%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
JA
Florence 2 Base Castollux V0.4
microsoft/Florence-2-baseをファインチューニングした画像キャプション生成モデルで、記述品質とフォーマットの向上に焦点
ダウンロード数 23
リリース時間 : 2/4/2025
モデル概要
このモデルはFlorence-2-baseアーキテクチャをファインチューニングした画像からテキストへのモデルで、画像キャプション生成の品質とフォーマットを特別に最適化しています。<CAPTION>タスクプロンプトを使用してトレーニングされ、詳細で正確な画像キャプション生成に適しています。
モデル特徴
高品質画像キャプション
詳細で正確な画像キャプションを生成し、ベースモデルを上回る性能
フォーマット最適化
キャプションのフォーマットと構造を特別に最適化
タスクプロンプト対応
<CAPTION>タスクプロンプトをサポートし、他のプロンプトタイプにも拡張可能
モデル能力
画像キャプション生成
詳細シーン分析
物体認識と記述
使用事例
コンテンツ生成
自動画像キャプション
画像に対して詳細な記述テキストを生成
ベースモデルよりも正確で詳細な記述を生成
アクセシビリティ支援
視覚障害者向けに画像内容を記述
より包括的なシーン理解を提供
メディア処理
メディアコンテンツ分析
画像内容を自動分析して記述生成
コンテンツ分類と検索に利用可能
🚀 Florence-2-base-Castollux-v0.5
microsoft/Florence-2-base をファインチューニングしたモデルで、画像キャプショニングの品質と書式を改善することを目的としています。
🚀 クイックスタート
このモデルは、画像キャプショニングの品質向上を目指して開発されました。<CAPTION> タスクプロンプトを使用しています。<DETAILED_CAPTION> や <MORE_DETAILED_CAPTION> でのトレーニングは、<CAPTION> と比べて品質に大きな違いをもたらさないようです。
✨ 主な機能
- 画像キャプショニングの品質と書式を改善
<CAPTION>タスクプロンプトを使用- 512 T5トークンを超えるキャプションをフィルタリング
📚 ドキュメント
モデル評価
選択された画像は特別に選ばれたものではなく、ランダムに選択された評価分割の最初のバッチの画像です。
| ソース画像 | 正解 | 元のモデルの予測 | ファインチューニング後のモデルの予測 |
|---|---|---|---|
 |
左側に2色の壁が見え、上部はオレンジ色、下部は青色で、2色を分ける細い水平線があります。壁のオレンジ色部分には、垂直な金属の棒が付いた小さな正方形の窓が埋め込まれています。オレンジ色のパイプが壁のオレンジ色部分を垂直に下っています。この壁の右側には、質感のある薄灰色の壁があります。灰色のパイプがこの壁を垂直に下っています。灰色の柱に取り付けられた赤い八角形のストップサインが、灰色の壁の前に位置しています。さらに右側には、灰色の壁に青いシャッター付きの窓があります。窓の下の壁には、装飾的な濃い青色の手すりが取り付けられています。 | 建物の横にあるストップサイン。 | 白い文字で "STOP" と書かれた赤い八角形のストップサインが、画像の左側に位置し、薄いベージュ色のスタッコ壁に取り付けられています。ストップサインの右側には、ペンキが剥がれた青いドアと金属の棒、そして右側に装飾要素のある黒い鍛鉄のバルコニーがあります。壁は質感があり、亀裂や欠陥が見えます。白いパイプが壁のオレンジ色と青色の部分の間を垂直に下っています。オレンジ色の部分の中には、暗い金属の棒が付いた小さな長方形の窓が見えます。 |
 |
茶色と白の犬が、小さな白い花が咲いた緑の葉っぱの茂みの中に立っています。犬は画像の下部中央に位置し、少し左を向いています。植物の茂みは前景と中景全体に広がり、濃い緑のカーペットを作り出しています。犬と下部の畑の後ろには、同じような緑の葉っぱの茂みが覆った急な土手が立ち上がっています。細い暗い土の小道または小川が中景を水平に横切っています。画像の右側のこの小道の端には、倒れた丸太があります。上の土手の葉は、前景のものより少し小さく、密に詰まっているように見えます。上の土手の右側には、細い裸の枝が見えます。 | 豊かな緑の草原の真ん中に犬が座っています。 | 茶色の耳が垂れた茶色と白の犬が、画像の中央に位置し、少し左を向き、舌を出しています。犬は小さな白い花が咲いた緑の葉っぱの茂みに囲まれています。犬の後ろと右側には、葉っぱで覆われた濃い緑の壁があります。前景の地面は土の小道または道のように見えます。画像の照明は柔らかく自然です。 |
