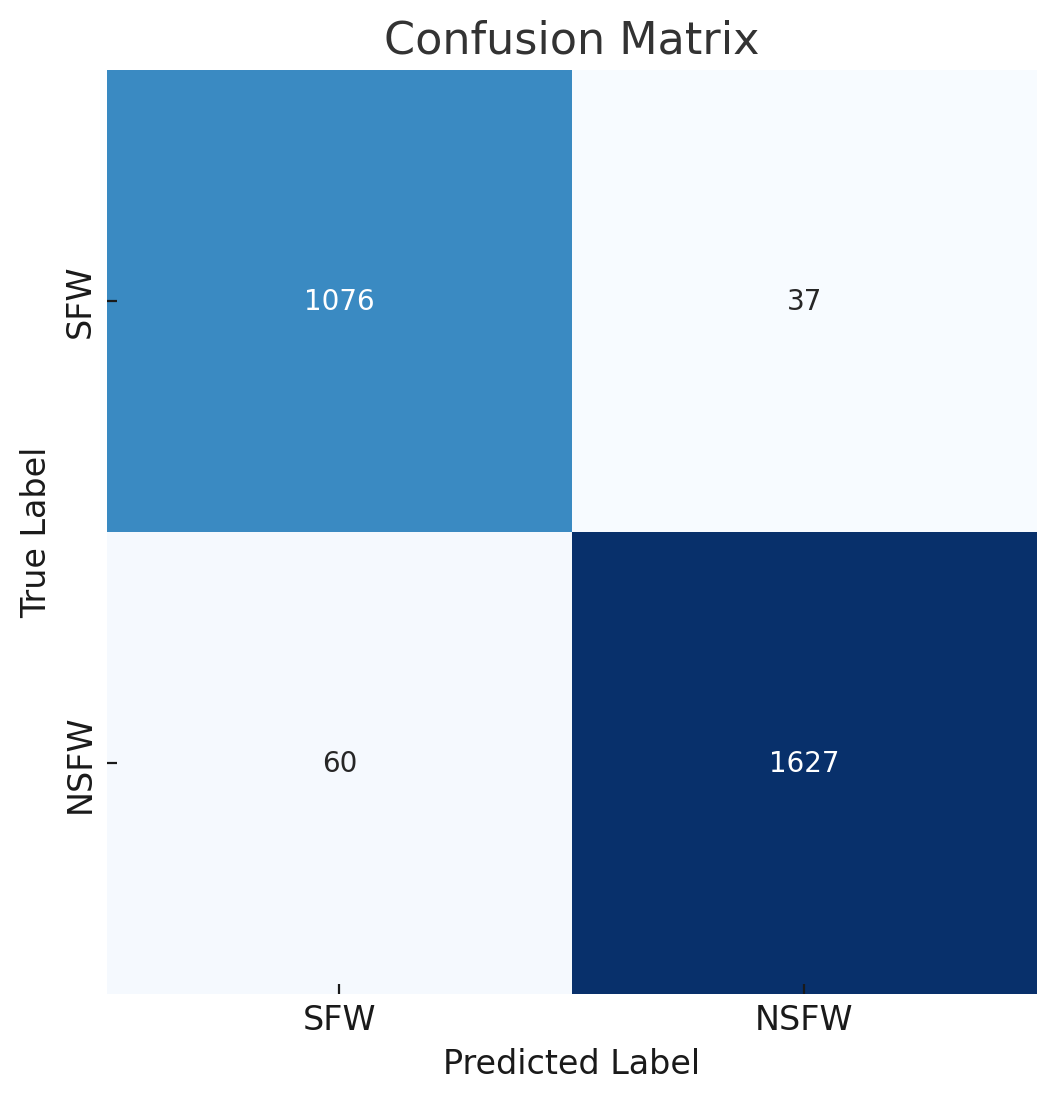
混同行列 (評価):
[1076 37]
[ 60 1627]
フレームワークバージョン
- Transformers 4.36.2
- Evaluate 0.4.1
支援方法
もし私を支援したい場合は、こちらから行えます。
📄 ライセンス
このモデルは、Apache 2.0ライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
{kind=link}
 Transformers 複数言語対応
Transformers 複数言語対応