🚀 文書理解モデル (DocLayNet baseで段落レベルで微調整されたLiLT base)
このモデルは、nielsr/lilt-xlm-roberta-base を DocLayNet base データセットで微調整したものです。評価セットでは以下の結果を達成しています。
🚀 クイックスタート
このモデルは文書理解タスクに特化しており、段落レベルでの解析に適しています。以下に、このモデルの概要と使い方を説明します。
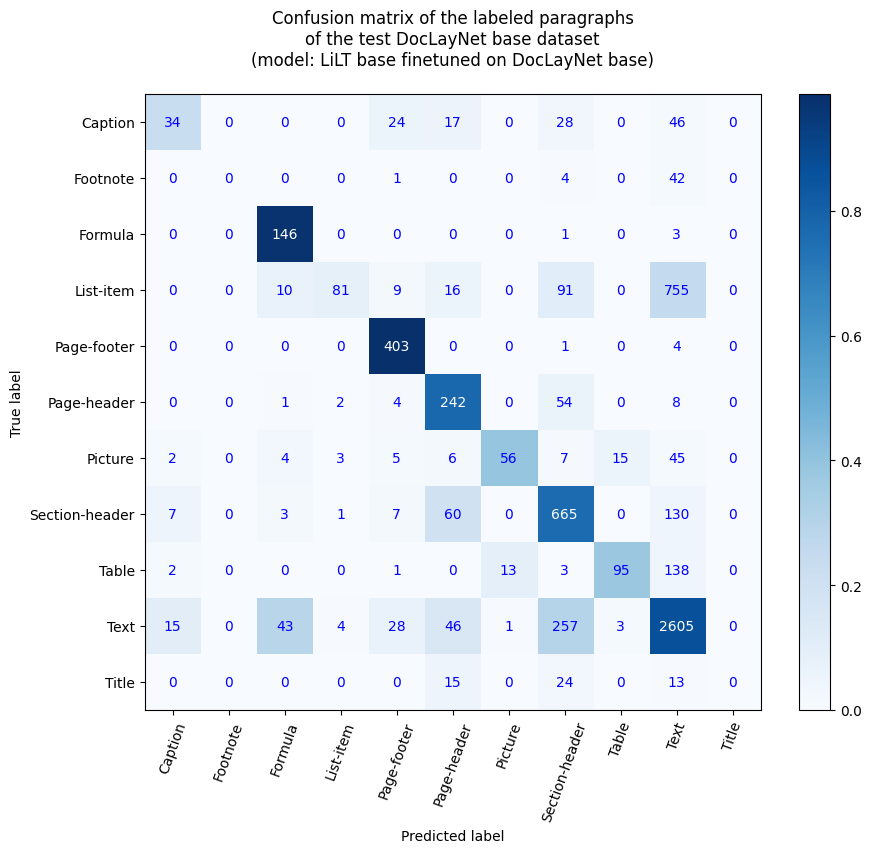
評価セットでの結果
- 損失: 0.4104
- 適合率: 0.8634
- 再現率: 0.8634
- F1値: 0.8634
- トークン精度: 0.8634
- 段落精度: 0.6815
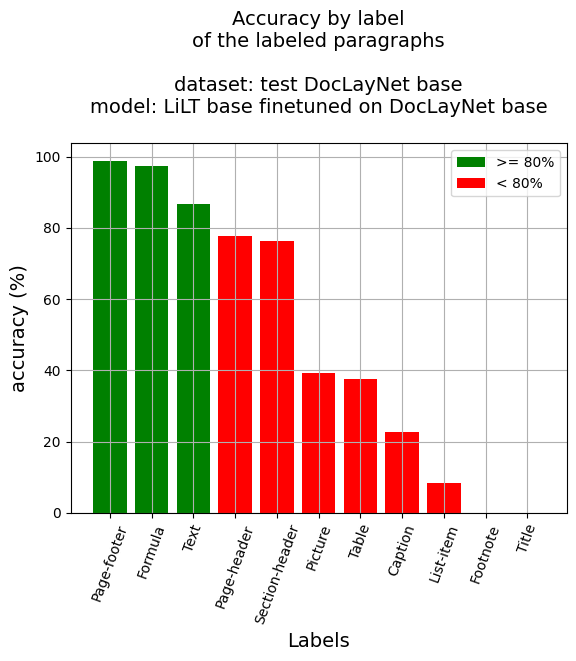
段落レベルでの精度
- 段落精度: 68.15%
- ラベル別精度
- キャプション: 22.82%
- 脚注: 0.0%
- 数式: 97.33%
- リスト項目: 8.42%
- ページフッター: 98.77%
- ページヘッダー: 77.81%
- 画像: 39.16%
- セクションヘッダー: 76.17%
- 表: 37.7%
- テキスト: 86.78%
- タイトル: 0.0%
✨ 主な機能
- 文書の段落レベルでのレイアウトセグメンテーションを行います。
- 複数の言語に対応しており、多言語文書の解析が可能です。
- 高精度なトークン分類と段落精度を実現しています。
📚 ドキュメント
参考文献
ブログ記事
- Layout XLM base
- LiLT base
ノートブック (段落レベル)
ノートブック (行レベル)
- Layout XLM base
- LiLT base
アプリケーション
このモデルは、Hugging Face Spacesの以下のアプリでテストできます。
Inference APP for Document Understanding at paragraph level (v1)
また、対応するノートブックも実行できます。
Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
DocLayNetデータセット
DocLayNetデータセット (IBM) は、6つの文書カテゴリの80863ページのユニークなページに対して、11種類のクラスラベルのバウンディングボックスを使用したページ単位のレイアウトセグメンテーションの正解データを提供します。
現在、このデータセットは直接リンクまたはHugging Faceのデータセットライブラリからダウンロードできます。
論文: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (2022年06月02日)
モデルの説明
このモデルは、512トークンのチャンクで128トークンのオーバーラップを持つ段落レベルで微調整されています。したがって、モデルはデータセットのすべてのページのレイアウトとテキストデータを使用してトレーニングされています。
推論時には、最適な確率の計算により、各段落のバウンディングボックスにラベルが付けられます。
推論
ノートブックを参照してください。
Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
トレーニングと評価データ
ノートブックを参照してください。
Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
トレーニング手順
トレーニングハイパーパラメータ
トレーニング中に以下のハイパーパラメータが使用されました。
- 学習率: 2e-05
- トレーニングバッチサイズ: 8
- 評価バッチサイズ: 16