 |
非常に高い滝が、暗い灰色の岩の崖の中央を流れ落ち、底の暗い水に注ぎ込まれています。崖には質感があり、雪の斑点があります。崖の頂上と崖の表面にはまばらな木があります。暗い水は崖と滝を反射しています。空は灰色です。 | 水域の真ん中にある大きな滝。 | 高い滝が画像の中央の岩の崖の面を流れ落ち、水は暗い青色に見え、上の空を反射しています。崖の面は灰色と茶色の岩で構成され、目に見える亀裂と隙間があります。崖の頂上には、濃い緑の木の密林が見えます。空は曇りで灰色です。前景の水は暗い青色です。 |
 |
白い頭、青い目、開いたオレンジ色の口、そして青、オレンジ、黄、白の多彩な鱗を持つ鮮やかな色の魚の乗り物が、画像の中央に位置し、黒い台座に取り付けられています。魚の乗り物の後ろには、アーチ形の開口部があるクリーム色の装飾的な建築要素があります。魚の乗り物の左側には、いくつかの金属の鍋やフライパンがあり、大きな青いエナメルの鍋が倒れて、赤い取っ手が見えています。魚の乗り物の右側には、いくつかの黒いバケツが積み重ねられています。魚の乗り物とバケツは赤い台の上に置かれています。背景には、白い枠の窓がある風化した青い木の壁があり、壁の左側には装飾的な彫刻がある古い木のドアがあります。クリーム色の建築要素に取り付けられた白いラベルには文字が見えます。 | テーブルの上に置かれた大きな魚の彫像。 | オレンジ、白、青の鱗を持つ大きな金属の魚の彫刻が、画像の中央に位置し、少し右を向いています。魚は黒い目と黄色のくちばしを持っています。黒い金属の台に取り付けられています。魚の左側には、青い縁と赤い取っ手のある赤いバケツがあります。さらに左には白いバケツがあります。前景には、黒いプラスチックのバケツの山があります。魚とバケツの後ろには、他のいくつかの金属のバケツや容器があります。背景には、緑の木の外壁と複数の窓ガラスがある白い窓のある建物が見えます。左側には木のドアが見え、その上に金属の手すりがあります。建物の側面には、黒い文字が書かれた小さな白い看板が取り付けられています。 |
 |
茶色の髪と茶色の目を持つ少女が、手を腰に当てて立ち、観察者の方を微笑みながら見ています。彼女は右側に花が付いた薄い青いヘッドバンドを着用しています。薄い青い袖なしのトップと、黄色、ピンク、紫、青の淡い色調のパステル色の長いスカートを着ています。彼女は裸足で、平らな白い背景の上に立っています。 | 髪に花を挿したドレスを着た少女。 | 白い肌と茶色の目を持つ少女が、微笑みながら観察者の方を見ています。中央に大きな青い花が付いた薄い青いヘッドバンド、細いストラップのある白い袖なしのドレス、そして虹色のタulleスカートを着ています。彼女の手は腰に置かれ、足は裸です。背景は平らな白い壁です。 |
 |
茶色の波状の髪と白い肌を持つ女性が、黄色の肘掛け椅子に座っています。彼女は細いストラップのある赤いシークエンスのドレスと黒いハイヒールの靴を着ています。彼女の脚は膝で交差し、右手は椅子の肘掛けに載っています。彼女は茶色の目で観察者の方を見ており、アイライナーや口紅などのメイクをしています。肘掛け椅子の左側には、小さな丸い白いテーブルがあり、その上にはピンク、紫、黄色の花が入ったオレンジ色の花瓶が置かれています。女性とテーブルの後ろには、白い垂直のブラインドと青いカーテンがあります。ブラインドとカーテンの後ろの壁は、薄い灰色または青色に見えます。床の一部が見え、薄い色に見えます。前景には、緑色のベッドまたはソファの下部が見えます。画像の照明はスタジオのようで、女性とその周辺に焦点が合っています。 | 赤いドレスを着た女性が黄色の椅子に座っています。 | 長い茶色の波状の髪を持つ女性が、黄色の肘掛け椅子に座っています。彼女は細いストラップのある赤い袖なしのドレスを着ています。彼女の脚は交差し、黒いハイヒールの靴を履いています。肘掛け椅子は湾曲した背もたれと肘掛けを持っています。肘掛け椅子の左側には、小さな丸い白いテーブルがあります。テーブルの上には、ピンクと白の花が入った透明なガラスの花瓶があります。花瓶の後ろには、白い垂直のブラインドと右側に暗い青いカーテンが付いた窓があります。背景は薄い青い壁です。 |
 |
