🚀 Florence-2-base-Castollux-v0.4
这是一个基于microsoft/Florence-2-base的微调模型,旨在提升图像字幕的质量和格式。
数据集和基础信息
| 属性 |
详情 |
| 数据集 |
PJMixers-Images/Castollux-Dataset |
| 语言 |
英文 |
| 基础模型 |
microsoft/Florence-2-base |
| 任务标签 |
image-to-text |
| 库名称 |
transformers |
| 新版本 |
PJMixers-Images/Florence-2-base-Castollux-v0.5 |
🚀 快速开始
本模型使用 <CAPTION> 任务提示进行训练。在实验中发现,使用 <DETAILED_CAPTION> 或 <MORE_DETAILED_CAPTION> 进行训练,与使用 <CAPTION> 相比,在质量上没有明显差异。在 v0.1 和 v0.2 版本中,仅过滤掉包含超过 1000 个 Florence-2 标记的字幕;从 v0.3 版本开始,将过滤掉任何超过 512 个 T5 标记的字幕。
✨ 主要特性
- 针对性优化:针对图像字幕任务对
microsoft/Florence-2-base 进行微调,提升字幕生成质量。
- 多场景适用:在多种不同类型的图像上进行评估,展示了良好的泛化能力。
📚 详细文档
模型评估
选取的评估图像并非经过挑选,而是来自随机选择的评估分割中的第一批图像。以下是部分评估结果:
| 源图像 |
真实标签 |
原始模型预测 |
微调模型预测 |
 |
左侧可见一面双色墙,上半部分为橙色,下半部分为蓝色,中间有一条细的水平线分隔两种颜色。橙色部分的墙上嵌入了一个带有垂直金属条的小方形窗户。一根浅橙色的管道垂直向下延伸在橙色部分的墙上,靠近颜色分界线。这面墙的右侧是一面有纹理的浅灰色墙。一根灰色管道垂直向下延伸在这面墙上。一个带有白色字母“STOP”的红色八角形停车标志安装在一根灰色杆子上,位于灰色墙的前面。再往右,一个蓝色百叶窗窗户嵌入在灰色墙上。窗户下方的墙上附着着一个装饰性的深蓝色栏杆。 |
一个停车标志位于建筑物的一侧。 |
一个带有白色文字“STOP”的红色八角形停车标志位于图像左侧,附着在浅米色灰泥墙上。停车标志的右侧是一扇关闭的蓝色门,有剥落的油漆和金属条,右侧有一个黑色锻铁阳台,带有装饰元素。墙壁有纹理,可见裂缝和瑕疵。一根白色管道垂直向下延伸在橙色和蓝色部分的墙之间。橙色部分内可见一个带有深色金属条的小矩形窗户。 |
 |
一只棕色和白色相间、耳朵下垂、嘴巴张开的狗站在一片茂密的绿叶植物和小白花的田野中。狗位于图像的中下部,稍微向左看。植物田野贯穿前景和中景,形成一片茂密的绿色地毯。在狗和下部田野的后面,一个更陡峭的山坡上覆盖着类似的绿叶植物,填满了图像的上部。一条狭窄、深色的土路或小溪水平穿过中景,将下部田野与较高的山坡分开。一根倒下的原木沿着图像右侧的小路边缘放置。较高山坡上的叶子看起来比前景中的叶子略小且更密集。右侧可见一些细的光秃秃的树枝。 |
一只狗坐在一片郁郁葱葱的绿色田野中间。 |
一只耳朵下垂的棕色和白色相间的狗位于图像中心,稍微向左看,舌头伸出来。狗被一片绿叶植物和小白花的田野包围。狗的后面和右侧是一堵覆盖着绿叶的茂密绿色墙壁。前景中的地面似乎是一条土路或小径。图像中的光线柔和自然。 |
| ... |
... |
... |
... |
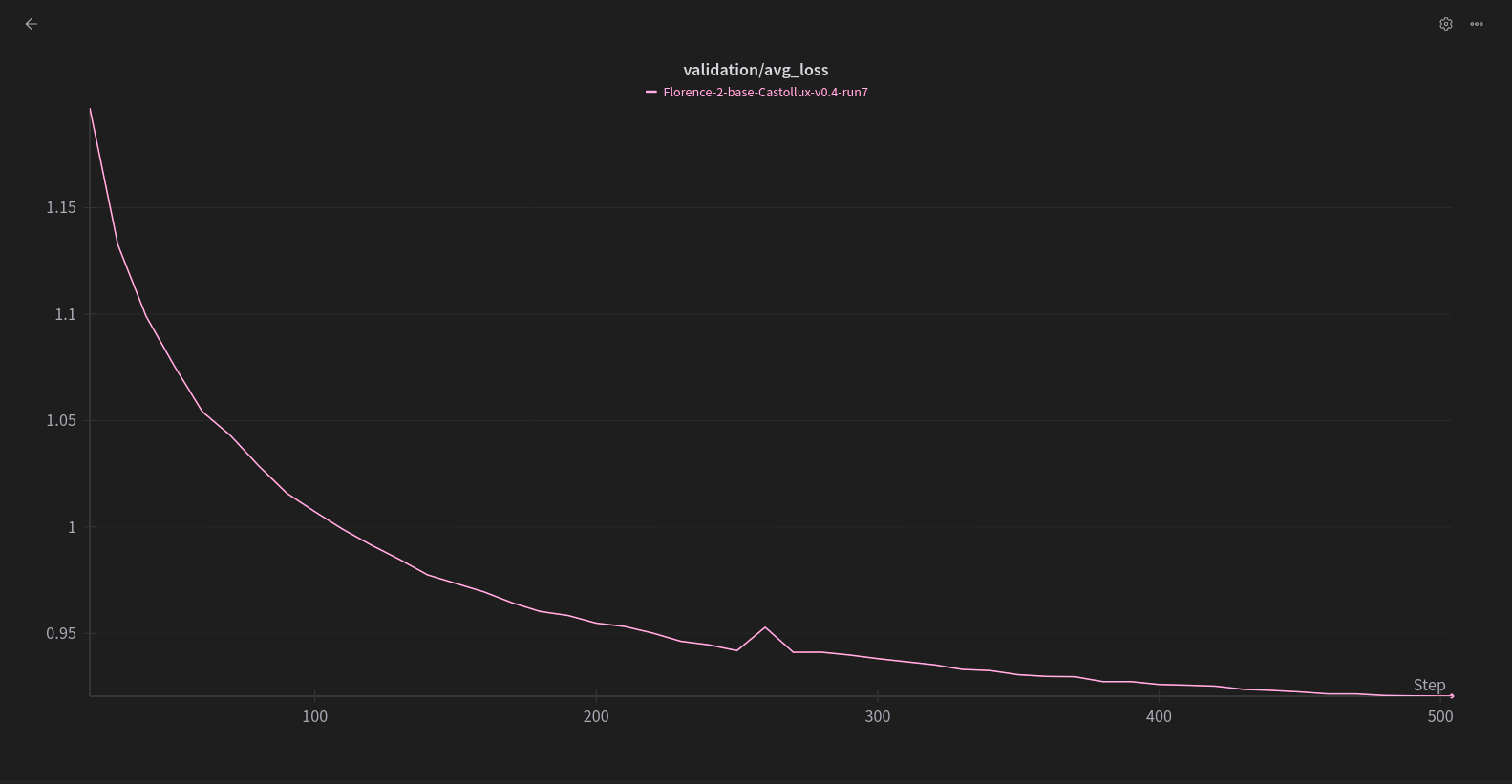
