🚀 Florence-2-base-Castollux-v0.4
這是一個基於microsoft/Florence-2-base的微調模型,旨在提升圖像字幕的質量和格式。
數據集和基礎信息
| 屬性 |
詳情 |
| 數據集 |
PJMixers-Images/Castollux-Dataset |
| 語言 |
英文 |
| 基礎模型 |
microsoft/Florence-2-base |
| 任務標籤 |
image-to-text |
| 庫名稱 |
transformers |
| 新版本 |
PJMixers-Images/Florence-2-base-Castollux-v0.5 |
🚀 快速開始
本模型使用 <CAPTION> 任務提示進行訓練。在實驗中發現,使用 <DETAILED_CAPTION> 或 <MORE_DETAILED_CAPTION> 進行訓練,與使用 <CAPTION> 相比,在質量上沒有明顯差異。在 v0.1 和 v0.2 版本中,僅過濾掉包含超過 1000 個 Florence-2 標記的字幕;從 v0.3 版本開始,將過濾掉任何超過 512 個 T5 標記的字幕。
✨ 主要特性
- 針對性優化:針對圖像字幕任務對
microsoft/Florence-2-base 進行微調,提升字幕生成質量。
- 多場景適用:在多種不同類型的圖像上進行評估,展示了良好的泛化能力。
📚 詳細文檔
模型評估
選取的評估圖像並非經過挑選,而是來自隨機選擇的評估分割中的第一批圖像。以下是部分評估結果:
| 源圖像 |
真實標籤 |
原始模型預測 |
微調模型預測 |
 |
左側可見一面雙色牆,上半部分為橙色,下半部分為藍色,中間有一條細的水平線分隔兩種顏色。橙色部分的牆上嵌入了一個帶有垂直金屬條的小方形窗戶。一根淺橙色的管道垂直向下延伸在橙色部分的牆上,靠近顏色分界線。這面牆的右側是一面有紋理的淺灰色牆。一根灰色管道垂直向下延伸在這面牆上。一個帶有白色字母“STOP”的紅色八角形停車標誌安裝在一根灰色杆子上,位於灰色牆的前面。再往右,一個藍色百葉窗窗戶嵌入在灰色牆上。窗戶下方的牆上附著著一個裝飾性的深藍色欄杆。 |
一個停車標誌位於建築物的一側。 |
一個帶有白色文字“STOP”的紅色八角形停車標誌位於圖像左側,附著在淺米色灰泥牆上。停車標誌的右側是一扇關閉的藍色門,有剝落的油漆和金屬條,右側有一個黑色鍛鐵陽臺,帶有裝飾元素。牆壁有紋理,可見裂縫和瑕疵。一根白色管道垂直向下延伸在橙色和藍色部分的牆之間。橙色部分內可見一個帶有深色金屬條的小矩形窗戶。 |
 |
一隻棕色和白色相間、耳朵下垂、嘴巴張開的狗站在一片茂密的綠葉植物和小白花的田野中。狗位於圖像的中下部,稍微向左看。植物田野貫穿前景和中景,形成一片茂密的綠色地毯。在狗和下部田野的後面,一個更陡峭的山坡上覆蓋著類似的綠葉植物,填滿了圖像的上部。一條狹窄、深色的土路或小溪水平穿過中景,將下部田野與較高的山坡分開。一根倒下的原木沿著圖像右側的小路邊緣放置。較高山坡上的葉子看起來比前景中的葉子略小且更密集。右側可見一些細的光禿禿的樹枝。 |
一隻狗坐在一片鬱鬱蔥蔥的綠色田野中間。 |
一隻耳朵下垂的棕色和白色相間的狗位於圖像中心,稍微向左看,舌頭伸出來。狗被一片綠葉植物和小白花的田野包圍。狗的後面和右側是一堵覆蓋著綠葉的茂密綠色牆壁。前景中的地面似乎是一條土路或小徑。圖像中的光線柔和自然。 |
| ... |
... |
... |
... |
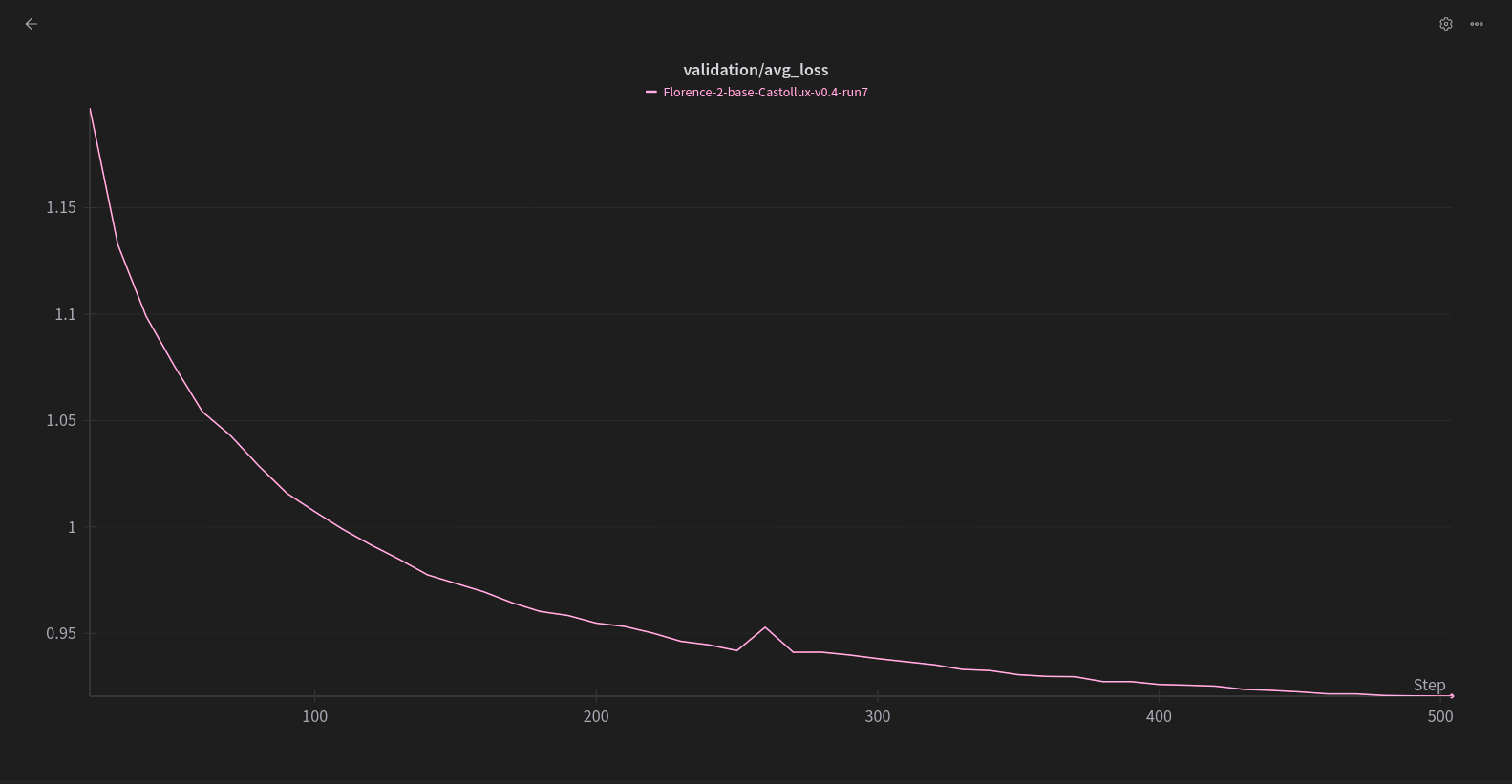