左上隅にいくつかの薄い白い雲がある澄んだ青い空が、波紋と波の模様が見えるターコイズ色と透明な海の上にあります。白い泡が立つ小さな波が、前景の白い砂浜で砕けています。水は非常に透明で、砂の底が見えます。水平線はまっすぐで、海と空を分けています。 | 澄んだ青い水と白い砂のある砂浜。 | ターコイズ色の水域が画面の大部分を占め、前景の砂浜に穏やかな波が打ち寄せています。水は鮮やかな緑色で、波は白く泡立っています。砂は薄いベージュ色です。水平線は水と砂浜の間の遠くに見えます。上の空は澄んだ青で、いくつかの薄い白い雲が散らばっています。 |
 |
風景写真には、明るい日光に照らされた岩の崖の面を流れ落ちる滝があり、滝の底に虹が見え、滝の底の近くに2人の小さな人物が立っています。崖の面は主に茶色と灰色の岩で、緑の植生の斑点があります。日当たりの良い崖の面の後ろには、暗い影のある山脈があり、目に見える岩の層理とまばらな植生があります。左の遠い背景には、曇った空の下でハーフドームの独特な形が見えます。前景は、明るく照らされた滝と崖の面と対照的に、濃い緑の森の木でいっぱいです。上の空はほとんど曇っており、暗い灰色の雲がありますが、いくつかの明るい部分が見えています。 | 山脈の真ん中にある大きな滝。 | 滝が画像の右側の岩の崖の面を流れ落ち、水は黄色と白に見えます。崖の面は灰色と茶色の岩で構成され、頂上と側面に緑の植生の斑点があります。滝は崖の面の中央に位置し、濃い緑の木の密林に囲まれています。背景には、大きな山脈が見え、暗い緑の針葉樹で覆われています。上の空は曇っており、暗い灰色と白の雲があります。全体的なシーンは劇的で、滝とその下の森に焦点が合っています。 |
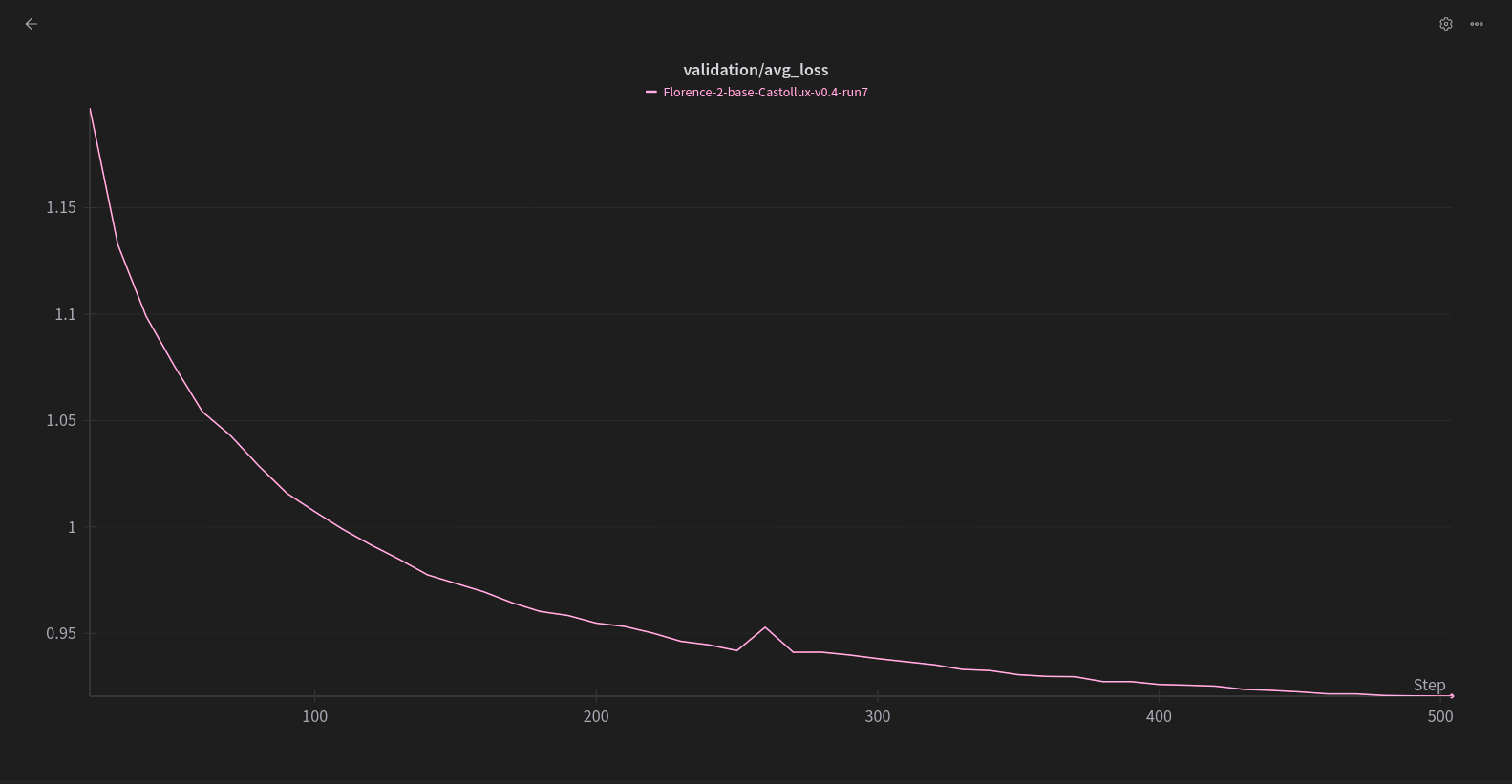
トレーニング設定
Florence-2ner を使用し、以下の設定と約17Kの画像でトレーニングされました。
{
"model_name": "microsoft/Florence-2-base",
"task_prompt": "<CAPTION>",
"dataset_path": "./0000_Datasets/Gemini-512lim",
"wandb_project_name": "Florence-2-base",
"run_name": "Florence-2-base-Castollux-v0.4-run7",
"epochs": 2,
"optimizer": "CAME",
"learning_rate": 5e-6,
"lr_scheduler": "REX",
"gradient_checkpointing": true,
"freeze_vision": false,
"freeze_language": false,
"freeze_other": false,
"train_batch_size": 8,
"eval_batch_size": 8,
"gradient_accumulation_steps": 8,
"clip_grad_norm": 1,
"weight_decay": 1e-2,
"save_total_limit": 3,
"save_steps": 10,
"eval_steps": 10,
"warmup_steps": 10,
"eval_split_ratio": 0.05,
"seed": 42,
"filtering_processes": 128,
"attn_implementation": "sdpa"
}
引用
引用を表示
@misc{xiao2023florence2advancingunifiedrepresentation,
title={Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks},
author={Bin Xiao and Haiping Wu and Weijian Xu and Xiyang Dai and Houdong Hu and Yumao Lu and Michael Zeng and Ce Liu and Lu Yuan},
year={2023},
eprint={2311.06242},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2311.06242},
}
@misc{wolf2020huggingfacestransformersstateoftheartnatural,
title={HuggingFace's Transformers: State-of-the-art Natural Language Processing},