- シード: 42
- オプティマイザ: Adam (betas=(0.9,0.999), epsilon=1e-08)
- 学習率スケジューラタイプ: 線形
- エポック数: 1
- 混合精度トレーニング: Native AMP
トレーニング結果
| トレーニング損失 |
エポック |
ステップ |
検証損失 |
適合率 |
再現率 |
F1値 |
精度 |
| ログなし |
0.05 |
100 |
0.9875 |
0.6585 |
0.6585 |
0.6585 |
0.6585 |
| ログなし |
0.11 |
200 |
0.7886 |
0.7551 |
0.7551 |
0.7551 |
0.7551 |
| ログなし |
0.16 |
300 |
0.5894 |
0.8248 |
0.8248 |
0.8248 |
0.8248 |
| ログなし |
0.21 |
400 |
0.4794 |
0.8396 |
0.8396 |
0.8396 |
0.8396 |
| 0.7446 |
0.27 |
500 |
0.3993 |
0.8703 |
0.8703 |
0.8703 |
0.8703 |
| 0.7446 |
0.32 |
600 |
0.3631 |
0.8857 |
0.8857 |
0.8857 |
0.8857 |
| 0.7446 |
0.37 |
700 |
0.4096 |
0.8630 |
0.8630 |
0.8630 |
0.8630 |
| 0.7446 |
0.43 |
800 |
0.4492 |
0.8528 |
0.8528 |
0.8528 |
0.8528 |
| 0.7446 |
0.48 |
900 |
0.3839 |
0.8834 |
0.8834 |
0.8834 |
0.8834 |
| 0.4464 |
0.53 |
1000 |
0.4365 |
0.8498 |
0.8498 |
0.8498 |
0.8498 |
| 0.4464 |
0.59 |
1100 |
0.3616 |
0.8812 |
0.8812 |
0.8812 |
0.8812 |
| 0.4464 |
0.64 |
1200 |
0.3949 |
0.8796 |
0.8796 |
0.8796 |
0.8796 |
| 0.4464 |
0.69 |
1300 |
0.4184 |
0.8613 |
0.8613 |
0.8613 |
0.8613 |
| 0.4464 |
0.75 |
1400 |
0.4130 |
0.8743 |
0.8743 |
0.8743 |
0.8743 |
| 0.3672 |
0.8 |
1500 |
0.4535 |
0.8289 |
0.8289 |
0.8289 |
0.8289 |
| 0.3672 |
0.85 |
1600 |
0.3681 |
0.8713 |
0.8713 |
0.8713 |
0.8713 |
| 0.3672 |
0.91 |
1700 |
0.3446 |
0.8857 |
0.8857 |
0.8857 |
0.8857 |
| 0.3672 |
0.96 |
1800 |
0.4104 |
0.8634 |
0.8634 |
0.8634 |
0.8634 |
フレームワークバージョン
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
その他のモデル
行レベル
段落レベル
📄 ライセンス
このモデルはMITライセンスの下で提供されています。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
 Safetensors
Safetensors Transformers 複数言語対応
Transformers 複数言語対応