評估損失曲線如下:
訓練設置
使用 Florence-2ner 進行訓練,配置如下,使用了約 17K 張圖像:
{
"model_name": "microsoft/Florence-2-base",
"task_prompt": "<CAPTION>",
"dataset_path": "./0000_Datasets/Gemini-512lim",
"wandb_project_name": "Florence-2-base",
"run_name": "Florence-2-base-Castollux-v0.4-run7",
"epochs": 2,
"optimizer": "CAME",
"learning_rate": 5e-6,
"lr_scheduler": "REX",
"gradient_checkpointing": true,
"freeze_vision": false,
"freeze_language": false,
"freeze_other": false,
"train_batch_size": 8,
"eval_batch_size": 8,
"gradient_accumulation_steps": 8,
"clip_grad_norm": 1,
"weight_decay": 1e-2,
"save_total_limit": 3,
"save_steps": 10,
"eval_steps": 10,
"warmup_steps": 10,
"eval_split_ratio": 0.05,
"seed": 42,
"filtering_processes": 128,
"attn_implementation": "sdpa"
}
引用信息
顯示引用
@misc{xiao2023florence2advancingunifiedrepresentation,
title={Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks},
author={Bin Xiao and Haiping Wu and Weijian Xu and Xiyang Dai and Houdong Hu and Yumao Lu and Michael Zeng and Ce Liu and Lu Yuan},
year={2023},
eprint={2311.06242},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2311.06242},
}
@misc{wolf2020huggingfacestransformersstateoftheartnatural,
title={HuggingFace's Transformers: State-of-the-art Natural Language Processing},
author={Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush},
year={2020},
eprint={1910.03771},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/1910.03771},
}
...
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多種語言
Transformers 支持多種語言