author={Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush},
year={2020},
eprint={1910.03771},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/1910.03771},
}
@misc{dao2023flashattention2fasterattentionbetter,
title={FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Tri Dao},
year={2023},
eprint={2307.08691},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2307.08691},
}
@misc{luo2023cameconfidenceguidedadaptivememory,
title={CAME: Confidence-guided Adaptive Memory Efficient Optimization},
author={Yang Luo and Xiaozhe Ren and Zangwei Zheng and Zhuo Jiang and Xin Jiang and Yang You},
year={2023},
eprint={2307.02047},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2307.02047},
}
@misc{chen2021rexrevisitingbudgetedtraining,
title={REX: Revisiting Budgeted Training with an Improved Schedule},
author={John Chen and Cameron Wolfe and Anastasios Kyrillidis},
year={2021},
eprint={2107.04197},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2107.04197},
}
@misc{geminiteam2024geminifamilyhighlycapable,
title={Gemini: A Family of Highly Capable Multimodal Models},
author={Gemini Team and Rohan Anil and Sebastian Borgeaud and Jean-Baptiste Alayrac and Jiahui Yu and Radu Soricut and Johan Schalkwyk and Andrew M. Dai and Anja Hauth and Katie Millican and David Silver and Melvin Johnson and Ioannis Antonoglou and Julian Schrittwieser and Amelia Glaese and Jilin Chen and Emily Pitler and Timothy Lillicrap and Angeliki Lazaridou and Orhan Firat and James Molloy and Michael Isard and Paul R. Barham and Tom Hennigan and Benjamin Lee and Fabio Viola and Malcolm Reynolds and Yuanzhong Xu and Ryan Doherty and Eli Collins and Clemens Meyer and Eliza Rutherford and Erica Moreira and Kareem Ayoub and Megha Goel and Jack Krawczyk and Cosmo Du and Ed Chi and Heng-Tze Cheng and Eric Ni and Purvi Shah and Patrick Kane and Betty Chan and Manaal Faruqui and Aliaksei Severyn and Hanzhao Lin and YaGuang Li and Yong Cheng and Abe Ittycheriah and