评估损失曲线如下:
训练设置
使用 Florence-2ner 进行训练,配置如下,使用了约 17K 张图像:
{
"model_name": "microsoft/Florence-2-base",
"task_prompt": "<CAPTION>",
"dataset_path": "./0000_Datasets/Gemini-512lim",
"wandb_project_name": "Florence-2-base",
"run_name": "Florence-2-base-Castollux-v0.4-run7",
"epochs": 2,
"optimizer": "CAME",
"learning_rate": 5e-6,
"lr_scheduler": "REX",
"gradient_checkpointing": true,
"freeze_vision": false,
"freeze_language": false,
"freeze_other": false,
"train_batch_size": 8,
"eval_batch_size": 8,
"gradient_accumulation_steps": 8,
"clip_grad_norm": 1,
"weight_decay": 1e-2,
"save_total_limit": 3,
"save_steps": 10,
"eval_steps": 10,
"warmup_steps": 10,
"eval_split_ratio": 0.05,
"seed": 42,
"filtering_processes": 128,
"attn_implementation": "sdpa"
}
引用信息
显示引用
@misc{xiao2023florence2advancingunifiedrepresentation,
title={Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks},
author={Bin Xiao and Haiping Wu and Weijian Xu and Xiyang Dai and Houdong Hu and Yumao Lu and Michael Zeng and Ce Liu and Lu Yuan},
year={2023},
eprint={2311.06242},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2311.06242},
}
@misc{wolf2020huggingfacestransformersstateoftheartnatural,
title={HuggingFace's Transformers: State-of-the-art Natural Language Processing},
author={Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush},
year={2020},
eprint={1910.03771},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/1910.03771},
}
...
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Transformers 支持多种语言
Transformers 支持多种语言