Mahdis Mahdieh and Mia Chen and Pei Sun and Dustin Tran and Sumit Bagri and Balaji Lakshminarayanan and Jeremiah Liu and Andras Orban and Fabian Güra and Hao Zhou and Xinying Song and Aurelien Boffy and Harish Ganapathy and Steven Zheng and HyunJeong Choe and Ágoston Weisz and Tao Zhu and Yifeng Lu and Siddharth Gopal and Jarrod Kahn and Maciej Kula and Jeff Pitman and Rushin Shah and Emanuel Taropa and Majd Al Merey and Martin Baeuml and Zhifeng Chen and Laurent El Shafey and Yujing Zhang and Olcan Sercinoglu and George Tucker and Enrique Piqueras and Maxim Krikun and Iain Barr and Nikolay Savinov and Ivo Danihelka and Becca Roelofs and Anaïs White and Anders Andreassen and Tamara von Glehn and Lakshman Yagati and Mehran Kazemi and Lucas Gonzalez and Misha Khalman and Jakub Sygnowski and Alexandre Frechette and Charlotte Smith and Laura Culp and Lev Proleev and Yi Luan and Xi Chen and James Lottes and Nathan Schucher and Federico Lebron and Alban Rrustemi and Natalie Clay and Phil Crone and Tomas Kocisky and Jeffrey Zhao and Bartek Perz and Dian Yu and Heidi Howard and Adam Bloniarz and Jack W. Rae and Han Lu and Laurent Sifre and Marcello Maggioni and Fred Alcober and Dan Garrette and Megan Barnes and Shantanu Thakoor and Jacob Austin and Gabriel Barth-Maron and William Wong and Rishabh Joshi and Rahma Chaabouni and Deeni Fatiha and Arun Ahuja and Gaurav Singh Tomar and Evan Senter and Martin Chadwick and Ilya Kornakov and Nithya Attaluri and Iñaki Iturrate and Ruibo Liu and Yunxuan Li and Sarah Cogan and Jeremy Chen and Chao Jia and Chenjie Gu and Qiao Zhang and Jordan Grimstad and Ale Jakse Hartman and Xavier Garcia and Thanumalayan Sankaranarayana Pillai and Jacob Devlin and Michael Laskin and Diego de Las Casas and Dasha Valter and Connie Tao and Lorenzo Blanco and Adrià Puigdomènech Badia and David Reitter and Mianna Chen and Jenny Brennan and Clara Rivera and Sergey Brin and Shariq Iqbal and Gabriela Surita and Jane Labanowski and Abhi Rao and Stephanie Winkler and Emilio Parisotto and Yiming Gu and Kate Olszewska and Ravi Addanki and Antoine Miech and Annie Louis and Denis Teplyashin and Geoff Brown and Elliot Catt and Jan Balaguer and Jackie Xiang and Pidong Wang and Zoe Ashwood and Anton Briukhov and Albert Webson and Sanjay Ganapathy and Smit Sanghavi and Ajay Kannan and Ming-Wei Chang and Axel Stjerngren and Josip Djolonga and Yuting Sun and Ankur Bapna and Matthew Aitchison and Pedram Pejman and Henryk Michalewski and Tianhe Yu and Cindy Wang and Juliette Love and Junwhan Ahn and Dawn Bloxwich and Kehang Han and Peter Humphreys and Thibault Sellam and James Bradbury and Varun Godbole and Sina Samangooei and Bogdan Damoc and Alex Kaskasoli and Sébastien M. R. Arnold and Vijay Vasudevan and Shubham Agrawal and Jason Riesa and Dmitry Lepikhin and Richard Tanburn and Srivatsan Srinivasan and Hyeontaek Lim and Sarah Hodkinson and Pranav Shyam and Johan Ferret and Steven Hand and Ankush Garg and Tom Le Paine and Jian Li and Yujia Li and Minh Giang and Alexander Neitz and Zaheer Abbas and Sarah York and Machel Reid and Elizabeth Cole and Aakanksha Chowdhery and Dipanjan Das and Dominika Rogozińska and Vitaliy Nikolaev and Pablo Sprechmann and Zachary Nado and Lukas Zilka and Flavien Prost and Luheng He and Marianne Monteiro and Gaurav Mishra and Chris Welty and Josh Newlan and Dawei Jia and Miltiadis Allamanis and Clara Huiyi Hu and Raoul de Liedekerke and Justin Gilmer and Carl Saroufim and Shruti Rijhwani and Shaobo Hou and Disha Shrivastava and Anirudh Baddepudi and Alex Goldin and Adnan Ozturel and Albin Cassirer and Yunhan Xu and Daniel Sohn and Devendra Sachan and Reinald Kim Amplayo and Craig Swanson and Dessie Petrova and Shashi Narayan and Arthur Guez and Siddhartha Brahma and Jessica Landon and Miteyan Patel and Ruizhe Zhao and Kevin Villela and Luyu Wang and Wenhao Jia and Matthew Rahtz and Mai Giménez and Legg Yeung and James Keeling and Petko Georgiev and Diana Mincu and Boxi Wu and Salem Haykal and Rachel Saputro and
}
Clip Vit Large Patch14
CLIPはOpenAIによって開発された視覚-言語モデルで、コントラスティブラーニングを通じて画像とテキストを共有の埋め込み空間にマッピングし、ゼロショット画像分類をサポートします
画像生成テキスト
C
openai
44.7M
1,710
Clip Vit Base Patch32
CLIPはOpenAIが開発したマルチモーダルモデルで、画像とテキストの関係を理解し、ゼロショット画像分類タスクをサポートします。
画像生成テキスト
C
openai
14.0M
666
Siglip So400m Patch14 384
Apache-2.0
SigLIPはWebLiデータセットで事前学習された視覚言語モデルで、改良されたシグモイド損失関数を採用し、画像-テキストマッチングタスクを最適化しています。
画像生成テキスト Transformers
Transformers
S
google
6.1M
526
Clip Vit Base Patch16
CLIPはOpenAIが開発したマルチモーダルモデルで、コントラスティブラーニングにより画像とテキストを共有の埋め込み空間にマッピングし、ゼロショット画像分類能力を実現します。
画像生成テキスト
C
openai
4.6M
119
Blip Image Captioning Base
Bsd-3-clause
BLIPは先進的な視覚-言語事前学習モデルで、画像キャプション生成タスクに優れており、条件付きおよび無条件のテキスト生成をサポートします。
画像生成テキスト Transformers
B
Salesforce
2.8M
688
Blip Image Captioning Large
Bsd-3-clause
BLIPは統一された視覚-言語事前学習フレームワークで、画像キャプション生成タスクに優れており、条件付きおよび無条件の画像キャプション生成をサポートします。
画像生成テキスト Transformers
B
Salesforce
2.5M
1,312
Openvla 7b
MIT
OpenVLA 7BはOpen X-Embodimentデータセットでトレーニングされたオープンソースの視覚-言語-動作モデルで、言語命令とカメラ画像に基づいてロボットの動作を生成できます。
画像生成テキスト Transformers 英語
O
openvla
1.7M
108
Llava V1.5 7b
LLaVAはオープンソースのマルチモーダルチャットボットで、LLaMA/Vicunaをファインチューニングし、画像とテキストのインタラクションをサポートします。
画像生成テキスト Transformers
L
liuhaotian
1.4M
448
Vit Gpt2 Image Captioning
Apache-2.0
これはViTとGPT2アーキテクチャに基づく画像記述生成モデルで、入力画像に対して自然言語の記述を生成することができます。
画像生成テキスト Transformers
V
nlpconnect
939.88k
887
Blip2 Opt 2.7b
MIT
BLIP-2は画像エンコーダーと大規模言語モデルを組み合わせた視覚言語モデルで、画像からテキストを生成するタスクに使用されます。
画像生成テキスト Transformers 英語
B
Salesforce
867.78k
359
おすすめAIモデル
Llama 3 Typhoon V1.5x 8b Instruct
タイ語専用に設計された80億パラメータの命令モデルで、GPT-3.5-turboに匹敵する性能を持ち、アプリケーションシナリオ、検索拡張生成、制限付き生成、推論タスクを最適化
大規模言語モデル Transformers 複数言語対応
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-TinyはSODAデータセットでトレーニングされた超小型対話モデルで、エッジデバイス推論向けに設計されており、体積はCosmo-3Bモデルの約2%です。
対話システム Transformers 英語
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
RoBERTaアーキテクチャに基づく中国語抽出型QAモデルで、与えられたテキストから回答を抽出するタスクに適しています。
質問応答システム 中国語
R
uer
2,694
98